 如何能更快地训练和部署物体检测模型?
如何能更快地训练和部署物体检测模型?
我们如何能更快地训练和部署物体检测模型?
我们已经听到了您的反馈,今天我们很高兴地宣布支持在 Cloud TPU 上训练物体检测模型,模型量化(模型离散化),同时添加了一些新模型包括 RetinaNet 和 MobileNet。利用 Cloud TPU 我 们可以用前所未有的速度训练和运行机器学习模型,您可以在 AI 博客上查看公告帖子。在这篇文章中,我们将引导您使用迁移学习在 Cloud TPU 上训练量化的宠物品种检测器。
整个过程 - 基于 Android 设备从训练到推理 - 需要 30 分钟,Google Cloud 的成本不到5美元。当你完成后,你将拥有一个 Android 应用程序(我们即将推出 iOS 相关教程),可以对狗和猫的品种进行实时检测,并且此App占用手机上的空间不超过 12Mb。请注意,除了在 Google Cloud 中训练对象检测模型之外,您还可以在自己的硬件或 Colab上进行训练。
注:Colab 链接 https://colab.research.google.com
开发环境搭建
首先,我们将安装训练以及部署模型所需的一系列库并满足一些先决条件。请注意,此过程可能比训练和部署模型本身花费更长的时间。为方便起见,您可以在此处使用 Dockerfile,它提供安装Tensorflow 所需的依赖项,并为本教程下载必要的数据集和模型。
注:Dockerfile 链接
https://github.com/tensorflow/models/blob/master/research/object_detection/dockerfiles/android/Dockerfile
如果您决定使用 Docker,则应该阅读 “Google Cloud Setup” 部分,然后跳至 “Uploading dataset to GCS”。Dockerfile 还将为 Tensorflow Lite 构建以及编译 Android 所需的依赖项。有关更多信息,请参阅随附的 README 文件。
设置 GoogleCloud
首先,在Google Cloud Console中创建一个项目,并为该项目启用结算。我们将使用 Cloud Machine Learning Engine 在 Cloud TPU 上运行我们的训练任务。ML Engine 是 Google Cloud 的 TensorFlow 托管平台,它简化了训练和部署 ML 模型的过程。要使用它,请为刚刚创建的项目启用必要的 API。
注:
Google Cloud Console 中创建一个项目 链接https://console.cloud.google.com/
启用必要的 API 链接
https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component&_ga=2.43515109.-1978295503.1509743045
其次,我们将创建一个 Google 云存储桶(Google Cloud Storage bucket),用于存储模型的训练和测试数据,以及模型检查点。请注意,本教程中的所有命令都假设您运行在 Ubuntu 系统中。对于本教程中的许多命令,来源于 Google Cloud gcloud CLI,同时我们使用 Cloud Storage gsutil CLI 与 GCS 存储桶进行交互。如果你没有安装这些,你可以在这里安装 gcloud 和 gsutil。
注:
gcloud 链接
https://cloud.google.com/sdk/docs/quickstart-debian-ubuntu
gsutil 链接
https://cloud.google.com/storage/docs/gsutil_install
运行以下命令将当前项目设置为刚创建的项目,将YOUR_PROJECT_NAME 替换为项目名称:
1 gcloud config set project YOUR_PROJECT_NAME
然后,我们将使用以下命令创建云存储桶。请注意,存储桶名称必须全局唯一。
1 gsutil mb gs://YOUR_UNIQUE_BUCKET_NAME
这可能会提示您先运行 gcloud auth login,之后您需要提供发送到浏览器的验证码。
然后设置两个环境变量以简化在本教程中使用命令的方式:
1 export PROJECT="YOUR_PROJECT_ID"
2 export YOUR_GCS_BUCKET="YOUR_UNIQUE_BUCKET_NAME"
接下来,为了让 Cloud TPU 能访问我们的项目,我们需要添加一个 TPU 特定服务帐户。首先,使用以下命令获取服务帐户的名称:
1 curl -H "Authorization: Bearer $(gcloud auth print-access-token)"
