 基于硬件在环的无人驾驶仿真平台
基于硬件在环的无人驾驶仿真平台
第29届IEEE国际智能车大会(IEEE IV 2018)于6月30日在江苏常熟顺利落幕,本届大会 的Best Student Paper Awards(最佳学生论文奖)分别颁给了来自西安交通大学、加州大学伯克利分校、中山大学的三篇论文。
本届IV大会共收到了来自34个国家的603篇论文,其中确认接收的论文346篇,在所有接收的论文里,Automated Vehicles, Vision Sensing and Perception, and Autonomous / Intelligent Robotic Vehicles成为本届论文最热的关键词。
IV会议共设有“BestPaperAwards”、 “BestStudentPaperAwards” 、 “ BestWorkshop / Special Session Paper Awards ” 、 “Best Poster Paper Awards ” 和 “BestApplication Paper Awards”五大奖项。本文主要介绍获得Best Student PaperAwards(最佳学生论文奖)的三篇论文,与之前BestPaper Awards论文不同,这三篇论文的第一作者都是在校学生。
IEEE IV 2018 Best Student Paper Awards
First Prize
在最佳学生论文中,获得一等奖的是来自西安交通大学的论文基于硬件在环的无人驾驶仿真平台(Autonomous Vehicle Testing and Validation Platform: Integrated Simulation System with Hardware in the Loop)。该论文的作者为YU Chen,Shitao Chen等都来自郑南宁院士团队。以下是论文简述:
随着自动驾驶的发展,离线测试和仿真是目前用于多种交通场景中无人驾驶车辆性能验证的一种低成本,低风险且高效率的方法。在我们的工作中因考虑到现今不同仿真平台的不足,我们提出了一种新型的,基于硬件在环系统的仿真平台。该平台支持车辆动力学仿真,各种传感器仿真以及多种复杂交通场景构建。通过硬件在环的测试与验证方式我们能够有效地利用仿真环境来规避路测所带来的潜在风险并验证无人车多模块算法安全性。同时通过与真车中完全相同的硬件层沟通仿真环境与现实场景,我们能够准确有效地完成已验证的算法从仿真环境到真实场景的迁移。
1.仿真平台开发的目的
为了保证无人驾驶车辆开发的安全性,有效性和可持续性,必须进行广泛的开发和测试。然而传统的无人驾驶路测昂贵耗时,具有风险性且只能够在有限交通场景下进行试验。此外,一些特殊场景,如极端天气,传感器故障,道路部分路段损毁等也不能够进行反复的测试和复现。而无人驾仿真系统则为这个难题提供了一种安全有效的解决途径。借助仿真环境中对车辆动力学控制,多传感器仿真,多交通场景模拟,我们可以极大地提高开发效率,验证无人驾驶环境感知,车辆定位,路径规划以及决策控制等多模块算法的有效性。
目前应用于无人驾驶仿真领域仿真器多种多样,被广泛使用的主要有TORCS, PRESCAN, CarSim, Carla等。然而这些仿真器也并不能真正意义上全面地实现对无人车性能测试的多方面的要求。涉及到的问题有车辆模型和驾驶场景的逼真度,算法测试的准确度,仿真流程的有效性以及仿真器自身是否对大多数开发者们友好开放等。
