 继OpenAI发布Dota2的团战AI后,DeepMind今天也发布了自家的最新研究
继OpenAI发布Dota2的团战AI后,DeepMind今天也发布了自家的最新研究
编者按:继OpenAI发布Dota2的团战AI后,DeepMind今天也发布了自家的最新研究,一些可以互相协作,也可以和人类选手合作的人工智能机器人。以下是论智对DeepMind博文的编译。
在游戏项目中,让AI掌握策略、理解战术并进行团队合作是非常重要的。现在的强化学习经过发展,我们的智能体在《雷神之锤III:竞技场》的夺旗比赛(Capture the Flag)中的表现达到了人类水平,它们在团队合作方面展示出了较高水准。
《雷神之锤III:竞技场》的夺旗模式(CTF)是一款以第一人称视角展示的多人游戏,参赛者分成两组,红队和蓝队。每组队员的目标是夺取对方的旗帜并将它带回自己的基地,同时保护己方旗帜。杀死对手得1分,自己非正常死亡扣1分,夺取对方旗子得3分,杀死夺旗者得2分,重新拿到己方旗子得1分,成功夺取一次旗子(将旗子送回己方基地)得5分。五分钟内有较多旗子的一方获胜。
我们训练的四个智能体在室内和室外两种环境下进行对战,并逐渐修炼到能够夺旗的水平
对人类来说,每个个体都有自己的目标和行动方式,但我们仍然能在团队和组织中展示出集体智慧,我们将这一设置称为“多智能体学习”:多个智能体必须独立行动,但是要学习与其他智能体交互合作。这个问题非常困难,因为环境是在不断变化的。
为了研究这一问题,我们以各类3D第一人称视角的电子游戏为研究对象,它们代表了大多数游戏的形式,能反映各类玩家的策略,因为其中包括了他们对游戏的理解、手眼配合以及团队计划。我们的智能体所面临的挑战是直接从原始像素中学习,从而输出动作。
实验中我们选用的《雷神之锤III:竞技场》游戏是现在许多第一人称角色游戏的基础,我们训练智能体像单人一样学习和行动,但是仍要在团队间进行合作,共同对抗敌方。
从一个多智能体的角度,CTF需要玩家既能和队友完美合作,也要与敌人对抗,不论在什么风格下都要保持水平的稳定。
为了让这一过程更有趣,我们还设计了一个CTF的变体,其中的平面地图每一场都不一样。结果我们的智能体被迫学习到了一种“通用策略”,而非靠对地图的记忆获胜。除此之外,为了评估游戏场地,我们的智能体用人类的方式感受了一下CTF的环境:它们通过一个虚拟游戏控制器观察一连串的像素图像和动作。
CTF的环境不断更新,所以智能体必须适应陌生地图
我们的智能体必须从零开始学习在陌生环境中如何观察地形、行动、合作、竞争,这一切都要从每场比赛的单一强化信号中得来:不论它们所在队伍是否获胜。这是一个具有挑战性的学习问题,而解决方法基于三个强化学习的基本问题:
与训练单一智能体相反,我们训练的是多个智能体,它们通过与各种队友和对手的互动来学习。
团队里的每个智能体都从它自己的内部奖励信号中学习,从而让智能体生成自己内部的目标,例如获得一面旗帜。两阶段的优化过程优化了智能体内部的奖励,同时用内部奖励的强化学习学习了智能体的策略。
智能体会在快慢两种速度下进行训练,这样会提高他们利用内存并生成连续动作的能力。
最终训练出的智能体(FTW)在玩CTF上表现出了很高的水准。重要的是,该智能体在各种地图、队员数量的情况下,表现得都很稳定。不论是在户外模式还是室内模式,或者有人类参与的比赛中,FTW都表现的很好。
我们组织了一场联赛,其中有40名人类玩家,将人类和智能体随机组合分配到游戏中。
FTW智能体学习之后比基准的方法更强大,同时超过了人类选手的取胜率。事实上,在对参赛者的评估上,智能体的合作能力比人类更强。

