 深度学习在NLP中的发展和应用
深度学习在NLP中的发展和应用
近年来,深度学习方法极大的推动了自然语言处理领域的发展。几乎在所有的 NLP 任务上我们都能看到深度学习技术的应用,并且在很多的任务上,深度学习方法的表现大大超过了传统方法。可以说,深度学习方法给 NLP 带来了一场重要的变革。
我们近期邀请到了微信模式识别中心的高级研究员张金超博士,他毕业于中国科学院计算技术研究所,研究方向是自然语言处理、深度学习,以及对话系统。
在本次公开课上,他全面而具体地讲述了深度学习在 NLP 中的发展和应用,内容主要分为以下四大篇章:
自然语言处理的基本概念和任务
深度学习方法如何来解决 NLP
对话和机器翻译当中的深度学习模型和一些云端应用,以及使用实例
对 NLP 感兴趣的开发者提供一些技能进阶的建议
以下为公开课内容实录,人工智能头条整理。
一、自然语言处理的基本概念和任务
▌1.基本概念
首先讲一下自然语言处理的基本概念和任务,这一块讲解的目的是让大家对自然语言处理这个领域有一个非常框图的认识,要,就是说知道自然语言处理的目标是什么,任务是什么,主要的方法大概有哪些。
Natural Language Processing,缩写是 NLP,主要是指说我们借助于计算技术,来对人类的自然语言进行分析、理解,还有生成的一个过程。现在大家比较常见的两个具体应用的场景,一个就是对话机器人(Chatbot),比如 AI 音箱之类的,大家可以跟它做一些对话交流。还有然后是机器翻译,大家可能平时会用用的比较多一些提供翻译功能的网站,就是我们用一些网页提供翻译的功能,这两个就是自然语言处理比较经典的任务。
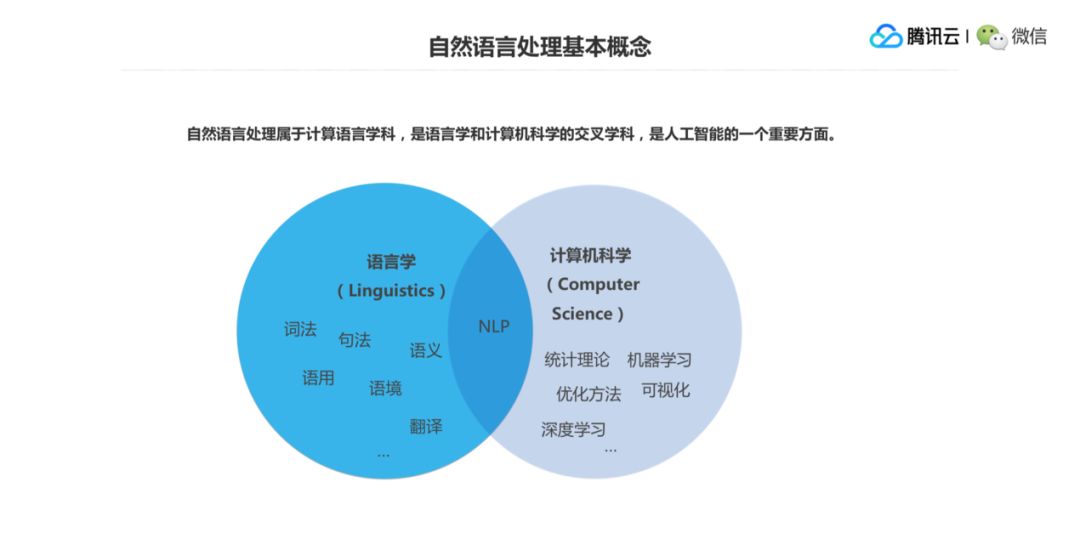
自然语言处理其实是语言学和计算机科学的交叉学科,语言学方面主要涉及到词法、句法、语用、语义等等,语言学家他们会语言学理论去研究。计算机科学方面会涉及到统计理论、机器学习、优化方法以及数据可视化、深度学习等,它们两个交叉起来叫做计算语言学,即也就是说以计算的方法来处理语言。
关于自然语言处理任务的重要性大家可以想一下,一方面语言是人类一个长期进化来的能力,是人类自然的一种交互方式,所以假如机器能够非常准确、全面地理解我们的语义,那么人机交互的方式肯定会发生一个非常革命性的变化。,但现在自然语言处理能力还没有到那种个程度,我们还需要各种输入、输出设备。另一方面,人类的知识是大规模的量存储的形式是文本,包括大量的或者说是书籍,可以把它电子化成数字化的文本,针对这些海量的文本做分析处理,从而得到有价值的信息,这也需要强大的自然语言处理能力的支撑。