2 https://ml.googleapis.com/v1/projects/${PROJECT}:getConfig
当此命令完成时,复制 tpuServiceAccount(它看起来像 your-service-account-12345@cloud-tpu.iam.gserviceaccount.com)的值,然后将其保存为环境变量:
1 export TPU_ACCOUNT=your-service-account
最后,给您的 TPU 服务帐户授予 ml.serviceAgent 角色:
1 gcloud projects add-iam-policy-binding $PROJECT
2 --member serviceAccount:$TPU_ACCOUNT --role roles/ml.serviceAgent
安装 Tensorflow
如果您没有安装 TensorFlow,请按照此处步骤操作。为了能在设备上进行操作,您需要按照此处说明使用 Bazel 通过源代码安装 TensorFlow 。编译 TensorFlow 可能需要一段时间。如果您只想按照本教程中 Cloud TPU 训练部分进行操作,则无需从源代码编译 TensorFlow,可以通过 pip,Anaconda 等工具直接安装已发布的版本。
注:步骤操作 链接 https://www.tensorflow.org/install/
安装 TensorFlow 对象检测
如果这是您第一次使用 TensorFlow 对象检测,我们将非常欢迎您的首次尝试! 要安装它,请按照此处说明进行操作。
注:说明 链接
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md
一旦对象检测安装完毕,请务必通过运行以下命令来测试是否安装成功:
1 python object_detection/builders/model_builder_test.py
如果安装成功,您应该看到以下输出:
1 Ran 18 tests in 0.079s
2
3 OK
设置数据集
为了简单起见,我们将使用上一篇文章中相同宠物品种数据集。该数据集包括大约 7,400 张图像,涉及 37 种不同品种的猫和狗。每个图像都有一个关联的注释文件,其中包括特定宠物在图像中所在的边界框坐标。我们无法直接将这些图像和注释提供给我们的模型; 所以我们需要将它们转换为模型可以理解的格式。为此,我们将使用 TFRecord 格式。
为了直接深入到训练环节,我们公开了文件 pet_faces_train.record 和 pet_faces_val.record,点击此处这里公开。您可以使用公共 TFRecord 文件,或者如果您想自己生成它们,请按照此处的步骤操作。
注:这里公开 链接
http://download.tensorflow.org/models/object_detection/pet_faces_tfrecord.tar.gz
您可以使用以下命令下载并解压缩公共 TFRecord 文件:
1 mkdir /tmp/pet_faces_tfrecord/
2 cd /tmp/pet_faces_tfrecord/
3curl "http://download.tensorflow.org/models/object_detection/pet_faces_tfrecord.tar.gz" | tar x*** -
请注意,这些 TFRecord 文件是分片的,因此一旦提取它们,您将拥有 10个 pet_faces_train.record 文件和 10 个 pet_faces_val.record 文件。
上传数据集到 GCS
一旦获得 TFRecord 文件后,将它们复制到 GCS 存储桶的data子目录下:
1 gsutil -m cp -r /tmp/pet_faces_tfrecord/pet_faces* gs://${YOUR_GCS_BUCKET}/data/
使用 GCS 中的 TFRecord 文件,并切换到本地计算机的 models/research 目录。接下来,您将在 GCS 存储桶中添加该 pet_label_map.pbtxt 文件。我们将要检测的 37 个宠物品种一一映射到整数,以便我们的模型可以理解它们。最后,从 models/research 目录运行以下命令:
1 gsutil cp object_detection/data/pet_label_map.pbtxt gs://${YOUR_GCS_BUCKET}/data/pet_label_map.pbtxt
此时,在 GCS 存储桶的 data 子目录中有 21 个文件:其中 20 个分片 TFRecord 文件用于训练和测试,以及一个标签映射文件。
使用 SSD MobileNet 检查点进行迁移学习
为了能识别宠物品种,我们需要利用大量的图片以及花费数小时或数天的时间从头开始训练模型。为了加快这一速度,我们可以利用迁移学习,采用基于大量数据上训练的模型权重来执行类似的任务,然后在我们自己的数据上训练模型,对预训练模型的图层进行微调。
