 如何才能高效地进行深度学习模型训练?
如何才能高效地进行深度学习模型训练?
近年来,深度学习在NLP、图像识别、语音识别、机器翻译等方面都取得了惊人的成果。但是,深度学习的应用范围却日益受到数据量和模型规模的限制。如何才能高效地进行深度学习模型训练?微软亚洲研究院机器学习组主管研究员陈薇和她的团队基于对机器学习的完整理解,将分布式技术和深度学习紧密结合在一起,探索全新的真正合二为一“分布式深度学习”算法。
随着大数据和高效计算资源的出现,深度学习在人工智能的很多领域中都取得了重大突破。然而,面对越来越复杂的任务,数据和深度学习模型的规模都变得日益庞大。例如,用来训练图像分类器的有标签的图像数据量达数百万、甚至上千万张。大规模训练数据的出现为训练大模型提供了物质基础,因此近年来涌现出了很多大规模的机器学习模型,例如2015年微软亚洲研究院开发出的拥有超过两百亿个参数的LightLDA主题模型。然而,当训练数据词表增大到成百上千万时,如果不做任何剪枝处理,深度学习模型可能会拥有上百亿、甚至是几千亿个参数。
为了提高深度学习模型的训练效率,减少训练时间,我们普遍会采用分布式技术来执行训练任务——同时利用多个工作节点,分布式地、高效地训练出性能优良的神经网络模型。分布式技术是深度学习技术的加速器,能够显著提高深度学习的训练效率、进一步增大其应用范围。
深度学习的目标是从数据中挖掘出规律,帮助我们进行预测。深度学习算法的一般框架是,利用优化算法迭代地最小化训练数据上的经验风险。由于数据的统计性质、优化的收敛性质、以及学习的泛化性质在多机执行时的灵活度更高,相比于其它的计算任务,深度学习算法在并行化执行过程中实际上并不需要计算节点通过通信严格地执行单机版本算法。因而,当“分布式”遇到“深度学习”,不应只局限在对串行算法进行多机实现以及底层实现方面的技术,我们更应该基于对机器学习的完整理解,将分布式和深度学习紧密结合在一起,结合深度学习的特点,设计全新的真正合二为一的“分布式深度学习”算法。
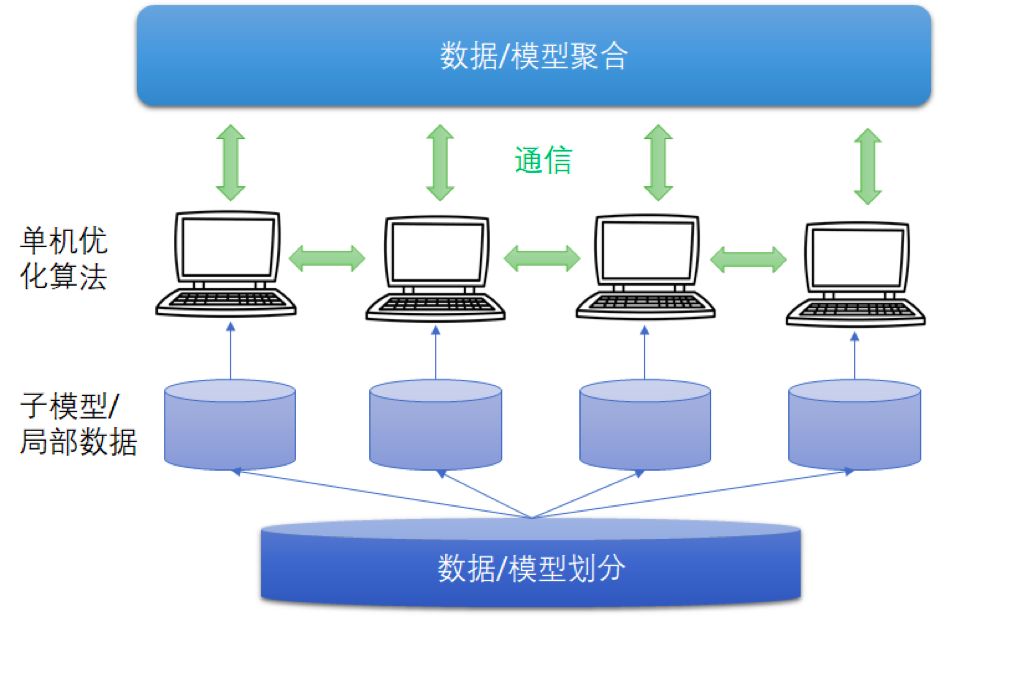