▌2.自然语言处理任务
自然语言处理任务大概有哪些?我个人做了一个总结,基本可以划分分为五层项任务:,词法分析、句子分析、语义层面的分析、信息抽取,顶层的任务。顶层任务就是直接面向用户,,能提供如机器翻译、对话机器人这样的产品化服务。
首先是词法分析层。第一个是分词任务,大家知道英文的文本是由空格分隔开的单词序列,但中文没有一个词和词之间没有清楚的分隔符。对于,所以说“长江是中华民族的母亲河”这个句子,如果我们拿来做自然语言处理相关分析,最小的语义单元其实就是字,字的歧义性非常高。如果,我们对它做切分的话,那么“长江”、“中华民族”,还有“母亲”、“河”这种完全可以切出来,就是句子的基本它的语义单元就变成了词的语义单元,这就是分词任务的目的。
第二个任务是新词发现,就是说我们给你很多文本,该任务我们希望发掘发现文本中的一些新词最新的一些词,比如说“活久见“、”十动然拒“、”十动然揍”这种网络热词。第三个任务是形态分析,形态分析主要针对形态丰富拉丁语系的语言。,我们给定一个词,然把后可以把里面的词干、词缀、词根等拆分出来,然后做一些形态还原、形态切分任务,然后给上面的任务提供一个更好的输入。
第四个任务是词性标注,就是说词有动词、名词之类词性,词性标注任务就是我们把每一个词的词性给标出来。另外还有还有就是拼写校正任务,应用场景就是我们在大家用文本编辑器的时候,你打错了字会被标红它会划一个红线,编辑器还能提供还会有自动纠错的功能。
第二个层面的任务然后是句子分析(Sentence Analysis)。它包括句法分析等分析任务。,句法分析包括一些浅层的句法分析和深层的句法分析,比如像组块分析就是给定你一个句子,然后我来标出里面一些名词短语或者动词短语的块。我们直接来看下面的句法树,我们怎么来看组块呢?比如前面这个 “My dog” 是 NP,NP 就是指一个名词短语,。然后我们看 S1,VP1 是一个动词短语,组块分析的目的不是想把这棵树分析出来,而是说我只是想把这个 NP 和 VP 作为一个 Chunk(组块) 给把它标注出来。
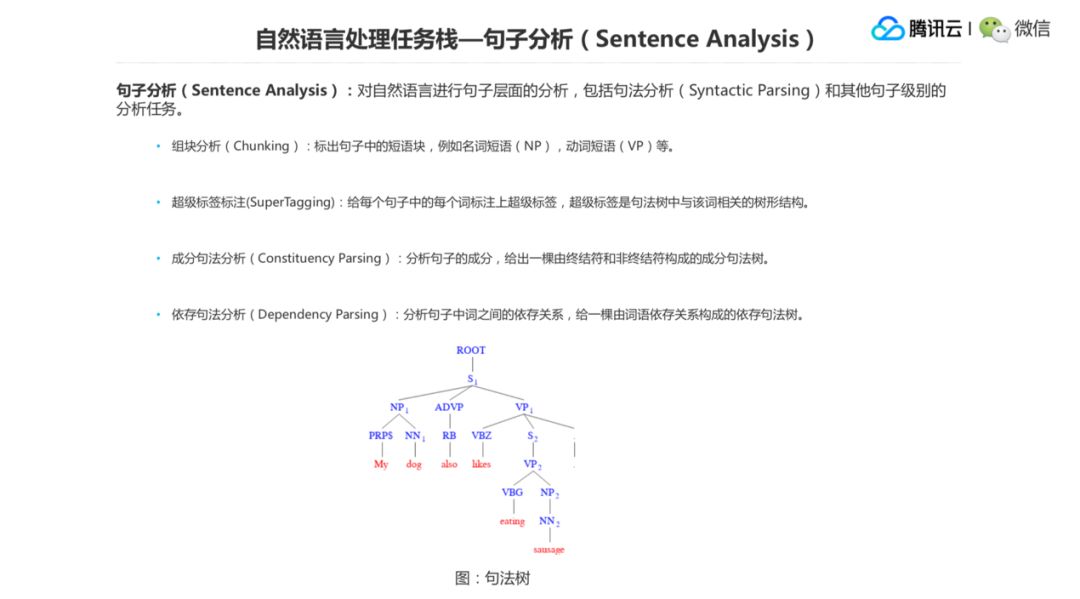
第二个任务是超级标签标注(Super Tagging),这个任务个是说我并是不想得到最后句法树的结构,我只想得到跟我这个词当前相关的树的结构。比如说我想得到 My 的这个 Super Tagg,它从 ROOT 到 My 的这一条树的路径是必须保存的,然后其他上面的一些终结符的结点会被去掉。