为了识别图像中的各种物体,我们需要训练大量的模型。我们可以使用这些训练模型中的检查点,然后将它们应用于我们的自定义对象检测任务。这种方式是可行的,因为对于机器而言,识别包含基本对象(如桌子,椅子或猫)图像中的像素与识别包含特定宠物品种图像中的像素没有太大区别。
针对这个例子,我们将 SSD 与 MobileNe t结合使用,MobileNet 是一种针对移动设备进行优化的对象检测模型。首先,下载并提取已在 COCO 数据集上预先训练的最新 MobileNet 检查点。要查看 Object Detection API 支持的所有模型的列表,请查看 model zoo。
注:最新 MobileNet 检查点 链接
http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
一旦成功解压缩检查点后,将 3 个文件复制到 GCS 存储桶中。运行以下命令下载检查点并将其复制到存储桶中:
1 cd /tmp
2 curl -O http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
3 tar x*** ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03.tar.gz
4
5gsutil cp /tmp/ssd_mobilenet_v1_0.75_depth_300x300_coco14_sync_2018_07_03/model.ckpt.* gs://${YOUR_GCS_BUCKET}/data/
当我们训练模型时,将使用这些检查点作为训练的起点。现在,您的 GCS 存储桶中应该有 24 个文件。目前我们已经准备好开始训练任务,但我们需要一种方法来告诉 ML Engine 我们的数据和模型检查点的位置。我们将使用配置文件执行此操作,我们将在下一步中设置该配置文件。我们的配置文件为我们的模型提供了超参数,训练数据的文件路径,测试数据和初始模型检查点。
在 Cloud ML Engine 上使用 Cloud TPU 训练量化模型
机器学习模型有两个不同的计算组件:训练和推理。在此示例中,我们利用 Cloud TPU 来加速训练。我们在配置文件中对 Cloud TPU 进行设置。
在 Cloud TPU 上进行训练时,可以使用更大的批量大小,因为它们可以更轻松地处理大型数据集(在您自己的数据集上试验批量大小时,请确保使用 8 的倍数,因为数据需要均匀分配到 Cloud TPU)。在我们的模型上使用更大的批量大小,可以减少训练步骤的数量(在本例中我们使用 2000)。
针对于此训练任务的焦点损失函数也适用于 Cloud TPU,损失函数在配置文件中的定义如下所示:
1 loss {
2 classification_loss {
3 weighted_sigmoid_focal {
4 alpha: 0.75,
5 gamma: 2.0
6 }
7 }
损失函数用于计算数据集中每个示例的损失,然后对其进行重新计算,为错误分类的示例分配更多的相对权重。与其他训练任务中使用的挖掘操作相比,此逻辑更适合 Cloud TPU。你可以在 Lin 等人中阅读更多关于损失函数的内容(2017)。
初始化预训练模型检查点然后添加我们自己的训练数据的过程称为迁移学习。配置中的以下几行告诉我们的模型,我们将从预先训练的检查点开始进行转移学习。
1 fine_tune_checkpoint: "gs://your-bucket/data/model.ckpt"
2 fine_tune_checkpoint_type: "detection"
我们还需要考虑我们的模型在经过训练后如何使用。假设我们的宠物探测器成为全球热门,深受广大动物爱好者喜爱,并在宠物商店随处可见。我们需要采用一种可扩展、低延迟的方式处理这些推理请求。机器学习模型的输出是一个二进制文件,其中包含我们模型的训练权重,这些文件通常非常大,但由于我们需要直接在移动设备上部署此模型,所以需要此二进制文件尽可能小。
这就是模型量化的用武之地。利用量化技术我们可以将模型中的权重压缩为 8-bit 的定点表示。配置文件中的以下几行将生成量化模型:
1 graph_rewriter {
2 quantization {
3 delay: 1800
4 activation_bits: 8
5 weight_bits: 8
6 }
7 }
通常经过量化,模型将在切换到量化训练之前按一定数量的步骤进行全方位精度训练。配置文件中的 delay 参数告诉 ML Engine 在 1800 步训练步骤之后开始量化权重并激活。
