 如何使用蓝牙低功耗实现遥控器的语音命令
如何使用蓝牙低功耗实现遥控器的语音命令
作者:Bougas Pavlos, Iliopoulos Marios
引言
最初,电视、机顶盒和空调等电器仅需少量控制功能[1]。在大多数情况下,开/关按钮、几个选择按钮和两组增加/减少控制足以完全控制您的设备。
但随着设备支持的功能增加,用户使用的命令和配置选项也随之增加。然而,用户仍希望只用一个遥控器来管理所有功能。为了解决这个问题,工程师们开始整合更复杂的用户界面(UI)。分层菜单出现在电视屏幕上,而越来越多的按钮被填充到遥控器中,以便用户调用和浏览菜单。
今天的重要趋势是让设备更“智能”。智能设备可以连接到其他设备和互联网,来提供更多功能和服务。使用菜单浏览,并用遥控器上的小按钮键输入一大字符串是不切实际的,也不是个愉快的体验。
在本文中,我们将讨论如何使用语音命令来提供更好的用户体验。我们特别研究了使用Dialog基于DA14585的高级语音遥控参考设计,通过蓝牙低功耗(BLE)实现语音命令。
图1较大的 QWERTY遥控器
用语音作为命令界面
语音是一个非常强大和直观的界面。一个简单的短语可以包含足够的信息来描述非常复杂的命令。然而,在嘈杂的环境中捕捉短语并提取有实际意义的信息(通常以字符串的形式),这在技术上是一个挑战。幸运的是,产生这个需求的源头,即智能设备与互联网的连接,也为这一复杂问题提供了解决方案。设备现在可以访问云计算,并且可以受益于最先进的语音到文本识别引擎,如Nuance Communications、微软、谷歌、亚马逊等公司提供的技术。如今,基于云的语音识别服务足以提供非常好的用户体验。
我们为什么还需要遥控器呢?
其实,不断监听语音命令的解决方案很早就开发出来了,设备可以不断地收听周围的声音并搜索命令。但是,背景噪音和用户与麦克风的距离问题,使得难以正确识别信息。此外,设备和云服务之间交换的数据量非常巨大,语音识别引擎面临大量的请求,其中大部分是不相关的。环境声音的不断记录也带来了严重的安全和隐私隐患。
我们需要一种触发器,一般通过按钮、手势或可识别的单词或短语来实现。这种解决方案适用于用户和设备距离很近,例如智能手机。但要在智能电视、机顶盒和用户离设备较远的其他应用中,正确识别触发信号并提供良好的用户体验就要困难很多。麦克风需要靠近用户,不是有遥控器嘛。那么将麦克风嵌入遥控器就再自然不过了。
量化语音识别要求
简单来说,语音命令功能的挑战可以表述为:“捕获‘足够’的高质量语音记录,将其发送到语音识别引擎,然后处理文本结果以得出用户的命令”。这个短语包含两组基本要求。首先是需要触发器。实际上,需要两个触发器:第一个指示命令的开始,第二个指示结束。
第二组要求与音频信号本身有关。语音记录应采用适合引擎处理的格式进行编码,而且质量要“足够”好。质量“足够”好怎么定义呢。安卓兼容性定义文档[2]介绍了有关音频捕获质量指标的一些想法。
频率响应应该在100 Hz到4000 Hz的语音频谱上几乎保持平坦(+/- 3 dB)。这是描述窄带语音信号的众所周知的规范。关于麦克风产生的信号电平,安卓兼容性指南定义了声功率级-RMS图中的单点,以及线性跟踪声功率级的范围。
在1 kHz时声压级(SPL)为90 dB的声音,对于16位PCM信号,应产生2500的RMS。这几乎是16位有符号信号整体振幅范围的10%。想要感觉一下SPL范围的话,正常水平的电视机或典型的人类对话能在1米距离内产生60 dB SPL。相比之下,柴油货车在10米距离处产生90 dB SPL。