还有成分句法分析任务的,它的目标就是画下面这棵树,把里面句子的结构分析出来。,就是从一个根的结点出发,然后下面会有 NP、VP,到最后它必须是到一个终结符上去。
依存句法分析任务是说我来分析句子里词和词之间的依存(修饰)关系,然后由这些修饰关系来构成一棵依存的句法树。
还有语言模型任务,是就是说我们想训练设计一个模型来对语句合理的程度(流畅度)进行一个打分。
还有语种识别任务,是给定给你一段文本,我可以把它识别出这段文本成到底是用哪一个语言书写的,这可以被用到个可能用到的场景就是网页端的机器翻译任务中。
第三个任务是句子边界的检测,我们知道中文句子边界是非常明显的,会由句号、叹号或者问号等做分隔,但是对于一些语言来说,句子之间是没有明显边界的,所以做句子层面的分析之前的话,首先要对它进行句子边界的检测,比如泰语。
再往上就是语义分析(Semantic Analysis)层。从语言学家的角度来看,他想用一些结构化的一些符号来表达语义,但是现在的深度学习,大量的语义其实是分布式的表示,也就是一系列的数值,具体哪一种形式会真正地表达语义还没有定论定性。
语义分析层中的任务,第一个任务是词义消歧,一个词它可能会有歧义,该任务是来然后我们怎么来确定它准确的词义。
第二个任务是语义角色标注,是一种一个浅层的语义分析。,该任务就是说它要标出句子里面这些语义决策动作的发起者,受到动作影响的人等等。比如 “A 打了 B”,那么 A 就是一个施事,,然后 B 就是一个受事,中间就是一个打的动作。
第三个任务是抽象语义表示(Abstract Semantic Parsing),它是近几年提出的一种抽象语义的表示形式,缩写是叫 AMR。下面这个一阶谓词逻辑演算和框架语义分析基本上是语言学家一直想把语义做一个符号化推理系统的表达。
然后近期在应用里面用的比较多的语义的表现形式就是词汇、句子、段落的一个向量化表示,即Word/Sentence/Paragraph Vector,包括然后研究向量化的方法和向量性质以及应用。
这是 AMR 的一个例子,这里面有三个句子,三个句子表达的语义是一样的。就是说“这个猫想吃鱼”这个语义,有三个不同的句子表达形式,但是所以它们在 AMR 这个概念里,对应的是一个相同的 AMR 图。由于它们的语义是完全相同的,所以 AMR 分析的时候,会把一些无关紧要的词去掉,比如 the 或 to。
