 基于INTEL FPGA硬浮点DSP实现卷积运算详解
基于INTEL FPGA硬浮点DSP实现卷积运算详解
概述
卷积是一种线性运算,其本质是滑动平均思想,广泛应用于图像滤波。而随着人工智能及深度学习的发展,卷积也在神经网络中发挥重要的作用,如卷积神经网络。本参考设计主要介绍如何基于INTEL 硬浮点的DSP Block实现32位单精度浮点的卷积运算,而针对定点及低精度的浮点运算,则需要对硬浮点DSP Block进行相应的替换即可。
原理分析
设:f(x), g(x)是两个可积函数,作积分:
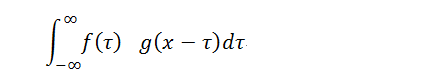
随着x的不同取值,该积分定义了一个新的函数h(x),称为函数f(x)与g(x)的卷积,记为h(x)=f(x)*g(x)。
如果卷积的变量是序列x(n)和h(n),则卷积的结果为
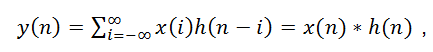
其中*表示卷积。因此两个序列的卷积,实际上就是多项式的乘法,用个例子说明其工作原理。a = [7,5,4]; b = [6,7,9];则实现a和b的卷积,就是把a和b作为一个多项式的系数,按多项式的升幂或降幂排列,即为:
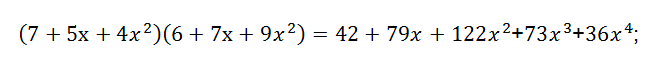
因此得到a*b=[42,79,122,73,36];与Matlab运算结果一致。而二维卷积可以采用通用多项式乘积方法实现卷积运算。
基于INTEL FPGA的实现分析
如上我们确定了两个序列的卷积等同于两个多项式的乘法,因此当我们需要计算序列[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果时,可以成立a,b两个n阶多项式,如下所示:
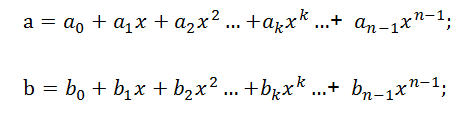
则[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果即为由a*b得到的多项式的各项系数所组成的序列。令c=a*b,得到
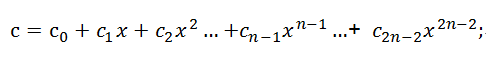
则由多项式c的各阶系数所组成的新的序列[c0,c1,c2, …,c2n-1]即为[a0,a1,a2, …,an-1]与[b0,b1,b2, …,bn-1]的卷积结果。则按照高阶多项式计算展开可得到:
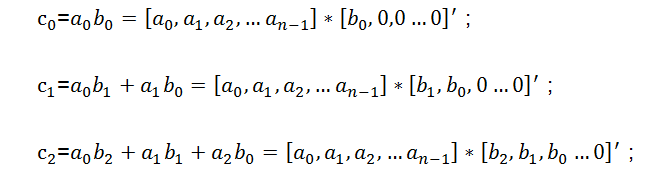
┆┆
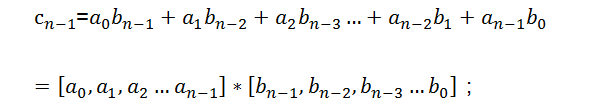
┆┆
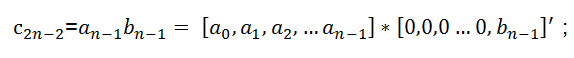
因此卷积的运算可以转化为行向量与列向量相乘的结果,即乘累加的运算结构。
Intel FPGA在Arria10DSP Block中首次支持了单精度硬浮点DSP block,是行业内第一个支持单精度DSP block,硬浮点DSP block架构如图1所示:
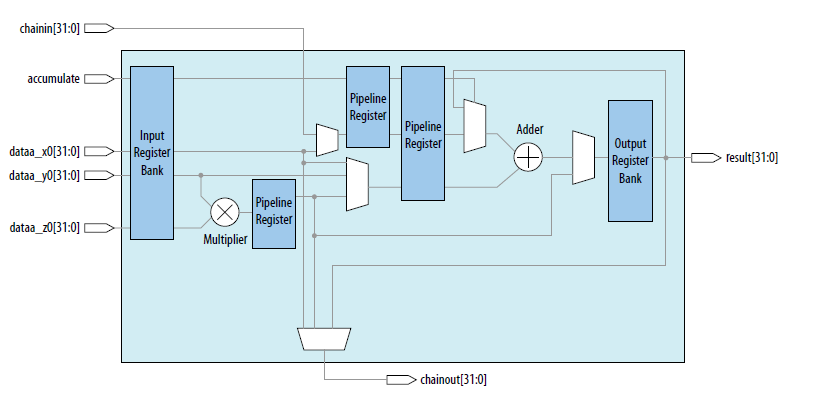
图1 硬浮点DSPblock架构
硬浮点DSP Block包含硬浮点乘法器,硬浮点加法器,支持乘累加运算,因此采用硬浮点DSPblock实现行列向量相乘是非常好的方式。下面我们针对一个实际的卷积运算,介绍如何基于INTEL硬浮点DSP block实现。假设我们需要求随机数组a=[4,8,9,11]与b=[10,5,7,13]的卷积运算结果,则根据上面的分析,保持数组a顺序不变,而数组b需根据上述分析结果,针对每一个卷积结果产生新的序列。所以整个实现包括数列重组模块和硬浮点乘法器模块及输出处理。下面是实现框图及仿真结果。
图2 实现框图
图3 Modelsim仿真结果
仿真结果与Matlab实现结果一致,并且该设计中充分考虑了FPGA并行扩展特性,对于低速率要求的设计可采用DSP Block复用的方式节约DSP block数量。
-
dsp
+关注
关注
554文章
8065浏览量
351430 -
FPGA
+关注
关注
1634文章
21821浏览量
607482 -
intel
+关注
关注
19文章
3486浏览量
186704
原文标题:基于INTEL FPGA硬浮点DSP实现卷积运算
文章出处:【微信号:ALIFPGA,微信公众号:FPGA极客空间】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA图像处理基础----实现缓存卷积窗口
FPGA中的浮点四则运算是什么
FPGA中浮点四则运算的实现过程
FPGA加速深度学习模型的案例
如何在Tensorflow中实现反卷积
图像处理中的卷积运算
FPGA实现LeNet-5卷积神经网络
卷积神经网络的实现原理
FPGA设计经验之图像处理
优秀的Verilog/FPGA开源项目-浮点运算器(FPU)介绍





 工商网监
工商网监
评论