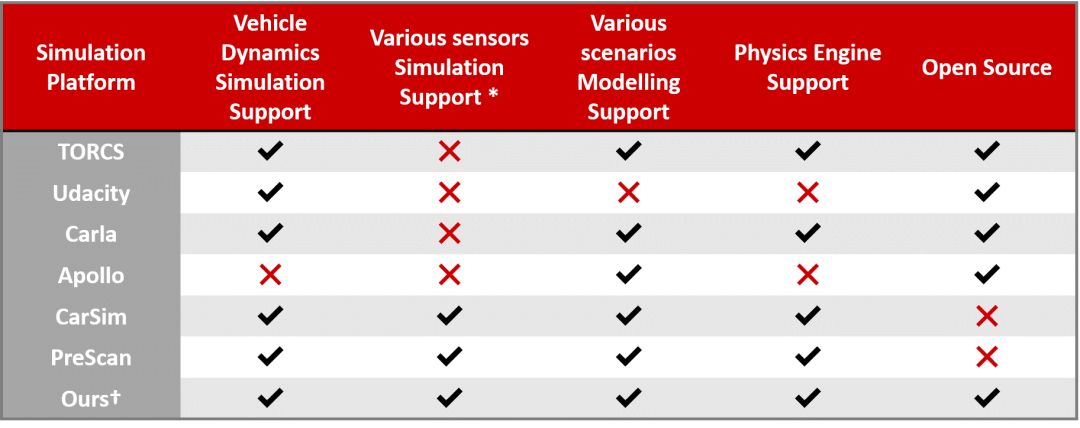
图1 多仿真器对比表
实际上现在大多数的开源仿真器都是特别适用于无人驾驶仿真的单一或者几个特定的模块,并不能被应用于所用驾驶场景中。一些商业化的仿真器的功能更为全面但价格也比较昂贵。因而在我们的工作中我们的目的就是构建一个全面的,对开发者友好的仿真平台。
此外,采用硬件在环系统进行仿真是我们平台进行开发验证的核心。在硬件在环的仿真方法中,我们将待进行测试的控制单元硬件连接到虚拟的仿真环境中来测试核心算法的可行性和控制器的有效性。这样不仅能够快速有效地评估算法的性能,同时也能够极大的提升测试安全性和算法安全性。一方面基于硬件在环的仿真避免了实际道路测试可能导致的风险,另一方面我们能够在模拟的仿真环境中进行各种特殊驾驶场景的测试从而训练算法,不断提高其鲁棒性,最终保证对仿真车辆安全驾驶的模拟。
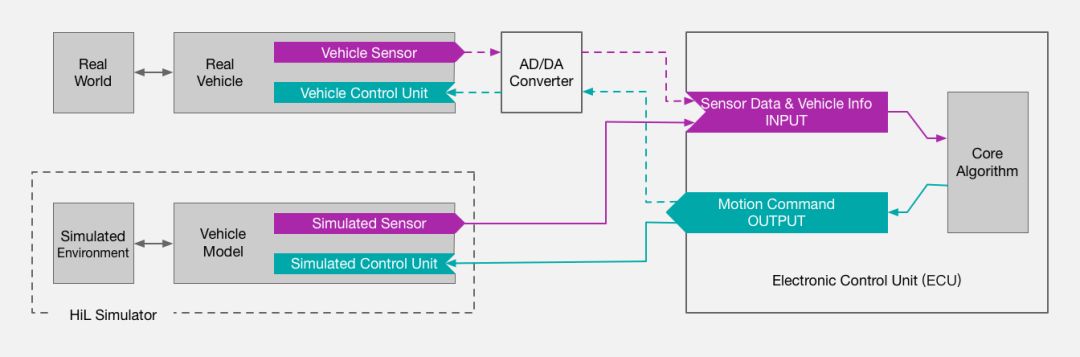
图2 硬件在环仿真系统示意图
2.仿真方法介绍
图3 仿真框架示意图
仿真平台包含仿真层和硬件层两大模块。其中仿真层包括了仿真车辆模型设计,多仿真传感器模拟以及多虚拟交通场景构建。硬件控制层与仿真层相连接构成闭环测试系统,用于全面测试和验证硬件和算法。仿真传感器信息以及车身状态由仿真层输入到算法进行相关计算后输出结果到硬件控制单元生成相应的控制指令,如刹车,油门、转向指令等,再传入到仿真层对车辆进行相应控制。
首先对于仿真层中车辆动力学的模型设计,我们使用3D建模软件先进行车辆建模,设定相关的必要参数,如重量、惯性、摩擦系数、扭矩等;考虑到实际车辆的安全性,仿真车辆的最大速度,前轮最大转角,最大扭矩和最大胎压等参数也需要具体设定;另外为了实现车辆横向与纵向的平稳动力学控制,我们采用了Ackermann转向几何模型来保证车辆的安全转向。
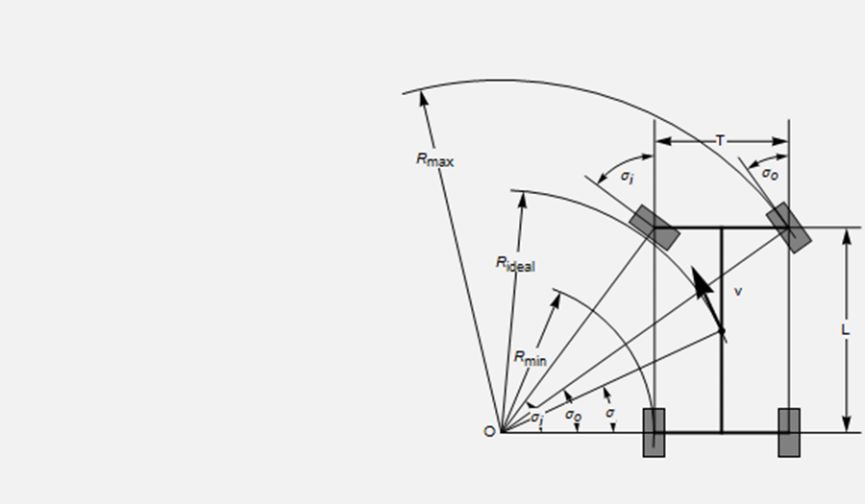
图4 Ackermann模型
其次对于多种无人驾驶所需的传感器的仿真,我们的平台支持对双目/单目相机,多线激光雷达(16/32/64),超声波雷达,GPS以及惯性测量单元IMU的仿真模型以及实际功能模拟。传感器能够被简单快速地添加,移动或者移除。我们也可选择是否连接到传感器或者随时更新其配置参数,如探测范围,信息更新频率,噪声程度等。
图5 多传感器模拟示意图
最后对于多种虚拟驾驶环境的构建,主要有两种方法。第一种是使用模型库中提供的一些仿真模型,或者自行根据需求利用3D建模软件构建仿真模型,再对单个的仿真模型进行整合从而构建出预期的仿真场景。另一种方法是使用OpenStreetMap来直接通过地图来导出大场景模型再进行后期精细化操作。OpenStreetMap是一个强大的地图编辑平台,某一局部区域甚至是某一城市的实际地图都能够被在线导出成可编辑的文件,从而方便实现对某一固定实际场景仿真,同时也很大程度上节约了场景构建的时间。
图6 利用OSM获得场景模型示意图
3.实验与验证
论文中提出的硬件在环仿真平台可以被用来验证无人驾驶车辆环境感知,路径规划以及运动控制等重要模块的算法有效性。我们分别对与这些模块紧密相关的路径跟随算法、自动泊车算法以及基于多智能体(multi-agent)的车辆跟随算法进行了测试与验证。