图2. 声压级示例
当然,我们不能期望用户在随时想使用语音命令的时候,都能把麦克风放在精确的位置并以特定的音量水平说话。鉴于PCM振幅水平可以线性追踪变化,语音识别引擎可以在一系列不同的声压级工作。要求至少30 dB的范围。从90 dB SPL点开始,麦克风应至少从-18 dB至+12 dB进行线性跟踪; 因此在+72 dB SPL和+108 dB SPL之间。这相当于将麦克风放在离嘴0.8厘米至25厘米之间,并以正常强度说话。
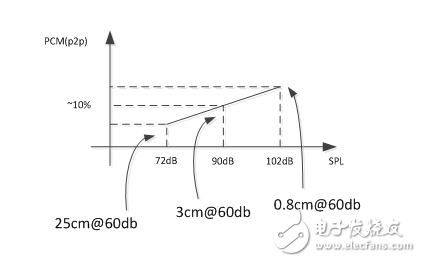
图3. PCM到SPL坐标图
语音识别引擎似乎对非线性行为比较敏感。对于麦克风上90 dB SPL输入电平的1 kHz正弦波,总谐波失真应小于1%。降噪处理、自动增益控制(如果存在)必须禁用。
其他要求
过去曾使用过无线音频协议的人,通常比较怀疑使用面向数据的协议来传输语音命令,例如蓝牙低功耗。
传输语音命令与传输实时音频或人声(如电话交谈)略有不同。由于用户不必回听他们的声音或保持对话,所以延迟要求可以放宽,因为固定的和一定范围内的延迟是不可避免的。但是,数据丢失要求是很严格的,因为缺少音频片段可能使语音识别引擎无法成功提取用户的初始信息。当然机器可以要求您重复这条信息,但这不是人们想要的体验。
构建语音命令遥控器
现在我们看看语音命令遥控器的架构,我们将按照通过系统的音频信号的路径来看。在这个过程中,我们将着眼于在实现经济有效、功率效率高的语音遥控器时经常遇到的挑战,以及可能的解决方法。
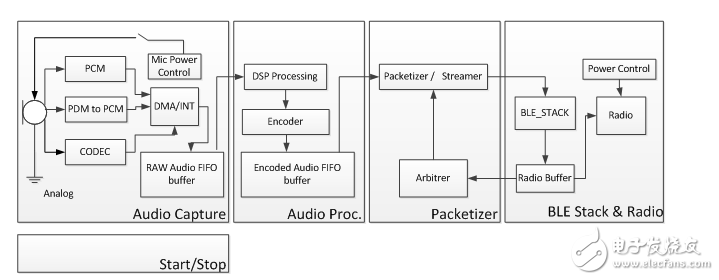
图4. 典型的语音捕获信号路径
一切都从音频捕获子系统开始。这可以基于不贵的模拟麦克风和编解码电路,或数字麦克风,将样本数字化并根据已知的串行协议进行传输。
对于电池供电的系统(如语音命令遥控器),将功耗降到最低至关重要。因此,强烈建议对麦克风或外部编解码器等外部元件的电源进行功率门控。
音频采样率必须至少为8k Samples / s以满足4 kHz音频带宽要求。但是,每个采样至少16位的16k Samples / s是更常规的选择。采用16位采样可确保足够的声压级范围,从而捕获的音频信号将包含足够的信息,以便语音到文字的识别工作正常进行。
采样音频涉及中断或某种形式的硬件 DMA,以获取采样并将其传输到缓冲区。该缓冲区需要将严格定时的音频采样与随后的音频处理解耦。对于低成本设备,音频处理由服务应用程序的相同处理器处理,在某些情况下由BLE协议栈处理。因此,缓冲区的大小将取决于音频处理模块接入CPU、处理音频数据并将其移至下一步所需的最大预期时间。典型的时间在几毫秒内。对于16位16k Samples /s信号,每毫秒产生32个字节,160-200字节缓冲器一般足以允许5毫秒以内的处理时间。
音频处理模块实现简单的音频处理,并对音频数据进行编码以降低其总体速率。音频处理包括非常基础的滤波,如直流偏移消除或带通滤波,和固定增益以优化音频振幅。原始音频数据为256 kbit / s,可以通过BLE进行有余量地流数据传输。为了降低速率并更好地利用带宽,使用已知的音频压缩算法对音频进行编码。编码器的选择比较多样,从简单的固定速率有损编解码器(如IMA-ADPCM),到复杂的处理密集型固定或可变速率算法(如OPUS)。简单的编解码器可以在MIPS容量较低的CPU上运行,但在相同的输出比特率下,生成的音频流质量较低。另一方面,复杂的算法可以提高编码音频流的质量,但需要较贵且耗电较多的CPU。
