 在Linux上什么是段错误?如何获得一个核心转储?
在Linux上什么是段错误?如何获得一个核心转储?
本周工作中,我花了整整一周的时间来尝试调试一个段错误。我以前从来没有这样做过,我花了很长时间才弄清楚其中涉及的一些基本事情(获得核心转储、找到导致段错误的行号)。于是便有了这篇博客来解释如何做那些事情!
在看完这篇博客后,你应该知道如何从“哦,我的程序出现段错误,但我不知道正在发生什么”到“我知道它出现段错误时的堆栈、行号了! ”。
什么是段错误?
“段错误segmentation fault”是指你的程序尝试访问不允许访问的内存地址的情况。这可能是由于:
试图解引用空指针(你不被允许访问内存地址0);
试图解引用其他一些不在你内存(LCTT 译注:指不在合法的内存地址区间内)中的指针;
一个已被破坏并且指向错误的地方的 C++ 虚表指针C++ vtable pointer,这导致程序尝试执行没有执行权限的内存中的指令;
其他一些我不明白的事情,比如我认为访问未对齐的内存地址也可能会导致段错误(LCTT 译注:在要求自然边界对齐的体系结构,如 MIPS、ARM 中更容易因非对齐访问产生段错误)。
这个“C++ 虚表指针”是我的程序发生段错误的情况。我可能会在未来的博客中解释这个,因为我最初并不知道任何关于 C++ 的知识,并且这种虚表查找导致程序段错误的情况也是我所不了解的。
但是!这篇博客后不是关于 C++ 问题的。让我们谈论的基本的东西,比如,我们如何得到一个核心转储?
运行 valgrind
我发现找出为什么我的程序出现段错误的最简单的方式是使用valgrind:我运行
valgrind -vyour-program
这给了我一个故障时的堆栈调用序列。 简洁!
但我想也希望做一个更深入调查,并找出些valgrind没告诉我的信息! 所以我想获得一个核心转储并探索它。
如何获得一个核心转储
核心转储core dump是您的程序内存的一个副本,并且当您试图调试您的有问题的程序哪里出错的时候它非常有用。
当您的程序出现段错误,Linux 的内核有时会把一个核心转储写到磁盘。 当我最初试图获得一个核心转储时,我很长一段时间非常沮丧,因为 – Linux 没有生成核心转储!我的核心转储在哪里?
这就是我最终做的事情:
在启动我的程序之前运行ulimit -c unlimited
运行sudo sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t
ulimit:设置核心转储的最大尺寸
ulimit -c设置核心转储的最大尺寸。 它往往设置为 0,这意味着内核根本不会写核心转储。 它以千字节为单位。ulimit是按每个进程分别设置的 —— 你可以通过运行cat /proc/PID/limit看到一个进程的各种资源限制。
例如这些是我的系统上一个随便一个 Firefox 进程的资源限制:
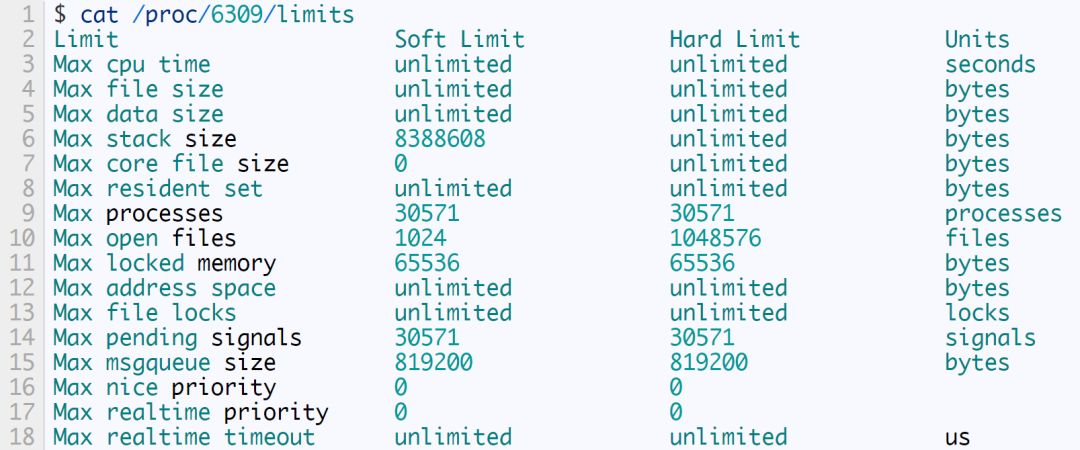
内核在决定写入多大的核心转储文件时使用软限制soft limit(在这种情况下,max core file size = 0)。 您可以使用 shell 内置命令 ulimit(ulimit -c unlimited) 将软限制增加到硬限制hard limit。
kernel.core_pattern:核心转储保存在哪里
kernel.core_pattern 是一个内核参数,或者叫 “sysctl 设置”,它控制 Linux 内核将核心转储文件写到磁盘的哪里。
内核参数是一种设定您的系统全局设置的方法。您可以通过运行 sysctl -a 得到一个包含每个内核参数的列表,或使用 sysctl kernel.core_pattern 来专门查看 kernel.core_pattern 设置。
所以 sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t 将核心转储保存到目录 /tmp 下,并以 core 加上一系列能够标识(出故障的)进程的参数构成的后缀为文件名。
如果你想知道这些形如 %e、%p 的参数都表示什么,请参考 man core。
有一点很重要,kernel.core_pattern 是一个全局设置 —— 修改它的时候最好小心一点,因为有可能其它系统功能依赖于把它被设置为一个特定的方式(才能正常工作)。
kernel.core_pattern 和 Ubuntu
默认情况下在 ubuntu 系统中,kernel.core_pattern 被设置为下面的值:
$sysctl kernel.core_pattern
kernel.core_pattern = |/usr/share/apport/apport %p %s %c %d %P
这引起了我的迷惑(这 apport 是干什么的,它对我的核心转储做了什么?)。以下关于这个我了解到的:
Ubuntu 使用一种叫做 apport 的系统来报告 apt 包有关的崩溃信息。
设定kernel.core_pattern=|/usr/share/apport/apport %p %s %c %d %P意味着核心转储将被通过管道送给apport程序。
apport 的日志保存在文件/var/log/apport.log中。
apport 默认会忽略来自不属于 Ubuntu 软件包一部分的二进制文件的崩溃信息
我最终只是跳过了 apport,并把kernel.core_pattern重新设置为sysctl -w kernel.core_pattern=/tmp/core-%e.%p.%h.%t,因为我在一台开发机上,我不在乎 apport 是否工作,我也不想尝试让 apport 把我的核心转储留在磁盘上。
现在你有了核心转储,接下来干什么?