图7 仿真验证模块示意图
首先对于仿真车辆的路径跟随算法, 其需要根据给定的行驶路径计算出符合车辆动力学的刹车,油门,转向指令来实现平稳的路径跟随过程。
然后对于自动泊车算法,我们构建了一个虚拟的停车场环境方便场景模拟。目标车辆需要在行进过程中依据传感器信息找到距离自己最近的可用停车位,并选用合适的停车方式来规划出停车路径并实现平稳泊车。
最后对于基于多智能体系统的车辆跟随算法, 论文中假设每一辆车为一个智能体,其与周围车辆以及驾驶环境进行实时交互。这样的多智能体系统可以用来进行V2V以及V2I等方面的开发。论文中我们进行了车辆跟随算法的验证。通过基于增强学习的训练过程,跟随车辆能够始终与前车保持一定安全距离,稳定地实现跟车换道等行为。
4.总结
论文中我们提出了一种新型的基于硬件在环的无人车仿真与测试平台。其能够很好的实现对车辆动力学模型,多种传感器以及不同驾驶场景的模拟。同时硬件在环的仿真方法在降低测试成本和时间的条件下,也保证了测试的安全性和验证了算法的安全性。
Second Prize

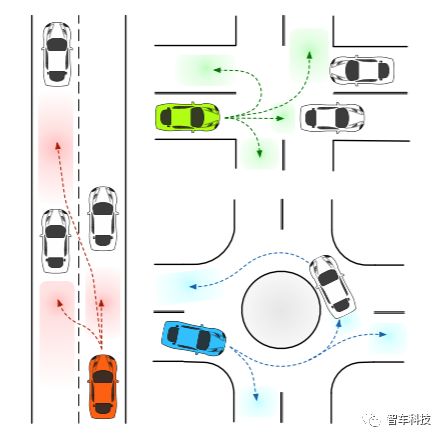
预测车辆在不同驾驶场景下的插入区域(彩色区域)
获得最佳学生论文二等奖的是来自美国加州大学伯克利分校机械工程系的Yeping Hu博士,他在论文中分享了他们在车辆语义意图和运动的概率预测方面的研究论文。研究涵盖城市自动驾驶的决策,运动规划和运动预测。目前正在开展一项BDD项目:“基于深度神经网络学习的随机政策的城市自主驾驶运动预测”。目前大多数研究仅通过考虑特定场景来确定驾驶意图的数量。然而,不同的驾驶环境通常包含各种可能的驾驶操纵。因此,需要一种能够适应不同流量场景的意图预测方法。在Yeping Hu博士的论文中提出了一种基于语义的意图和运动预测(SIMP)方法,可以通过使用语义定义的车辆行为来适应任何驾驶场景。它利用基于深度神经网络的概率框架来估计周围车辆的意图,最终位置和相应的时间信息。
Third Prize