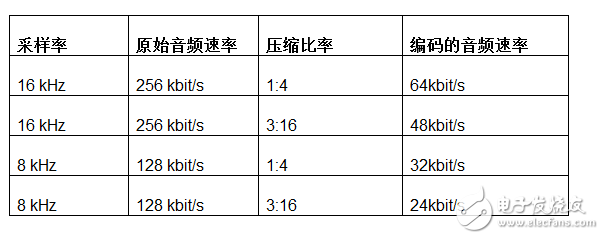
编码器的输出包含需要通过无线传输的最终有效载荷,并且需要一个额外的缓冲器来帮助均衡即时RF数据速率与编码器的平均输出速率。编码器的输出速率等于采样音频速率除以实现的压缩比率。下面的表格显示了Dialog的语音遥控器(Voice RCU)参考设计支持的典型原始和编码音频速率。
表1. 原始的和 IMADPCM 编码的音频
BLE是一种基于数据包的协议,在特定时间点交换数据包,由定期连接间隔分隔开。如果干扰在会合点期间发生使数据包失真,则数据将在下一个数据包中重新传输。每个连接间隔都发生在不同的频率通道中。通常,一个频率范围内会经常出现干扰信号,使多个连接事件失真并显著降低带宽。
BLE提供了一种叫做信道映射更新的机制来解决这个问题。主设备将检测受影响的频率范围,并实施信道映射更新程序。在此之前,BLE连接可能会经历RF数据速率的显著下降。编码器输出端的缓冲区的大小应相应调整,以便能承受此类事件。大小调整可以使用超安全方法,例如缓冲完整5秒钟信息需要40k字节,或者以一半的速率进行5秒钟的缓冲,而不丢失任何数据,这需要20k字节的缓冲。考虑市场上可用的设备,这是一个非常难以满足的要求。大多数设备的整个协议栈和应用程序都只有20 - 40 kbytes的总可用RAM。这个资源不能浪费在单个缓冲区上。需要注意是,缓冲区的大小与编码器输出速率和确保数据不丢失的时间成正比。
市场上已经提出了很多种技术,可以单独使用或组合使用来解决这个问题,而无需很大的缓冲区。在流传输音频样本时增加RF输出功率,以尽可能减少干扰;快速微调信道映射;使用更复杂的编码器来降低所需的RF数据速率,或者甚至在检测到明显的RF带宽下降时动态地降低质量。每种技术都会以牺牲某些其他资源(如能耗、CPU占用或音频质量)的代价来处理问题,而不是使用更多的RAM。
根据所使用的编码器算法,可以将数据存储为连续流或预定义了长度的数据包列表。为了更好地利用BLE带宽,最好将数据视为未经编码器分包的数据流。BLE传输的无损性质确保我们始终能够在遥控器上重建我们的初始数据流。多个BLE连接参数 -- 连接间隔、ATT_MTU大小、数据信道PDU大小和连接事件长度 -- 会影响BLE数据包的理论最佳大小的选择。在运行时,实际的错误率可能需要进一步优化数据包大小。由于消除了遥控器响应和数据包之间间隙所需的时间,使用大一些的数据PDU可以有效地使有效数据速率加倍。另一方面,单个数据包的传输时间延长,增加了在传输数据包期间发生错误的可能性以及重传成本。在严重无线污染的环境中,使用小一点的数据PDU可能会比使用已沟通的最大协议数据单元更有效。
所有这些要求决定了智能模块的出现,智能模块将数据从编码流中提取出来,根据连接特性打包数据,并将其推入BLE协议栈,同时监测实际BLE数据速率和错误率。打包器还应具有某种形式的仲裁和流量控制,以避免过多数据涌入BLE协议栈,并为其他应用保留足够的带宽,以便在音频传输过程中使用BLE进行数据交换,以确保设备不会无响应。
Dialog先进语音遥控解决方案
为了让设计人员能够评估功能完整的语音命令遥控器的性能,Dialog提供了基于单个DA14585 蓝牙低功耗(BLE)SoC的先进语音遥控参考设计。该设计不仅支持语音,还支持一系列附加功能,如无线鼠标、触摸板、红外线以及按键,这些功能都存在于现代遥控器设计中,为用户提供更自然的方式与终端设备进行交互并浏览菜单和结果。