图1 分布式深度学习框架
分布式深度学习框架中,包括数据/模型切分、本地单机优化算法训练、通信机制、和数据/模型聚合等模块。现有的算法一般采用随机置乱切分的数据分配方式,随机优化算法(例如随机梯度法)的本地训练算法,同步或者异步通信机制,以及参数平均的模型聚合方式。
结合深度学习算法的特点,微软亚洲研究院机器学习组重新设计/理解了这些模块,我们在分布式深度学习领域主要做了三个方面的工作:第一个工作,针对异步机制中的梯度延迟问题,我们为深度学习设计了“带有延迟补偿的异步算法”;第二个工作,注意到神经网络的非凸性质,我们提出了比参数平均更加有效的集成聚合方式,并设计了“集成-压缩”并行深度学习算法;第三个工作,我们首次分析了随机置乱切分方式下分布式深度学习算法的收敛速率,为算法设计提供了理论指导。
DC-ASGD算法:补偿异步通信中梯度的延迟
随机梯度下降法(SGD)是目前最流行的深度学习的优化算法之一,更新公式为:
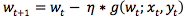
公式 1
其中,wt为当前模型,(xt, yt)为随机抽取的数据,g(wt; xt, yt)为(xt, yt)所对应的经验损失函数关于当前模型wt的梯度,η为步长/学习率。
假设系统中有多个工作节点并行地利用随机梯度法优化神经网络模型,同步和异步是两种常用的通信同步机制。
同步随机梯度下降法(Synchronous SGD)在优化的每轮迭代中,会等待所有的计算节点完成梯度计算,然后将每个工作节点上计算的随机梯度进行汇总、平均并按照公式1更新模型。之后,工作节点接收更新之后的模型,并进入下一轮迭代。由于Sync SGD要等待所有的计算节点完成梯度计算,因此好比木桶效应,Sync SGD的计算速度会被运算效率最低的工作节点所拖累。
异步随机梯度下降法(Asynchronous SGD)在每轮迭代中,每个工作节点在计算出随机梯度后直接更新到模型上,不再等待所有的计算节点完成梯度计算。因此,异步随机梯度下降法的迭代速度较快,也被广泛应用到深度神经网络的训练中。然而,Async SGD虽然快,但是用以更新模型的梯度是有延迟的,会对算法的精度带来影响。什么是“延迟梯度”?我们来看下图。