再高一个层面的任务就是信息抽取(Information Extraction)。比如我们给定最下面的这一段新闻,想从里面抽一些关键的信息出来,即然后就从无结构的文本当中抽取出结构化的信息,这是广义的信息抽取概念,可以比如我先做命名实体识别,我从这一段文字里识别出人名、地名、机构名,因为这些东西相比于其他的连词等标点符号具有更多的意义。
第二个任务是实体消歧,该任务是就是我把句子中出现的这个名词准确东西如何关联到现实当中的一个对象,把它 link 上去。
第三个任务是术语抽取,就是从这个文本当中抽取特定的术语。
第四个任务是共指消解。,你这个句子里面会出现了代词好多指代的东西或者是多种名词表达同一个对象的现象。,比如代词的消解是找出“他、她、它”中的某一个到底指代的是哪个事物。名词消解也是同样的道理。
然后关系抽取任务事情是确定文本当中两个实体之间的关系,比如说谁生了谁,两个实体一个是生一个是被生。
事件抽取任务是一个更复杂的过程,要就是说抽取出时间、地点、人物、发生的事件等等,这是更结构化的信息抽取。
这里信息抽取后面,我把情感分析和对话系统用到的意图识别和槽位填充也归结到这个部分里了。举个情感分析这个应用场景的例子是说,比如我们去购物网站买东西,买完了以后会给它做评价,那么用户的这个评价到底是正面的还是负面的情绪?我们需要对这个评价分析出情感倾向。
意图识别是对话系统当中一个比较重要的模块,是要分析就是说用户你跟对话机器人说话的时候这句话的目的是什么,比如说播放音乐,那么那你的意图就是音乐。
槽位填充是和意图识别搭配起来使用的,你的意图识别出来了,但是你的意图要有具体的信息,比如你的意图是让机器人帮你去定明天早上从北京到上海飞的一张机票,意图识别出来是定机票,那么要抽取一些信息的槽位槽位说时间我要抽出来,比如时间是“明天早上”,出发点是“北京”,目的地是“上海”,这样才能配合起来做后面的一些程序性的工作。
再往上就是顶层任务了,说这些任务它面向用户能够提供自然语言处理产品的一些系统级任务。一般这些任务会用到之前我们说的很多自然语言处理技术,目的是搭建一个大概是一个综合性的系统。
第一个就是机器翻译任务,就是要实现文本的一个自动翻译的过程。
文本摘要是说给定你很大段的文字,然后你把里面的梗概提取出来,把它缩短,使得然后更方便阅读或者更方便提取关键的信息。
问答任务是这样,你问你给系统一个问题,然后它能给你一个准确的答案。,比如,说你问“周杰伦的母亲叫什么名字”,这个系统它需要反馈给你一个非常准确的答案。