最佳学生论文的三等奖来自中山大学数据与计算机科学学院,该论文研究了计算机视觉的内容,同时还是国家自然科学基金项目。以下是论文的主要内容:
计算机视觉因为可以有效且通过易获得的方式获取周边环境的颜色信息而成为了研究广泛的热门领域。通过摄像头来帮助机器人或无人车理解其所处的外部环境也成为至关重要的一步。通过双目视觉算法可以获得图像中像素点的深度信息从而可以对周围场景进行三维建模。然而,当前所存在的三维空间表达形式存在有明显的弊端,主要的问题集中在以下两点:第一大规模的三维场景数据信息量非常大,如何有效的压缩地图大小存在一定难度;第二是如何更大程度的保存有效信息并且保障精度。
在本文中,我们关注这些问题并且提出了一种全新的三维空间表达形式并且将其命名为Planecell。通过在深度信息的监督下的平面转区,我们可以将平面单元投影到三维空间中去。所提出的Planecell表达方式适用于大规模的人造场景中,可以在不丢失像素级别精度的情况下明显的减少存储图像大小,并且可以拓展到更多的三维重建应用当中。通过实验检验,我们的三维空间表达形式相比于点云地图大小在同等精度下缩小了200倍,并且我们也和当前排名靠前的深度学习双目匹配算法得到的点云地图进行了像素级别的精度比较,同样达到了不错的结果。
图1:Planecell方法流程图
1.方法简介
如图一所示,本文所提出方法的输入是一张色彩图像和对应的深度图像。我们使用一种深度监督的超像素分割算法通过在边界更新方程中加入深度衡量项对左图进行切割。超像素分割过程使用了爬山法来减少不必要的计算量。同时,我们还在边界更新方程中加入规则化项来避免超像素边界的复杂化(复杂的超像素边界不利于保存和二维-三维转化)。超像素的分层边界更新只进行到固定边长的网格大小,不再进行像素级别的更新。深度图在本文中使用双目匹配方法来得到结果。同样的,较为稀疏的或者是通过其他传感器得到的深度图也可以作为我们算法的输入,因为我们的算法在拟合平面时使用了随机取样的方式来避免错误点对于结果的负面影响。超像素的边界会在平面方程拟合结果出来后进行进一步的更新。每一个超像素都是之后进行重建的基本元素。
为了更高效的保存每一个超像素。我们提出一种方法来抓取每一个超像素的角点。因为每一个超像素都是多边形,所以只需它们的角点就能完整的保存他们的边界信息。将二维超像素投影到三维空间中后,对于已存在的三维平面,我们通过最小化全局能量方程来聚合关系为共面单元。
2.实验验证
我们根据数据集的特性,分别在三个数据集上了测试了我们的算法。三个数据集分别是KITTI Stereo、KITTI Odometry和 Middlebury Stereo 数据集。KITTI Stereo 数据集将用于测试的双目图片分为测试集和训练集,其中训练集部分包含了通过激光雷达获得的视差真值。每一组图片包含前后两帧的左右图共四张图片。KITTI测试榜单所提供的室外场景是具有挑战性的,因为每一幅图片都包含十分明显的视差变化。我们的算法表现了对于 KITTI 数据集处理的优越性,尤其是对于包含大量几何结构人造场景的图像。为了更好的表现我们所提出的三维空间表达方式对于大规模大尺度输入的处理能力,我们在 KITTI Odometry 上测试了上千张双目图片作为输入的结果。第三个数据集是 Middlebury Stereo 2001 数据集,其中包含了9组室内场景。
我们从结果的精度、速度、内存需求和传达有用信息的能力等方面对我们的算法进行了评估。我们在精度上对比了最基本的直接将二维像素点投影到三维空间点云的方法。接下来,我们修改了我们算法的输入视差图算法(包括密集、半密集和稀疏)来测量我们算法的适应性。我们同样对比了我们算法与基于体素的三维表达方式的优势。