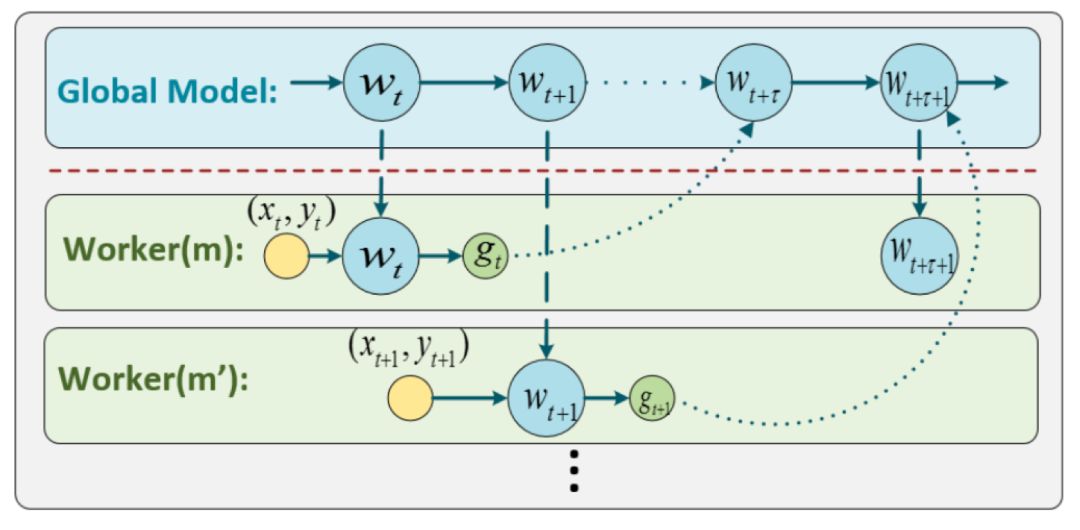
图2 异步随机梯度下降法
在Async SGD运行过程中,某个工作节点Worker(m)在第t次迭代开始时获取到模型的最新参数wt和数据(xt, yt),计算出相应的随机梯度gt,并将其返回并更新到全局模型w上。由于计算梯度需要一定的时间,当这个工作节点传回随机梯度gt时,模型wt已经被其他工作节点更新了τ轮,变为了wt+τ。也就是说,Async SGD的更新公式为:
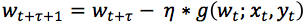
公式 2
对比公式1,公式2中对模型wt+τ上更新时所使用的随机梯度是g(wt; xt, yt),相比SGD中应该使用的随机梯度g(wt+τ; xt+τ, yt+τ)产生了τ步的延迟。因而,我们称Async SGD中随机梯度为“延迟梯度”。
延迟梯度所带来的最大问题是,由于每次用以更新模型的梯度并非是正确的梯度(请注意g(wt; xt, yt) ≠ g(wt+τ; xt+τ, yt+τ)),所以导致Async SGD会损伤模型的准确率,并且这种现象随着机器数量的增加会越来越严重。如下图所示,随着计算节点数目的增加,Async SGD的精度逐渐变差。
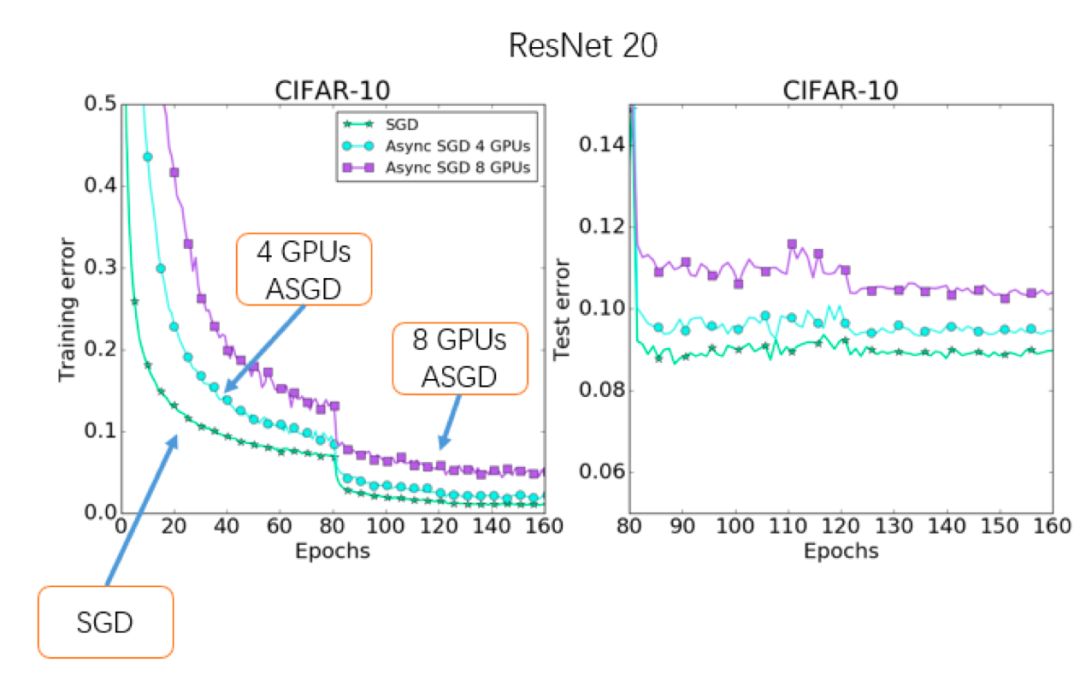
图3 异步随机梯度下降法的性能
那么,如何能让异步随机梯度下降法在保持训练速度的同时,获得更高的精度呢?我们设计了可以补偿梯度延迟的DC-ASGD(Delay-compensated Async SGD)算法。
为了研究正确梯度g(wt+τ)和延迟梯度g(wt)之间的关系,我们将g(wt+τ)在wt处进行泰勒展开:
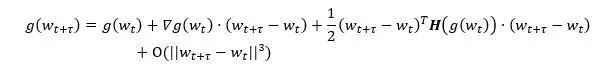