智能体在训练时的表现与人类的对比
理解智能体的内部机制
为了了解智能体是如何表示游戏状态的,我们查看了智能体神经网络的活动形式。下面的图表展示了游戏过程中的情形,其中密密麻麻的点根据CTF在游戏中的状态分成不同的颜色,根据颜色可以判断:智能体在哪个房间?旗子的状态如何?能看到哪个队友或对手?通过观察颜色相同的点,我们发现在相似状态的智能体动作也相似。

各色点点代表游戏中各种智能体所处的状态和位置
我们不会告诉智能体游戏的规则,而是让他们自己学习基础概念。事实上,我们可以找到具体编码有重要游戏状态的神经元,比如当旗子被夺走时活动的神经元,或者队友拿到旗时活动的神经元。想知道更多智能体细节,可查看原论文。
除了这些多样的表示,智能体实际上是怎样运作的?首先,我们注意到智能体的反应时间很快,并且还有精确的标记器。但是当人为地降低他们的精度和反应时间,我们看到导致成功的只有一个因素。
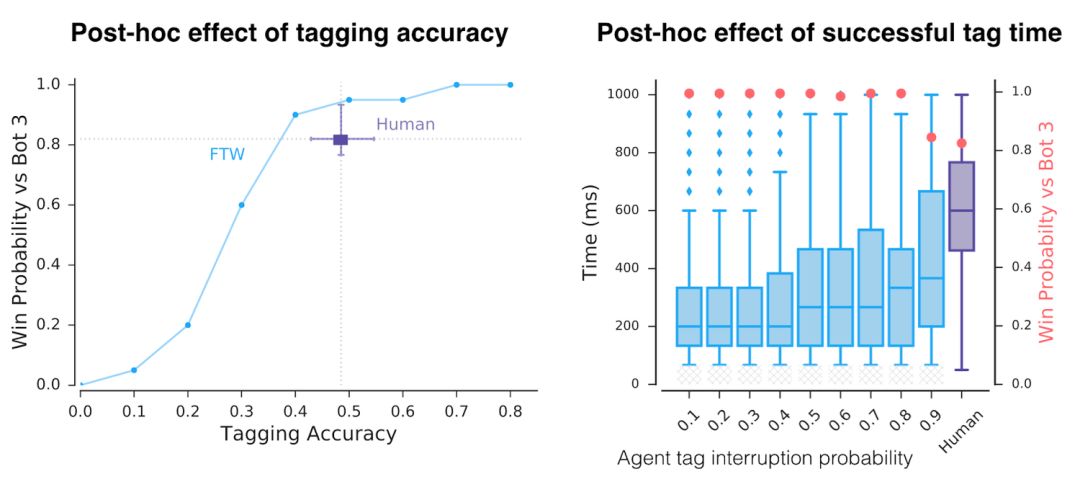
智能体的精确度和反应时间比人类要高
通过无监督学习我们创建了智能体的原始动作,发现智能体实际上是在模仿人类行为,例如跟随队友或者在对手的基地“安营扎寨”。这些动作都是在训练中通过强化学习和进化得来的。

结语
最近人工智能在星际争霸II和Dota 2这样复杂的游戏中都取得了不小的进步,虽然这一项目的侧重点在于“夺旗”游戏,但是做出的贡献是通用的,研究人员表示,他们很高兴看到其他研究者在不同环境中应用这一技术。在未来,他们将对目前的强化学习和基于多个智能体的训练方法进行改进。总的来说,这项工作突出了多智能体训练的潜力,有助于它们与人类的合作。
-
机器人
+关注
关注
210文章
28189浏览量
206454 -
智能体
+关注
关注
1文章
131浏览量
10567 -
DeepMind
+关注
关注
0文章
129浏览量
10818
原文标题:不论队友是机器人还是人类,DeepMind智能体学会了复杂合作
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论