表1 测试平台
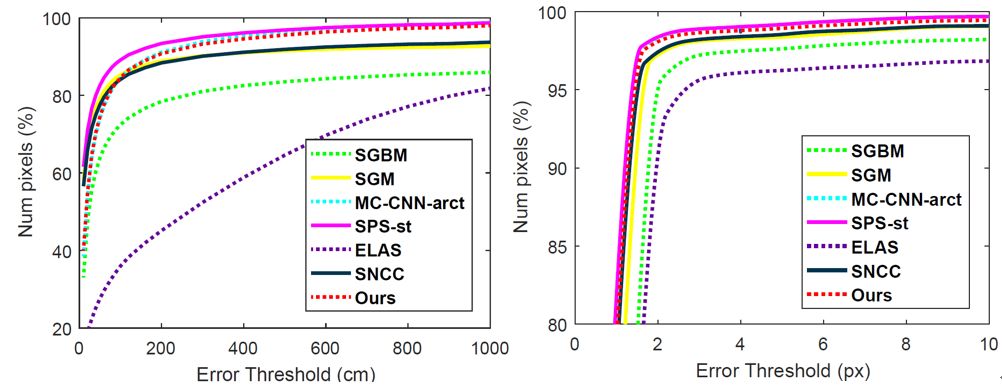
图2:像素级别精度对比(左:KITTI stereo,右:Middlebury)
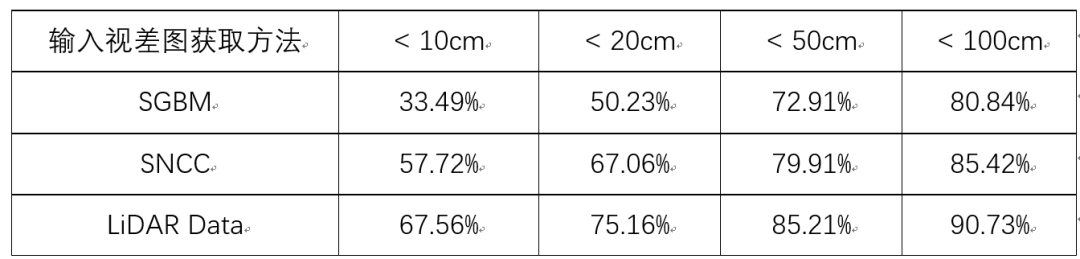
表2:修改视差图输入在KITTI数据集上的精度结果
图3:单帧地图重建结果(自上而下分别为左图,点云图,
voxel地图和Planecell地图)
图4:2000帧的重建结果(89.1MB)
我们在本文中提出了一种新颖的方法,用一种名为 Panecell 的基本平面单元来表示结构三维空间。平面单元以深度感知方式提取,并且如果它们属于应用所提出的CRF模型的相同表面,则可以进一步聚合。实验表明,我们的方法考虑了像素级精度,同时有效地表达了相似像素的位置。结果避免了点云映射的冗余,并限制了输出映射大小以用于进一步的应用。在我们未来的工作中,我们计划开发更复杂的平面模型,如球体和圆柱体,以适应更多条件。我们还相信,给每个平面单元一个语义标签可以更有效地扩展对环境的理解。
-
传感器
+关注
关注
2548文章
50717浏览量
752112 -
无人驾驶
+关注
关注
98文章
4036浏览量
120306
原文标题:IV 2018 最佳学生论文奖丨西交大“基于硬件在环的无人驾驶仿真平台”论文获最佳
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
东华软件:多地无人驾驶项目成功落地
UWB模块如何助力无人驾驶技术
特斯拉推出无人驾驶Model Y
【干货分享】硬件在环仿真(HiL)测试
文远知行无人驾驶扫路机在广东汕头落地
5G赋能车联网,无人驾驶引领未来出行

EasyGo使用笔记丨分布式光伏集群并网控制硬件在环仿真应用


中国或支持特斯拉测试无人驾驶出租

【分享】基于Easygo仿真平台的三电机实时仿真测试应用
32.768K晶振X1A000141000300适用于无人驾驶汽车电子设备
5G车载路由器引领无人驾驶车联网应用

详解快速控制原型RCP与硬件在环仿真HIL





 工商网监
工商网监
评论