其中,∇g(wt)为梯度的梯度,也就是损失函数的Hessian矩阵,H(g(wt))为梯度的Hessian矩阵。显然,延迟梯度实则为真实梯度的零阶近似,而其余各项造成了延迟。于是,一个自然的想法是,如果我们将所有的高阶项都计算出来,就可以修正延迟梯度为准确梯度了。然而,由于余项拥有无穷项,所以无法被准确计算。因此,我们选择用上述公式中的一阶项进行延迟补偿:
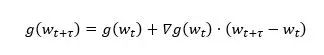
众所周知,在现代的深度神经网络模型中有上百万甚至更多的参数,计算和存储Hessian矩阵∇g(wt)成为了一件几乎无法完成的事情。因此,寻找Hessian矩阵的一个良好近似是能否补偿梯度延迟的关键。根据费舍尔信息矩阵的定义,梯度的外积矩阵
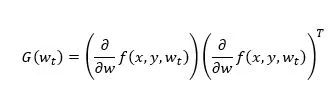
是Hessian矩阵的一个渐近无偏估计,因此我们选择用G(wt)来近似估计Hessian矩阵。根据前人的研究,如果在神经网络模型中用Hessian矩阵的对角元来近似Hessian矩阵,在显著降低运算和存储复杂度的同事还可以保持算法精度,于是我们采用diag(G(wt))作为Hessian矩阵的近似。为了进一步降低近似的方差,我们使用一个(0,1]之间参数λ来对偏差和方差进行调节。综上,我们设计了如下带有延迟补偿的异步随机梯度下降法(DC-ASGD),
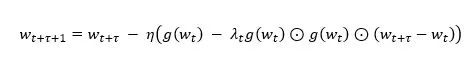
其中,对延迟梯度g(wt)的补偿项中只包含一阶梯度信息,几乎不增加计算和存储代价。
我们在CIFAR10数据集和ImageNet数据集上对DC-ASGD算法进行了评估,实验结果见以下两图。
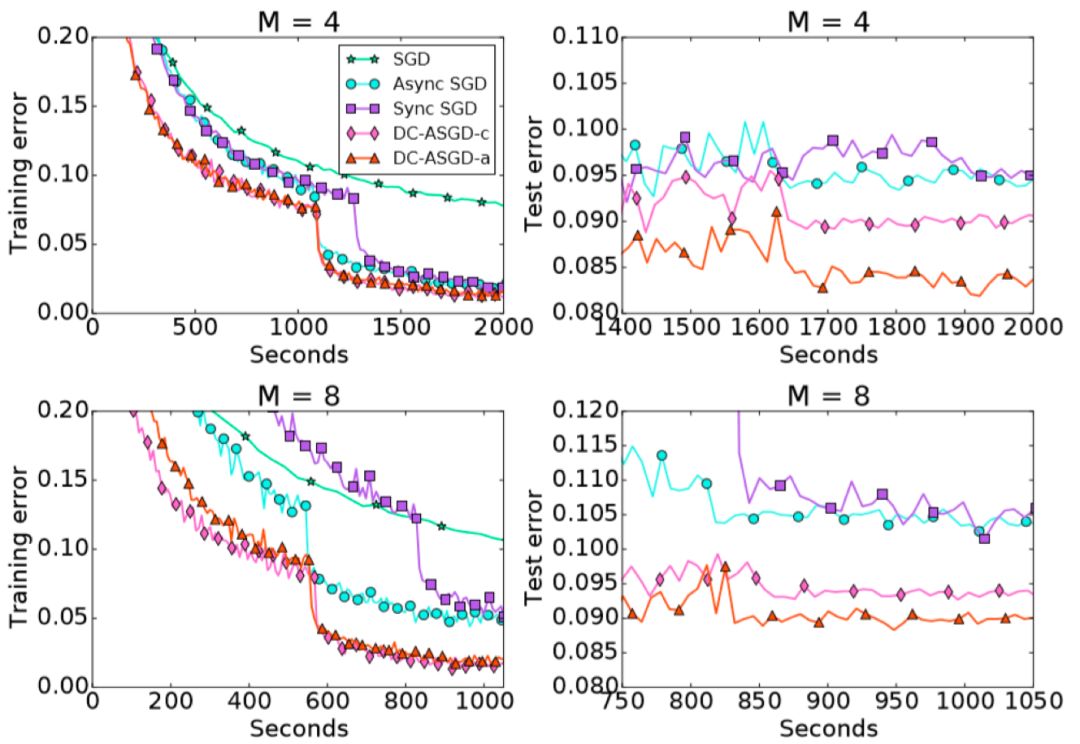
图4 DC-ASGD的训练/测试误差_CIFAR-10
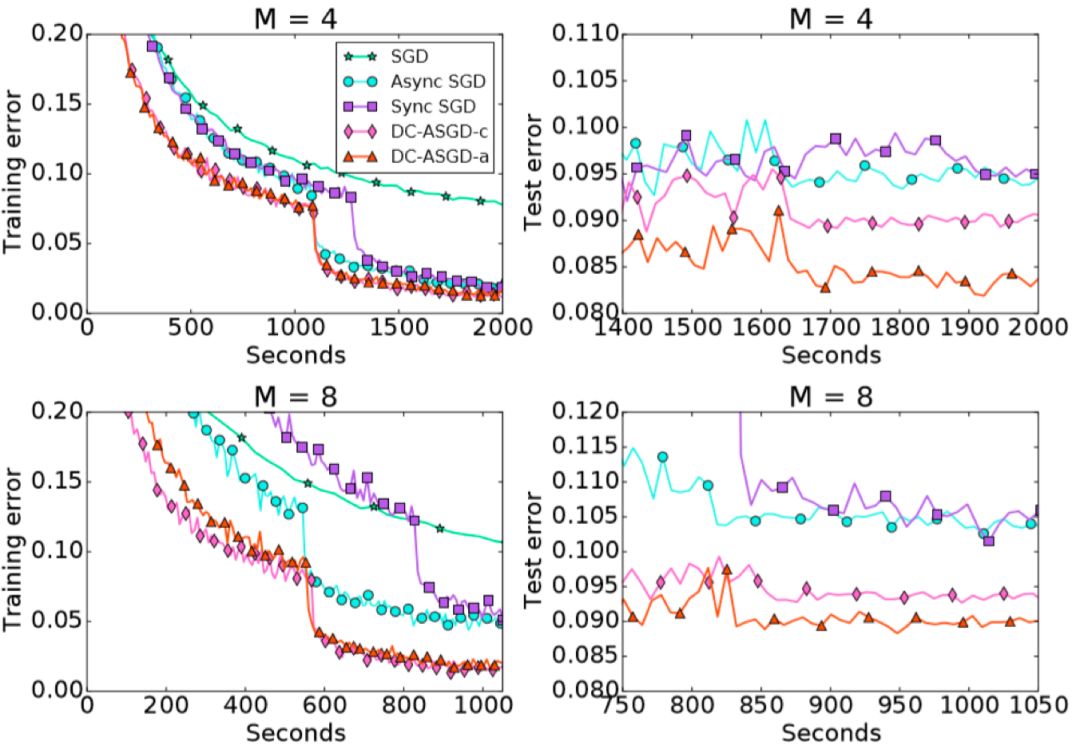
图5 DC-ASGD的训练/测试误差_ImageNet
可以观察到,DC-ASGD算法与Async SGD算法相比,在相同的时间内获得的模型准确率有显著的提升,并且也高于Sync SGD,基本可以达到SGD相同的模型准确率。