图5. Dialog 语音遥控器开发套件
第二代参考设计包括整个软件架构的重要变化,更加模块化、更易于适应最终产品要求。所有的功能都被组织成模块,具有平台相关和独立的部分。这些模块连接到驱动程序,用于DA14585内部外设或为Dialog先进语音遥控开发板选择的外部元件。
音频路径是根据前面介绍的原则构建的。
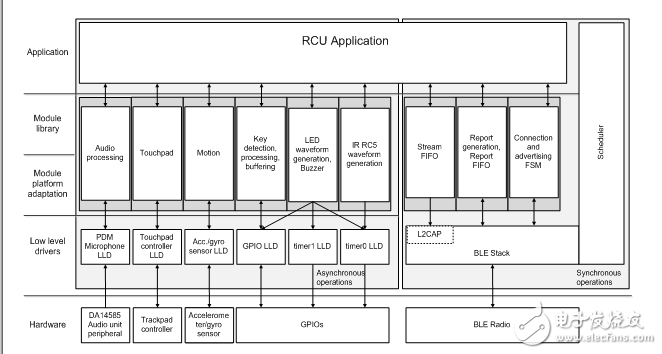
图6. Dialog语音遥控解决方案的系统架构
为了提高音频质量,该设计采用了数字麦克风。对于成本敏感型应用,PDM麦克风比I2S / PCM会更适合。DA14585的集成PDM-PCM转换器将高频PDM信号转换为24位音频PCM采样,并通过专用DMA信道将其传送至存储器缓冲区。
M0 CPU执行音频处理和流传输模块。从主循环中,调用一个预处理模块来应用直流阻断和24位至16位的转换。如果需要,下采样单元可以将音频采样率从16k Samples / s减少到8k Samples / s。音频预处理单元的结果被馈送到IMA ADPCM编码器。根据配置的不同,编码器会为每个16位音频采样生成一个4位或3位采样。
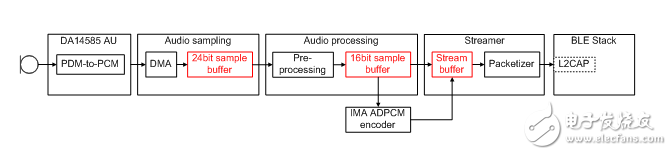
图7. Dialog语音遥控解决方案音频路径
作为设计选择,该参考设计支持自适应音频速率机制,以防止可能的缓冲区欠载。音频采样的采样率和/或IMA ADPCM编码器的配置可随时更改,从而可以在不同的输出速率之间切换。为了支持这种机制,已经开发了带内信令机制。编码器的输出和带内信令共享同一个的数据流缓冲区。
打包器模块收集来自数据流缓冲区的数据,并高效地将它们推入协议栈,同时尽量不溢出。除了考虑连接参数外,打包器还密切监测错误率和瞬时可用带宽。这有助于其在自适应音频速率机制启用时,做出是否降低或提高音频质量的决定。
所有策略,如使用固定或自适应音频速率,音频开始和停止的方式,均由用户或远程设备控制。单独的缓冲区大小都是配置选项,因为根据最终应用的不同,可能适合不同的用户体验。
结论
将设备连接到互联网的能力,与现代基于云的语音识别服务相结合,实现了强大的新用户界面 - 语音命令。智能手机、智能电视和机顶盒已经在使用语音命令。通过将低成本的麦克风集成到BLE连接的外围设备中,用户的语音识别体验可以大大增强。从遥控器、智能手表和可穿戴设备收集的命令,通过智能设备传输到云中的语音识别引擎,可以控制智能设备本身以及与智能设备相连的外围设备或由语音助理控制的其他设备。
-
遥控器
+关注
关注
18文章
842浏览量
66721 -
dialog
+关注
关注
12文章
274浏览量
93048 -
蓝牙低功耗
+关注
关注
0文章
30浏览量
9079
发布评论请先 登录
相关推荐
四频拷贝遥控器走俏海外

技术再进化——工业遥控器技术要求更高
数字遥控器

RF遥控器厂家:射频遥控器将成为未来的控制主流
HS6621C高性能BLE芯片主从一体MESH组网M4内核支持语音采样/苹果MFI认证/寻物标签/语音遥控
如何选购适合的拷贝遥控器——增配遥控器教程来啦

遥控器解码器怎么使用
蓝牙语音遥控器方案
国产蓝牙模组 | 低功耗蓝牙应用

老陆测功耗03 | 遥控器该扔吗?

蓝牙模块选经典蓝牙还是低功耗蓝牙?

AW30N蓝牙语音芯片
基于国民技术N32WB031的蓝牙语音遥控器解决方案






 工商网监
工商网监
评论