对话系统就是你和机器进行交互,它给你相应的反馈,执行相应的指令。阅读理解就是你给定机器输入一整篇文章,然后对它提一些与文章相关的问题,它能够给你答案,很像我们考英语阅读理解。还有再一个任务就是自动文章分级,给定一篇文章,对文章的质量进行打分或者做一个分级的操作。
▌3.自然语言处理任务的本质难点
自然语言处理任务为什么难?我的一些个人认为观点主要在于:是它的歧义问题、知识问题、离散符号计算问题,还有语义本质的问题。
先说歧义问题,有些话的表达可能会有歧义或者说模棱两可。我们上面举了几个词汇层面歧义的例子,比如我们上面这三个句子基本上是词或者字层面的歧义,“我们研究所/有东西”,这里的研究所是一个名词,“我们研究/所有东西”,这里的“研究”就变成一个动词。再往下就是一词多义的问题,第一个句子是叫“山上的杜鹃开了”,第二个是“树上有一只杜鹃在叫”,同样是杜鹃,前面说的是一种花,后面是一种鸟,这也会造成歧义。
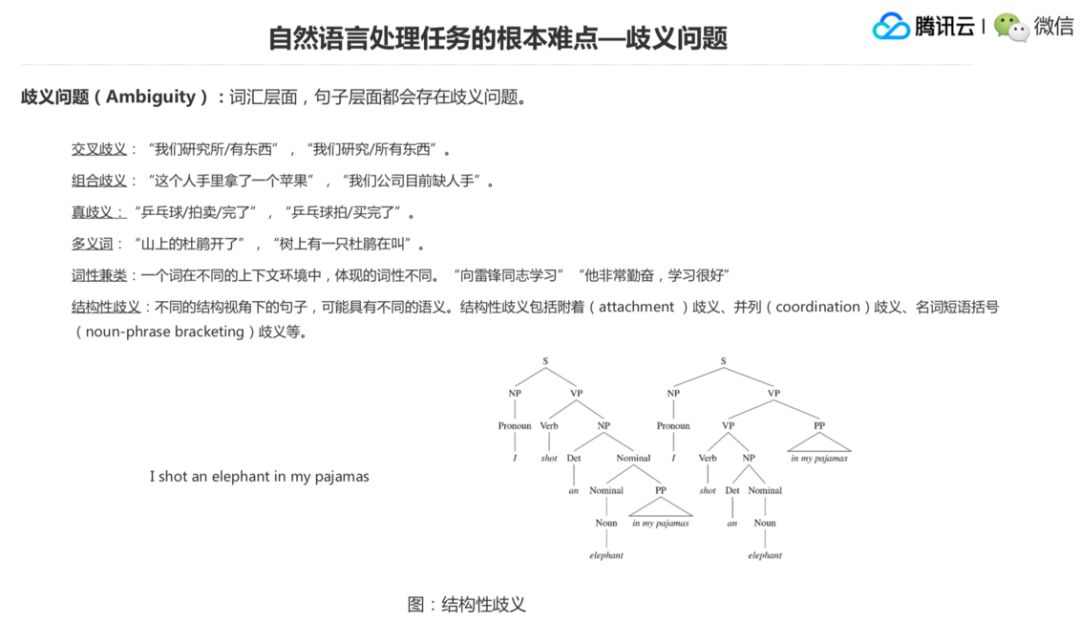
还有然后是词性兼类问题,一个词在不同的上下文环境当中体现的词性也会不同,比如说第一个句子“向雷锋同志学习”,这个学习是一个动词。第二个是“他非常勤奋,学习很好”,这个学习是一个名词,所以也会出现这种词性兼类的歧义。再一个就是结构性的歧义,分很多种,看一个比较简单的应用的例子,I shot an elephant in my pajamas,如果我们把后面这个 elephant in my pajamas 看成一个 NP 的话,这个是说“我击中了这个睡衣睡裤里面的一头大象”,这个在语义上是不对的。如果是说 in 后面的这个介词短语来修饰这个 an 的话,它翻译出来就是“我穿着我的睡衣然后击中了一头大象”,这才是合理的。
第二个是知识问题,是指就是说知识稀疏或者词汇稀疏,词汇稀疏导致了搭配稀疏,然后导致了语义稀疏,它有一个递进关系。一个比较出名的定律叫齐夫定律(Zipf Law),这个定律是说在自然语言语料当中,一个单词出现的频率和它在频率表当中的排名基本成一个反比关系。例如,对英语的 Brown 数据集里的语料进行统计,“the、of、and”是前三高的词频。
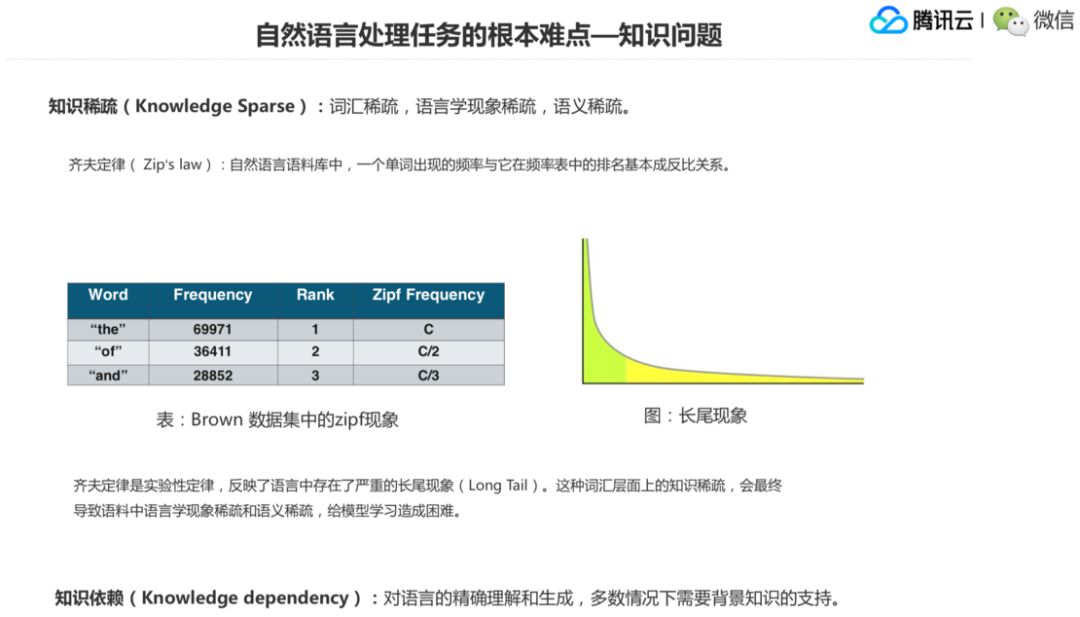