Ensemble-Compression算法:改进非凸模型的聚合方法
参数平均是现有的分布式深度学习算法中非常普遍的模型聚合方法。如果损失函数关于模型参数是凸的,以下不等式成立:
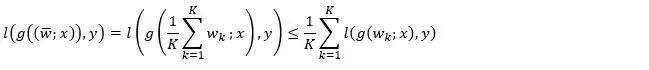
其中,K为计算节点个数,wk是局部模型,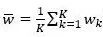 为参数平均后的模型,(x, y)为任意样本数据。该不等式的左端是平均模型所对应的损失函数,右端是各个局部模型的损失函数值的平均值。可见,凸问题中参数平均可以保持模型的性能。
为参数平均后的模型,(x, y)为任意样本数据。该不等式的左端是平均模型所对应的损失函数,右端是各个局部模型的损失函数值的平均值。可见,凸问题中参数平均可以保持模型的性能。
但是,对于非凸的神经网络模型,以上不等式将不再成立,因而平均模型的性能不再具有保证。这一点在实验上也得到了验证:如图6所示,对于不同的交互频率(尤其是较低频的交互),参数平均通常会大幅度拉低训练精度,使得训练的过程极不稳定。
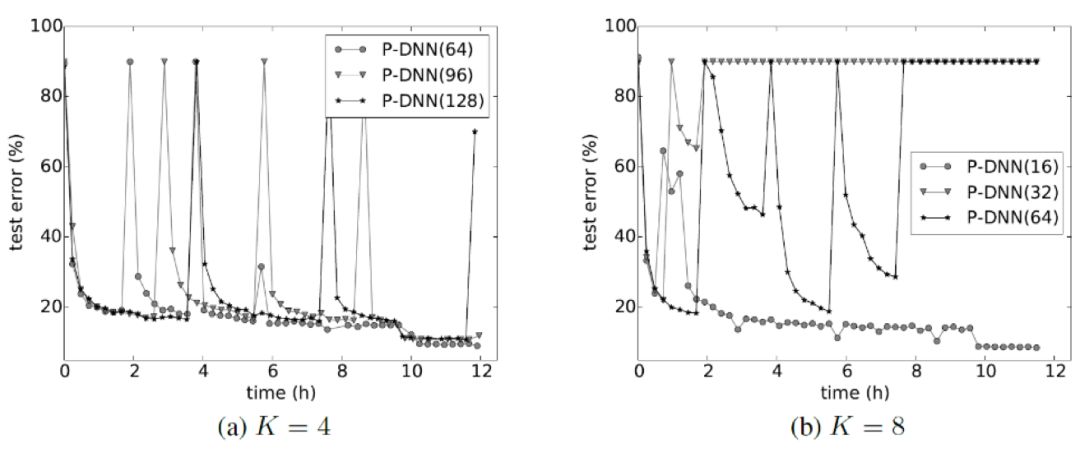
图6 基于参数平均的分布式算法训练曲线(DNN模型)
为了解决这个问题,我们提出用模型集成替代模型平均,作为分布式深度学习中的模型聚合方式。虽然神经网络的损失函数关于模型参数是非凸的,但是关于模型的输出一般是凸的(比如深度学习中常用的交叉熵损失)。这时,利用凸性可以得到如下不等式:
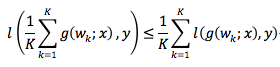
其中,不等式左侧是集成(ensemble)模型的损失函数取值。可见,对于非凸模型,集成模型可以保持性能。
然而,每经过一次集成,神经网络模型的规模就会增加倍,从而出现模型规模爆炸的问题。那么,有没有一种既能利用模型集成的优点,又能避免增大模型的方法呢?我们提出了一种同时基于模型集成和模型压缩的模型聚合方法, 即集成-压缩(ensemble-compression)方法。在每次集成之后,我们对集成所得的模型进行一次压缩。
