 浅析人脸辨识的技术环节
浅析人脸辨识的技术环节

人脸辨识的核心问题,不管是人脸确认(face verification)或是人脸识别(face identification),都必须在人脸上取出具有「辨别度」的特征值。
也就是说,同个人的多张照片,即使在不一样的光源、时间、打扮、些微的表情、视角变化之下拍摄,还具有非常类似的高维数值(可以想象在高维空间中非常相近的点群),相反地,对于不同人的照片,需很容易区别,在高维空间中维持相当的距离。
这目标听起来很直觉,但是研究人员几十年来的努力到最近才有突破性的发展。
人脸辨识的一般步骤为:人脸侦测、人脸校正、人脸特征值的撷取。目的在照片中,找到人脸的位置,利用人脸的特征点(如嘴角、人中、眼睛等)为锚点,将人脸校正到同一个比较基准,然后取出特征值来进行辨识。
早期的人脸侦测大多基于效率的考量,利用组合一系列简易的运算来检测画面中的可能人脸,甚至可以在相机的硬件中实现。但是在实际场域中的应用仍然有诸多限制,直到这几年深度卷积神经网络(Convolutional Neural Network;CNN )的使用,才让侦测率大大提升。
人脸特征值的撷取是最核心的问题。早期广泛采用的方法为特征脸(eigenface),这是1991年MIT提出的方法,原理是人脸具有大致的轮廓,可以找出特征人脸为基础来线性组合出各个人脸。理论上同一个人的线性组合参数应该类似,所以就用这些组合参数来作为人脸特征值。
此外,还可以利用人脸各个器官之间的相对位置、比例等作为特征值。或是利用邻近画素的亮度差来表示特征值的局部二值样式(Local Binary Patterns;LBP)。或是将人脸特定位置的外观,利用具代表性的小区块进行编码的稀疏编码法(sparse coding)。这些技术都为人脸辨识的落实往前推进一步。为求系统稳定,大部分应用系统都采用鸡尾酒作法,也就是混搭各种特征值。
为何早期使用人脸辨识的场域不多呢?因为错误率所造成的困扰远大于技术的效率。举例来说,保全系统使用人脸辨识作为门禁卡,如果错误率5%的话,每100人次进出,就有5次需要人为介入,不胜其烦。
技术的正确率、稳定度的提升关乎可否全面落实到产品上,也就只有等到深度学习(更准确为卷积神经网络)技术的突破,才让人脸辨识数十年的研究有机会在产业界带来广泛应用的机会,而且有机会溢出传统安控领域而成为「个人化」的基础引擎。
-
人脸识别
+关注
关注
77文章
4132浏览量
88761
原文标题:【名家专栏】人脸辨识的技术环节
文章出处:【微信号:DIGITIMES,微信公众号:DIGITIMES】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
企业安防中的人脸识别技术应用解决方案,八达马人脸技术剖析
人工智能架构下人脸辨识解决方案(附原理图+文档+boom清单)
什么是智能影像辨识系统?
义隆强攻当红的3D人脸辨识与无人车最关键的先进驾驶辅助系统
三星动脉辨识技术 可作为穿戴设备识别之用
浅析人脸识别技术的优势及应用
人脸识别技术的优势浅析
浅析人脸识别技术应用的未来
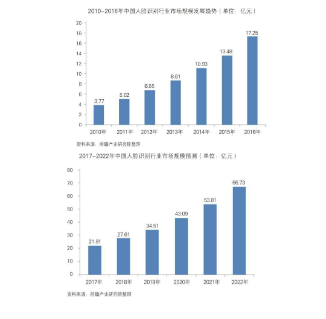
人脸识别技术在地铁安检环节的应用
IBM宣布退出人脸辨识领域
人脸辨识也会引起种族歧视?
浅析人脸识别技术
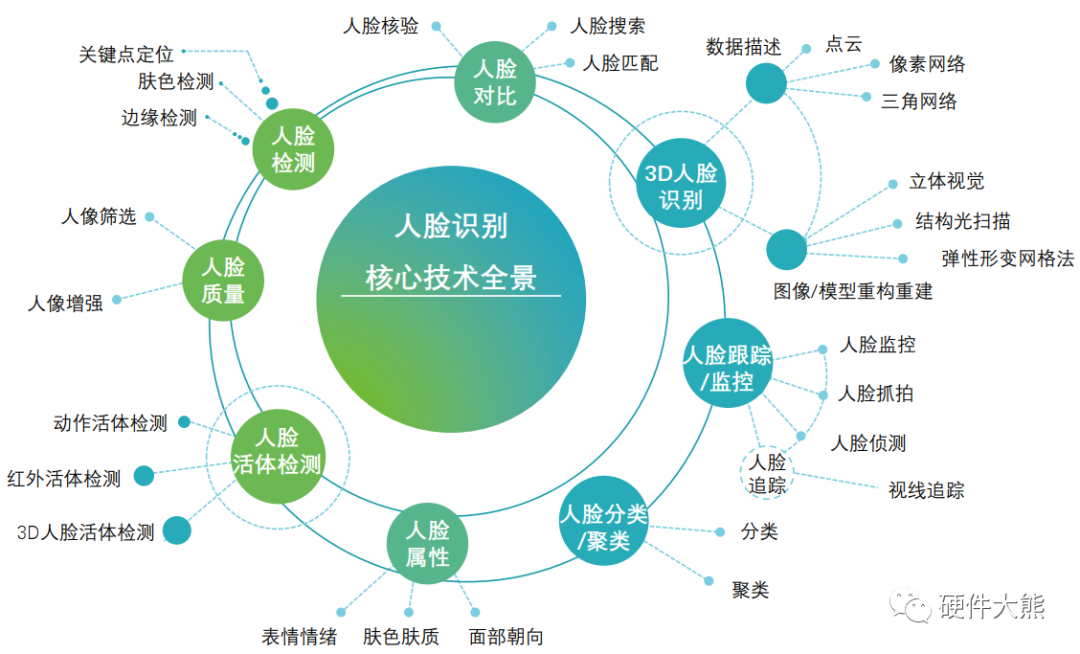



评论