以 Zipf 的角度来看,它认为排位和词频实际上是可以用一个反比关系来对它进行建模。那么这个语料也很好地反应了基本上这个“the”大概在 7 万左右,“of”大概在 36000 左右,那就变成了 c 和 c/2 这么一个倍数的关系。然后“and”和“the”就构成了 c/3,这是一个 1/3 的关系,这是一个 Zipf 的现象,这个现象会引起这个词的 Frequency,这个词频会下降得非常快,然后后面会导致一个非常长尾的现象。,即就是说有很多词出现的次数很少,但是数量又很大,当它们全部加起来的话,又你不能把它们忽略掉。再一个问题是知识依赖,这也就是说对语言精确的理解和生成,有很多时候是需要背景知识支持的,比如“苹果”到底是一个水果还是一个手机,可能就需要有一些这种知识来支持,不能根据一句话就完全能把它理解掉。
知识稀疏的问题,从机器学习的角度来看的话,相当于你给了一个模型非常不均匀的数据分布,那对模型来说它的学习难度就会变大。
第三个是离散符号计算的问题。我们看到的文本其实都是一些符号,对计算机来说,它看的其实也是一些离散的符号,但我们知道计算机其实最擅长的去运算的实际上是数值型的运算,而不是符号之间的推理,并且符号之间的逻辑推理会非常复杂。现在在统计机器学习模型里面做的就是用one-hot,就是用一个非常稀疏的向量来表示这个词的形式,把它作为特征输到后面的模型里去,但这面临一个高维的问题。另一个是符号和符号之间都是正交的,那么就很难建立起符号之间的相关关系,这是深度学习方法能够部分解决一下这个问题。
第四个就是语义问题,到底什么是语义?什么是语义?语言里面到底是什么东西?符号背后真正的语义怎么来表示?语言学家他走的路子就是我构建好多形式化的、结构化的图之类的,这种结构去做语义或者是一些符号推导系统,认为它可以接近语义本质。但是,这些其实走得越远离计算机就越远,因为它越符号,语义的可解释性就会很差。,拿数字来表示语义,我们你也不知道这个数字到底它是什么东西。所以目前为止现在研究领域对这个问题解决得比较差。
假如语义问题真的解决了,那所有的自然语言处理任务都不是问题,但目前来说,我们现阶段做的事情实际上仅仅是需要你在去做每一个子问题的时候,把这个子问题用各种各样的方法把它做好就行了,语义的话真的是比较难解决的问题。
目前来说几乎所有的自然语言处理方法都是基于数据驱动,也就是统计机器学习的模型,那么数据质量加上模型的能力就决定了最后的任务表现,而并非是说机器真的能全面理解人类语言当中的语义,比如市面上的对话机器人很大的程度上要归于数据或者一些规则,而不是说机器真的能像人类一样地去思考、推理,然后给你一个非常人格化的回复,现阶段人工智能还没有达不到那种要求。