算法具体分为三个步骤:
各个计算节点依照本地优化算法训练和局部数据训练出局部模型;
计算节点之间相互通信局部模型得到集成模型,并对(一部分)局部数据标注上集成模型对它们的输出值;
利用模型压缩技术(比如知识蒸馏),结合数据的再标注信息,在每个工作节点上分别进行模型压缩,获得与局部模型大小相同的新模型作为最终的聚合模型。为了进一步节省计算量,可以将蒸馏的过程和本地模型训练的过程结合在一起。
这种集成-压缩的聚合方法,既可以通过集成获得性能提升,又可以在学习的迭代过程中保持全局模型的规模。CIFA-10和ImageNet上的实验结果也很好地验证了集成-压缩聚合方法的有效性(见图7和图8)。当工作节点之间相互通信的频率较低时,参数平均方法表现会很差,但模型集成-压缩的方法却依然能取得理想的效果。这是因为集成学习在子模型具有多样性时效果更好,而较低的通信频率会导致各个局部模型更加分散,多样性更强;同时,较低的通信频率意味着较低的通信代价。因此,模型集成-压缩的方法更适用于网络环境比较差的场景。
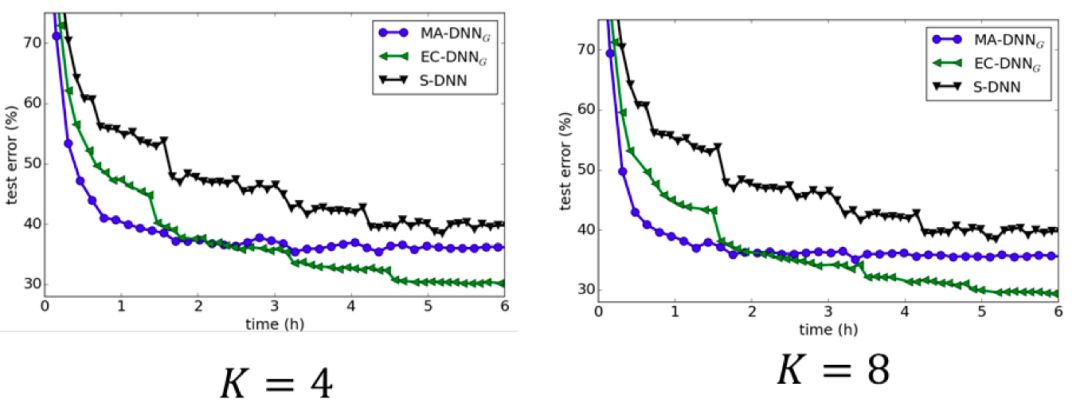
图7 CIFAR数据集上对比各种分布式算法
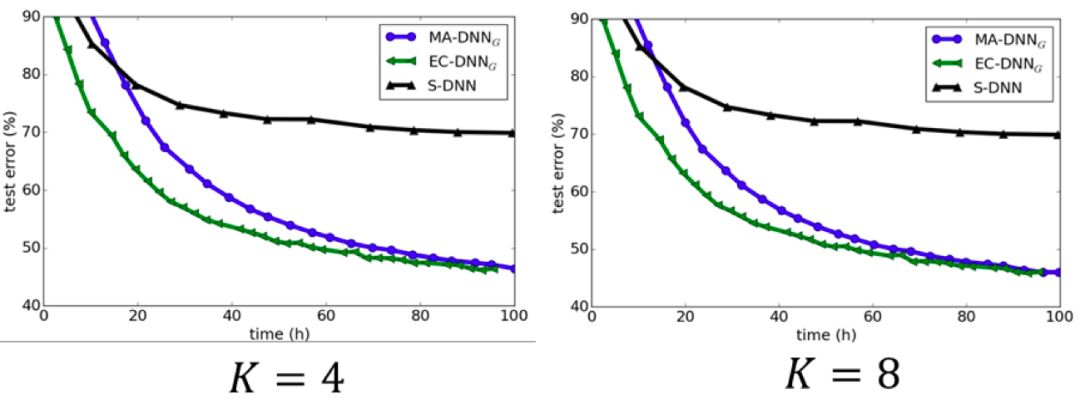
图8 ImageNet数据集上对比各种分布式算法
基于模型集成的分布式算法是一个比较新的研究领域,还存在很多没有解决的问题。比如说当工作节点非常多的时候或者本地模型本身就很大的时候,集成模型的规模会变得非常大,这会带来较大的网络开销。另外,当集成模型较大时,模型压缩也会变成一个较大的开销。值得注意的是,在ICLR 2018上,Hinton等人提出的Co-distillation方法,尽管在动机上和这个工作不同,但是其算法和这个工作非常相似。如何理解这些关联和解决这些局限性将催生新的研究,感兴趣的读者可以对此进行思考。
随机重排下算法的收敛性分析:改进分布式深度学习理论
最后,简单介绍一个我们最近在改进分布式深度学习理论方面的工作。