好的,现在我们了解了ulimit和kernel.core_pattern,并且实际上在磁盘的/tmp目录中有了一个核心转储文件。太好了!接下来干什么?我们仍然不知道该程序为什么会出现段错误!
下一步将使用gdb打开核心转储文件并获取堆栈调用序列。
从 gdb 中得到堆栈调用序列
你可以像这样用gdb打开一个核心转储文件:
$gdb -cmy_core_file
接下来,我们想知道程序崩溃时的堆栈是什么样的。在 gdb 提示符下运行 bt 会给你一个调用序列backtrace。在我的例子里,gdb 没有为二进制文件加载符号信息,所以这些函数名就像 “??????”。幸运的是,(我们通过)加载符号修复了它。
下面是如何加载调试符号。
symbol-file /path/to/my/binary
sharedlibrary
这从二进制文件及其引用的任何共享库中加载符号。一旦我这样做了,当我执行 bt 时,gdb 给了我一个带有行号的漂亮的堆栈跟踪!
如果你想它能工作,二进制文件应该以带有调试符号信息的方式被编译。在试图找出程序崩溃的原因时,堆栈跟踪中的行号非常有帮助。:)
查看每个线程的堆栈
通过以下方式在 gdb 中获取每个线程的调用栈!
thread apply all bt full
gdb + 核心转储 = 惊喜
如果你有一个带调试符号的核心转储以及gdb,那太棒了!您可以上下查看调用堆栈(LCTT 译注:指跳进调用序列不同的函数中以便于查看局部变量),打印变量,并查看内存来得知发生了什么。这是最好的。
如果您仍然正在基于 gdb 向导来工作上,只打印出栈跟踪与bt也可以。 :)
ASAN
另一种搞清楚您的段错误的方法是使用 AddressSanitizer 选项编译程序(“ASAN”,即$CC -fsanitize=address)然后运行它。 本文中我不准备讨论那个,因为本文已经相当长了,并且在我的例子中打开 ASAN 后段错误消失了,可能是因为 ASAN 使用了一个不同的内存分配器(系统内存分配器,而不是 tcmalloc)。
在未来如果我能让 ASAN 工作,我可能会多写点有关它的东西。(LCTT 译注:这里指使用 ASAN 也能复现段错误)
从一个核心转储得到一个堆栈跟踪真的很亲切!
这个博客听起来很多,当我做这些的时候很困惑,但说真的,从一个段错误的程序中获得一个堆栈调用序列不需要那么多步骤:
试试用valgrind
如果那没用,或者你想要拿到一个核心转储来调查:
确保二进制文件编译时带有调试符号信息;
正确的设置ulimit和kernel.core_pattern;
运行程序;
一旦你用gdb调试核心转储了,加载符号并运行bt;
尝试找出发生了什么!
我可以使用gdb弄清楚有个 C++ 的虚表条目指向一些被破坏的内存,这有点帮助,并且使我感觉好像更懂了 C++ 一点。也许有一天我们会更多地讨论如何使用gdb来查找问题!
-
Linux
+关注
关注
87文章
11373浏览量
211207 -
C++
+关注
关注
22文章
2114浏览量
74126 -
线程
+关注
关注
0文章
507浏览量
19844
原文标题:在 Linux 上如何得到一个段错误的核心转储
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
安装Z-Stack_Linux_Gateway_1_0_1_installer.run出错,请问是系统不支持吗?
在Linux上升级到ISE 11.3出现总线错误
Vivado 2014.1在SLES10上安装失败
转储用于VHDL代码的saif文件
Ubuntu 16.04系统中调试Apollo项目核心转储文件的方法
什么是段错误?
内核转储的设置
Linux内核在Linux系统中到底处于一个什么样的地位





 工商网监
工商网监
评论