 一种全新的基于旋转的框架,能对自然场景中任意方向的文字进行检测辨认
一种全新的基于旋转的框架,能对自然场景中任意方向的文字进行检测辨认

编者按:对图像中的文字进行识别已经有很多种方法了,但是大多是水平方向上的识别,一旦有了旋转角度,这些方法可能就“失灵”了。来自复旦大学和中国科学院的几位研究人员就提出了一种框架,可以识别图像中经过旋转的文本。以下为论智对论文的编译。
摘要
本文介绍了一种全新的基于旋转的框架,能对自然场景中任意方向的文字进行检测辨认。我们提出了Rotation Region Proposal Networks(RRPN),用于生成倾斜的框架,同时还带有图像旋转角度的信息。之后,这些信息会适应边界框,从而能更精确地在不同方向上确定文本区域。Rotation Region-of-Interest(RRoI)池化层是将随机方向的候选窗口映射到文本区域分类器的特征映射上。
整个框架是基于区域候选框的结构上搭建的,它与之前的文本检测系统相比,能保证在随机方向的文本检测上有更高的计算效率。我们在三种现实场景中对该框架进行了实验,发现了相较于之前的方法它所表现出的效率。
背景介绍
文本检测是CV领域一大热门话题,它的目标是在给定图像中定位文字区域,这项任务是很多复杂任务的前提,例如视觉分类、视频分析和其他移动应用。虽然已有很多商业产品落地,但是由于场景的复杂性,自然场景下的文字识别仍然受到很多限制,例如光线不均、图片模糊、角度扭曲、方向不同等等。而本文正是关注现实生活中不水平的文字区域。
最近一些研究提出了针对随机方向文本的检测方法,总的来说,这些方法大致包括两个步骤:分割网络(全卷积网络)以及用于倾斜候选框的几何方法。然而,对图像进行分割通常很耗时,并且一些系统需要多次后处理才能生成最终的文本区域候选框,所以并不如直接的检测网络高效。
在这篇论文中,我们提出了一种基于旋转的方法,和端到端的文本检测系统,该系统能生成任意方向的候选框。相较于之前的方法,我们的主要成果有:
这次的框架可以用基于候选框区域的方法预测文本线的方向,使候选框能更好地适应文本区域。框架中加入的新元素,例如RRoI池化层和旋转的候选框都整合到了架构中,保证高效的计算力。
我们还提出了对候选框区域新型的微调方法,提高任意方向文本检测的性能。
我们将新的框架应用到三种场景数据集上,发现它比此前的方法更精确、更高效。
具体框架
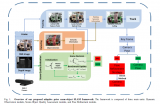
首先,框架的整体结构如下图所示:
框架的前部是VGG-16的卷积层,其中由两部分组成:RRPN和最后一个卷积层的特征映射的复制品。RRPN可以为文本样本生成随机方向的候选框,之后会对候选框进行回归处理以更好地适应文本区域。而从RRPN分出去的两个图层是分类层(cls)和回归层(reg)。
cls的分数和reg中的候选框信息组成了两个图层的输出结果,并且他们的损失通过计算总结构会形成一个多任务的损失函数。之后,RRoI池化层会扮演一个最大池化层的角色,将RRPN上任意方向的文本候选框投射到特征映射上。
最后,两个全卷积层结合成一个分类器,具有RRoI特征的区域被分为文本或者背景。
在训练阶段,真实的文本区域用五个元组表示旋转后的边界框,分别是(x, y, h, w, θ),(x, y)代表边界框几何中心的坐标,h和w分别代表边界框较短和较长的两边,θ表示夹角。
旋转连接点(anchors)
传统的连接点利用比例尺和长宽比参数表示,通常对现实中的文本检测并不有效。所以我们通过调整设计了旋转连接点(R-anchors)。具体表示可看下图:
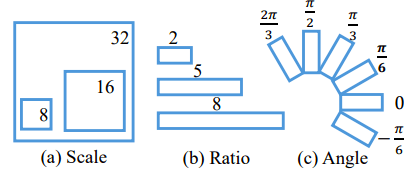
其中有六个不同的旋转方向,是综合考虑覆盖和计算效率之后得出的结果。其次,由于文本区域经常有特殊的形状,长宽比改成了1:2、1:5、1:8,以覆盖更宽的文本。
学习旋转候选框
R-anchors生成后,为了执行网络学习,就需要对R-anchors进行采样。候选框的损失函数形成了多任务损失,定义为:
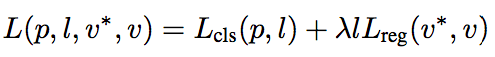
其中l是类别标签的表示器,参数p时softmax函数计算出的类别概率,v表示文本标签的预测元组,v*表示真实数值。
下图可以看到经过回归后的图像与未回归的对比:
(a)是输入的图像,(b)是没有经过回归处理的方向和连接点,(c)是经过处理的点
白线的方向就表示R-anchors的方向,白线的长短表示连接点对文字的反馈。
下图是不同多任务损失值的对比:
实验效果
我们分别在三个数据集上进行了实验:MSRA-TD500、ICDAR2015和ICDAR2013。三个数据集都是文本检测常用的数据集。首先我们对比了旋转和水平的候选框:
结果显示,基于旋转的方法能更精确地确定文字区域,不会包含太多的背景,这说明在框架中加入旋转策略的有效性。但是虽然检测效率有所提高,在MSRA-TD500中仍有检测失败的案例:
在不平衡的光线下(a)、非常小的字体上(b)以及过长的文本上(c)都会出现检测失败的情况
但最终在三种数据集上的表现还是很不错的:
-
图像
+关注
关注
2文章
1096浏览量
42437 -
分类器
+关注
关注
0文章
153浏览量
13836 -
数据集
+关注
关注
4文章
1240浏览量
26261
原文标题:复旦&中科院成果:对任意方向的文字进行识别
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
瑞芯微(EASY EAI)RV1126B OCR文字识别

一种基于图像平移的目标检测框架
如何对运动中的车轮进行测定
一种名片图像的文字区块分割方法
一种改进的CAMShift跟踪算法及人脸检测框架
一种新型分割图像中人物的方法,基于人物动作辨认

如何提取和检测视频中的文字?数字视频中文字的检测提取技术的分析
一种硅片旋转甩干装置,它的应用优势是什么
如何对typo 进行检测和纠正
一种基于HOG+SVM的行人检测算法
OpenVINO场景文字检测与文字识别教程

一种利用几何信息的自监督单目深度估计框架
一种适用于动态环境的自适应先验场景-对象SLAM框架



评论