分布式深度学习中常用的数据分配策略是随机重排之后均等切分。具体来说,是将所有训练数据随机地打乱顺序,得到数据的一个重排列,然后将数据集按顺序等分,并将每一份存放在计算节点上。在数据被过完一轮后,如果收集所有的局部数据并重复上述过程,一般被称为“全局重排”,如果只是对局部数据进行随机重排,一般被称为“局部重排”。
现有的绝大部分分布式深度学习理论中都假定数据是独立同分布的。然而,基于Fisher-Yates算法的随机重排实际上与无放回抽样等价,训练数据之间不再是独立同分布的了。于是,每一轮所计算的随机梯度也不再是精确梯度的无偏估计,所以以往分布式随机优化算法的理论分析方法不再适用,已有的收敛性结果也不一定仍然成立。
我们利用Transductive Rademancher Complexity作为工具,给出了随机梯度相对于精确梯度的偏差上界,证明了随机重排下分布式深度学习算法的收敛性分析。
假设目标函数光滑(不一定是凸函数),系统中有K个计算节点,训练轮数(epoch)为S,总训练数据有n个,考虑分布式SGD算法。
(1)如果采用全局随机重排数据分配策略,算法的收敛速率为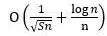 ,其中非i.i.d.性质带来的额外误差为
,其中非i.i.d.性质带来的额外误差为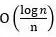 。因此,当过数据的轮数远远小于训练样本数目时(S ≪n),额外误差的影响可以忽略。考虑到现有的分布式深度学习任务中,S ≪n是很容易满足的,所以全局随机重排不会影响分布式算法的收敛速率。
。因此,当过数据的轮数远远小于训练样本数目时(S ≪n),额外误差的影响可以忽略。考虑到现有的分布式深度学习任务中,S ≪n是很容易满足的,所以全局随机重排不会影响分布式算法的收敛速率。
(2)如果采用局部重排策略数据分配策略,算法的收敛速率为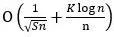 ,其中非i.i.d.性质带来的更大的额外误差