为了告诉 ML Engine 训练和测试文件以及模型检查点的位置,您需要在我们为您创建的配置文件中更新几行以指向您的存储桶。 从 research 目录中,找到文件 object_detection/samples/configs/ssd_mobilenet_v1_0.75_depth_quantized_300x300_pets_sync.config。将所有 PATH_TO_BE_CONFIGURED 字符串更新为 GCS 存储桶中 data 目录的绝对路径。
例如,train_input_reade r 配置部分将如下所示(确保 YOUR_GCS_BUCKET 为您的存储桶的名称):
1 train_input_reader: {
2 tf_record_input_reader {
3 input_path: "gs://YOUR_GCS_BUCKET/data/pet_faces_train*"
4 }
5 label_map_path: "gs://YOUR_GCS_BUCKET/data/pet_label_map.pbtxt"
6 }
然后将此量化配置文件复制到您的 GCS 存储桶中:
1 gsutil cp object_detection/samples/configs/ssd_mobilenet_v1_0.75_depth_quantized_300x300_pets_sync.config gs://${YOUR_GCS_BUCKET}/data/pipeline.config
在我们启动 Cloud ML Engine 的训练工作之前,我们需要打包 Object Detection API,pycocotools 和 TF Slim。我们可以使用以下命令执行此操作(从 research / 目录运行此命令,并注意括号是命令的一部分):
1 bash
2 object_detection/dataset_tools/create_pycocotools_package.sh /tmp/pycocotools
python setup.py sdist
3 (cd slim && python setup.py sdist)
至此,我们已经准备好开始训练我们的模型了!要启动训练,请运行以下 gcloud 命令:
1 gcloud ml-engine jobs submit training `whoami`_object_detection_`date +%s`
2 --job-dir=gs://${YOUR_GCS_BUCKET}/train
3 --packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz,/tmp/pycocotools/pycocotools-2.0.tar.gz
4 --module-name object_detection.model_tpu_main
5 --runtime-version 1.8
6 --scale-tier BASIC_TPU
7 --region us-central1
8 --
9 --model_dir=gs://${YOUR_GCS_BUCKET}/train
10 --tpu_zone us-central1
11 --pipeline_config_path=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
请注意,如果您收到错误消息,指出没有可用的 Cloud TPU,我们建议您在另一个区域进行重试(Cloud TPU 目前可用于 us-central1-b, us-central1-c, europe-west4-a, asia-east1-c)。
在启动训练工作之后,运行以下命令开始评估:
1 gcloud ml-engine jobs submit training `whoami`_object_detection_eval_validation_`date +%s`
2 --job-dir=gs://${YOUR_GCS_BUCKET}/train
3 --packages dist/object_detection-0.1.tar.gz,slim/dist/slim-0.1.tar.gz,/tmp/pycocotools/pycocotools-2.0.tar.gz
4 --module-name object_detection.model_main
5 --runtime-version 1.8
6 --scale-tier BASIC_GPU
7 --region us-central1
8 --
9 --model_dir=gs://${YOUR_GCS_BUCKET}/train
10 --pipeline_config_path=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
11 --checkpoint_dir=gs://${YOUR_GCS_BUCKET}/train
训练和评估都应在大约 30 分钟内完成。在运行时,您可以使用 TensorBoard 查看模型的准确性。要启动 TensorBoard,请运行以下命令:
1 tensorboard --logdir=gs://${YOUR_GCS_BUCKET}/train
请注意,您可能需要先运行 gcloud auth application-default login。
在浏览器地址栏中输入 localhost:6006,从而查看您的 TensorBoard 输出。在这里,您将看到一些常用的 ML 指标,用于分析模型的准确性。请注意,这些图表仅绘制了 2 个点,因为我们的模型是在很少的步骤中快速训练。这里的第一个点代表训练过程的早期,最后一个点显示最后一步的指标。
首先,让我们看一下 0.5 IOU(mAP @ .50IOU)平均精度的图表:
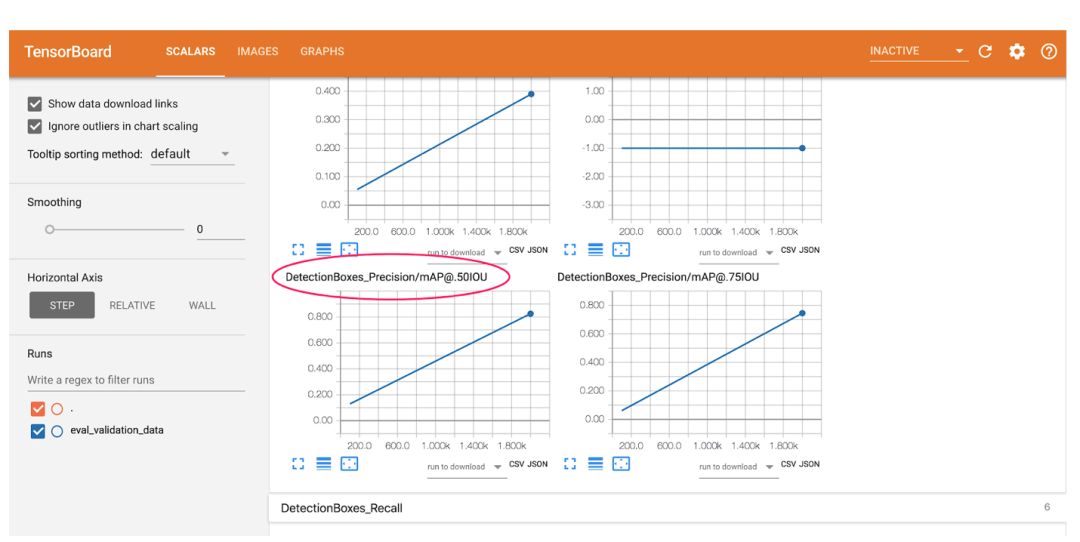
平均精度衡量模型会对所有 37 个标签的正确性预测百分比。IoU 特定于对象检测模型,代表 Intersection-over-Union。我们用百分比表示测量模型生成的边界框与地面实况边界框之间的重叠度。 此图表展示的是测量模型返回的正确边界框和标签的百分比,在这种情况下 “正确” 指的是与其对应的地面实况边界框重叠 50% 或更多。 训练后,我们的模型实现了 82% 的平均精确度。
接下来,查看 TensorBoard 中的 Images 选项卡:
在左图中,我们看到了模型对此图像的预测,在右侧我们看到了正确的地面实况框。边界框非常准确,在本案例中,我们模型的标签预测是不正确的。没有 ML 模型是完美的。
使用 TensorFlow Lite 在移动设备上运行
至此,您将拥有一个训练有素的宠物探测器,您可以使用 this Colab notebook 在零设置的情况下在浏览器中测试图像。
注:this Colab notebook 链接
https://colab.research.google.com/github/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
在手机上实时运行此模型需要一些额外的工作---在本节中,将向您展示如何使用 TensorFlow Lite 获得更小的模型,并允许您充分利用针对移动设备进行的优化操作。 TensorFlow Lite 是 TensorFlow 针对移动和嵌入式设备的轻量级解决方案。它可以在移动设备中以低延迟和较小二进制文件的方式进行机器学习推理。TensorFlow Lite 使用了许多技术,例如量化内核。
如上所述,对于本节,您需要使用提供的 Dockerfile,或者从源代码构建 TensorFlow(支持 GCP)并安装 bazel 构建工具。请注意,如果您只想在不训练模型的情况下完成本教程的第二部分,我们已为您制作了预训练的模型。
为了使这些命令更容易运行,让我们设置一些环境变量:
1 export CONFIG_FILE=gs://${YOUR_GCS_BUCKET}/data/pipeline.config
2 export CHECKPOINT_PATH=gs://${YOUR_GCS_BUCKET}/train/model.ckpt-2000
3 export OUTPUT_DIR=/tmp/tflite
我们首先获得一个 TensorFlow 冻结图,其中包含我们可以与 TensorFlow Lite 一起使用的兼容操作。首先,您需要安装这些 python 库。然后,为了获取冻结的图形,在 models/research 目录下运行脚本 export_tflite_ssd_graph.py:
1 python object_detection/export_tflite_ssd_graph.py
2--pipeline_config_path=$CONFIG_FILE
3 --trained_checkpoint_prefix=$CHECKPOINT_PATH
4 --output_directory=$OUTPUT_DIR
5 --add_postprocessing_op=true
在 / tmp / tflite 目录中,可以看到两个文件:
tflite_graph.pb 和 tflite_graph.pbtxt(样本冻结图在这里)。请注意,该 add_postprocessing 标志使模型能够利用自定义优化的后续检测处理操作,该操作可被视为替代 tf.image.non_max_suppression。请务必不要混淆 export_tflite_ssd_graph 与 export_inference_graph。这两个脚本都输出了冻结的图形: export_tflite_ssd_graph 将输出我们可以直接输入到 TensorFlow Lite 的冻结图形,并且是我们将要使用的图形。
接下来,我们将使用 TensorFlow Lite 通过优化转换器来优化模型。我们将通过以下命令将生成的冻结图形(tflite_graph.pb)转换为 TensorFlow Lite Flatbuffer 格式(detect.tflite)。