,其中非i.i.d.性质带来的更大的额外误差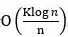 。原因是,由于随机重排是本地局部进行的,不同计算节点之间的数据没有进行交互,数据的差异性更大,随机梯度的偏差也更大。当过数据的轮数S≪n/K2时,额外误差的影响可以忽略。也就是说,使用局部重排数据分配策略时,算法中过数据的轮数要收到计算节点数目的影响。如果计算节点数比较多,过的轮数不能太大。
。原因是,由于随机重排是本地局部进行的,不同计算节点之间的数据没有进行交互,数据的差异性更大,随机梯度的偏差也更大。当过数据的轮数S≪n/K2时,额外误差的影响可以忽略。也就是说,使用局部重排数据分配策略时,算法中过数据的轮数要收到计算节点数目的影响。如果计算节点数比较多,过的轮数不能太大。
目前,分布式深度学习领域的发展非常迅速,而以上工作只是我们研究组所做的一些初步探索。希望本文能够让更多的研究人员了解“分布式”需要与“深度学习”进行深度融合,大家一起推动分布式深度学习的新发展!
-
加速器
+关注
关注
2文章
809浏览量
38237 -
机器学习
+关注
关注
66文章
8458浏览量
133243 -
深度学习
+关注
关注
73文章
5523浏览量
121727
原文标题:分布式深度学习新进展:让“分布式”和“深度学习”真正深度融合
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TDA4对深度学习的重要性
什么是深度学习?使用FPGA进行深度学习的好处?
NVIDIA迁移学习工具包 :用于特定领域深度学习模型快速训练的高级SDK
针对线性回归模型和深度学习模型,介绍了确定训练数据集规模的方法
基于预训练模型和长短期记忆网络的深度学习模型
超详细配置教程:用Windows电脑训练深度学习模型
深度学习如何训练出好的模型

如何基于深度学习模型训练实现圆检测与圆心位置预测

如何基于深度学习模型训练实现工件切割点位置预测






 工商网监
工商网监
评论