1 bazel run -c opt tensorflow/contrib/lite/toco:toco --
2 --input_file=$OUTPUT_DIR/tflite_graph.pb
3 --output_file=$OUTPUT_DIR/detect.tflite
4 --input_shapes=1,300,300,3
5 --input_arrays=normalized_input_image_tensor
6 --output_arrays='TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3'
7 --inference_type=QUANTIZED_UINT8
8 --mean_values=128
9 --std_values=128
10 --change_concat_input_ranges=false
11 --allow_custom_ops
将每个摄像机图像帧调整为 300x300 像素后,此命令采用输入张量 normalized_input_image_tensor。
量化模型的输出被命名为 'TFLite_Detection_PostProcess', 'TFLite_Detection_PostProcess:1', 'TFLite_Detection_PostProcess:2', 和 'TFLite_Detection_PostProcess:3',分别表示四个数组:detection_boxes,detection_classes,detection_scores 和 num_detections。如果运行成功,您现在应该在 / tmp / tflite 目录中看到名为 detect.tflite 的文件。 此文件包含图形和所有模型参数,可以通过 Android 设备上的 TensorFlow Lite 解释器运行,并且文件小于 4 Mb。
在 Android 设备上运行模型
要在设备上运行我们的最终模型,我们需要使用提供的 Dockerfile,或者安装 Android NDK 和 SDK。目前推荐的 Android NDK 版本为 14b ,可以在 NDK Archives 页面上找到。请注意,Bazel 的当前版本与 NDK 15 及更高版本不兼容。Android SDK 和构建工具可以单独下载,也可以作为 Android Studio 的一部分使用。为了编译 TensorFlow Lite Android Demo,构建工具需要 API > = 23(但它将在 API > = 21 的设备上运行)。其他详细信息可在 TensorFlow Lite Android App 页面上找到。
在尝试获得刚训练的宠物模型之前,首先运行带有默认模型的演示应用程序,该模型是在 COCO 数据集上训练的。要编译演示应用程序,请从 tensorflow 目录下运行此 bazel 命令:
1 bazel build -c opt --config=android_arm{,64} --cxxopt='--std=c++11'
2 //tensorflow/contrib/lite/examples/android:tflite_demo
上面的 apk 针对 64 位架构而编译。为了支持 32 位架构,可以修改编译参数为 -- config=android_arm。现在可以通过 Android Debug Bridge(adb)在支持调试模式的 Android 手机上安装演示:
1 adb install bazel-bin/tensorflow/contrib/lite/examples/android/tflite_demo.apk
尝试启动该应用程序(称为 TFLDetect)并将相机对准人,家具,汽车,宠物等。您将在检测到的对象周围看到带有标签的框。此应用程序使用 COCO 数据集进行训练。
一旦成功运行通用检测器,将其替换为您的定制宠物检测器将会非常简单。我们需要做的就是将应用程序指向我们新的 detect.tflite 文件,并为其指定新标签的名称。具体来说,我们将使用以下命令将 TensorFlow Lite Flatbuffer 资源复制到 app assets 目录:
1 cp /tmp/tflite/detect.tflite
2 tensorflow/contrib/lite/examples/android/app/src/main/assets
我们现在将编辑 BUILD 文件以指向新模型。首先,在目录 tensorflow / contrib / lite / examples / android / 中打开 BUILD 文件。然后找到 assets section,并将该行 “@tflite_mobilenet_ssd_quant//:detect.tflite” (默认情况下指向 COCO 预训练模型)替换为您的 TFLite 宠物模型路径(“ //tensorflow/contrib/lite/examples/android/app/src/main/assets:detect.tflite”) 。最后,更改 assets section 的最后一行以使用新的标签映射。如下所示:
1 assets = [
2 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:labels_mobilenet_quant_v1_224.txt",
3 "@tflite_mobilenet//:mobilenet_quant_v1_224.tflite",
4 "@tflite_conv_actions_frozen//:conv_actions_frozen.tflite",
5 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:conv_actions_labels.txt",
6 "@tflite_mobilenet_ssd//:mobilenet_ssd.tflite",
7 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:detect.tflite",
8 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:box_priors.txt",
9 "//tensorflow/contrib/lite/examples/android/app/src/main/assets:pets_labels_list.txt",
10 ],
我们还需要告诉我们的应用程序使用新的标签映射。为此,在文本编辑器中打开 tensorflow / contrib / lite / examples / android / app / src / main / java / org / tensorflow / demo / DetectorActivity.java 文件,并找到变量 TF_OD_API_LABELS_FILE。更新此变量为:“ file:///android_asset/pets_labels_list.txt”,以指向您的宠物标签映射文件。请注意,为了方便操作,我们已经制作了 pets_labels_list.txt 文件。
DetectorActivity.java 修改如下所示:
1 // Configuration values for the prepackaged SSD model.
2 private static final int TF_OD_API_INPUT_SIZE = 300;
private static final boolean TF_OD_API_IS_QUANTIZED = true;
3 private static final String TF_OD_API_MODEL_FILE = "detect.tflite";
4 private static final String TF_OD_API_LABELS_FILE = "file:///android_asset/pets_labels_list.txt";
一旦我们复制完 TensorFlow Lite 文件并编辑 BUILD 和 DetectorActivity.java 文件后,可以使用以下命令重新编译并安装应用程序:
1 bazel build -c opt --config=android_arm{,64} --cxxopt='--std=c++11'
2 //tensorflow/contrib/lite/examples/android:tflite_demo
3 adb install -r bazel-bin/tensorflow/contrib/lite/examples/android/tflite_demo.apk
现在到了见证奇迹的时刻:找到离您最近的阿猫阿狗,试着去检测它们吧。
-
Android
+关注
关注
12文章
3935浏览量
127363 -
Google
+关注
关注
5文章
1762浏览量
57515 -
TPU
+关注
关注
0文章
141浏览量
20721
原文标题:使用 Cloud TPU 在 30 分钟内训练并部署实时移动物体探测器
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
华为云ModelArts入门开发(完成物体分类、物体检测)

AI模型部署边缘设备的奇妙之旅:目标检测模型
设计一个红外物体检测设备
部署基于嵌入的机器学习模型
基于运动估计的运动物体检测技术研究
自动化所在视觉物体检测与识别领域取得系列进展
Google发布新API,支持训练更小更快的AI模型
传统检测、深度神经网络框架、检测技术的物体检测算法全概述
华为物体检测系统助力智慧安防
使用跨界模型Transformer来做物体检测!







 工商网监
工商网监
评论