▌4.小结
我们大概讲了自然语言处理任务的基本概念,还有一些目前自然语言大家处理主要在解决的任务。,一般来说一个做 NLP 的人,他可能以他的能力做到里面的一个或者几个任务。自然语言处理它是一个交叉学科,它会使用语言学的理论,但是不会说去研究语言学,然后也会去用一些统计机器学习或者算法模型方面的东西,但目的又不是说我去彻底研究透算法层面的东西,而是说只是追求可用。当然现在的趋势是很多做自然语言处理的人都在深入地研究算法模型,但归根到底我们想解决自然语言处理的问题其实就是怎么对这个问题进行建模然后解决好。
二、深度学习方法解决NLP任务
▌1.自然语言处理方法的演化
下面讲一下深度学习方法和之前的方法,还有一些深度学习方法解决基本任务的介绍。
自然语言处理方法的演化大概可以这么来划分,一个是叫理性主义,后面一个叫经验主义。
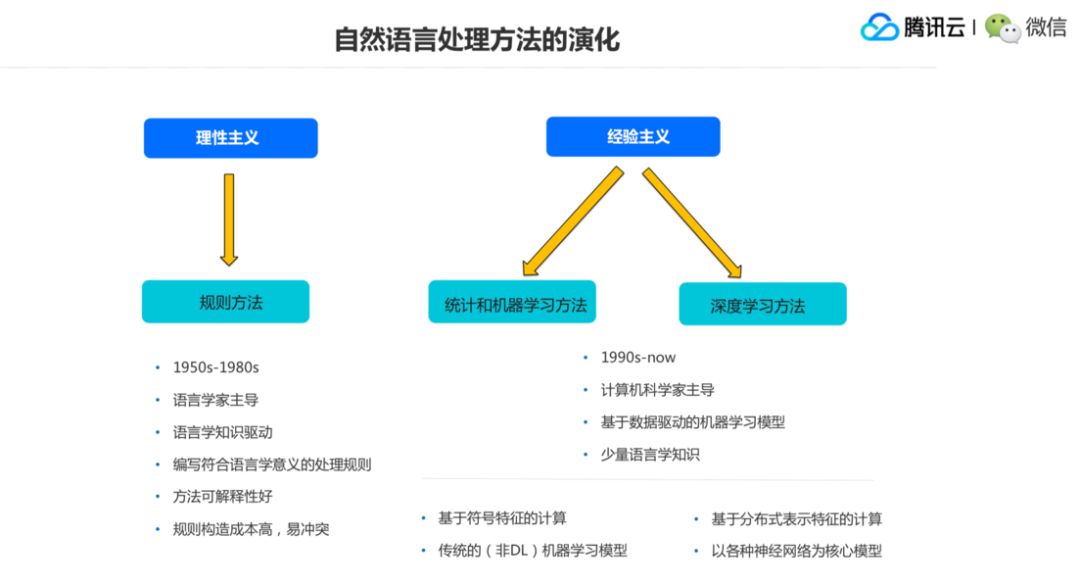
理性主义很好理解,就是写规则,然后来处理这个问题。经验主义就是加数据,加算法模型的方式来解决问题。理性主义基本上是语言学家来主导,就是研究语言,写语言学的知识,然后用这些语言学知识的规则来处理自然语言处理的任务。
这个方法的好处就是可解释性特别好,它明确知道这个输出的结果是由哪条规则产生的作用,但问题是说规则越写越多的时候,很容易前后起冲突,写规则的成本也非常高,其实对自然语言处理的理解,处理方法的演化方面会比较慢。
经验主义方法就是所有的知识都在数据里面,从数据里面学东西,不关心里面的语法规则是什么,这个研究阶段就由计算机科学家主导,主要的方法就是基于数据驱动的机器学习模型加少量的语言学知识。
经验主义里我们给它又划分成了两个阶段,一个是统计机器学习方法的阶段,它的特征一个特点是基于符号特征的计算,就是抽一些符号化的特征,然后交给机器学习模型来做。第二个特点是它一般是用传统的针对非 DL 的一些方法,比如,LR、SVM 之类的。
到了近几年,NLP主要是用深度学习方法,它的第一个特点就是分布式的表示特征,也就是拿一串数字来表示一些语义作为特征,交到后面的分类器来做。第二个特点是以各种神经网络为核心模型,而不再是以前的这种 SVM 之类其他的分类器之类的东西,这是深度学习方法两大比较突出的特征。
我们来看理性主义模型下自然语言处理的一个视角,这是一个德国研究机器翻译的一位德国教授提出的机器翻译金字塔模型,当然后面到统计的时代是大家也去借用这个模型来表达机器翻译的过程。
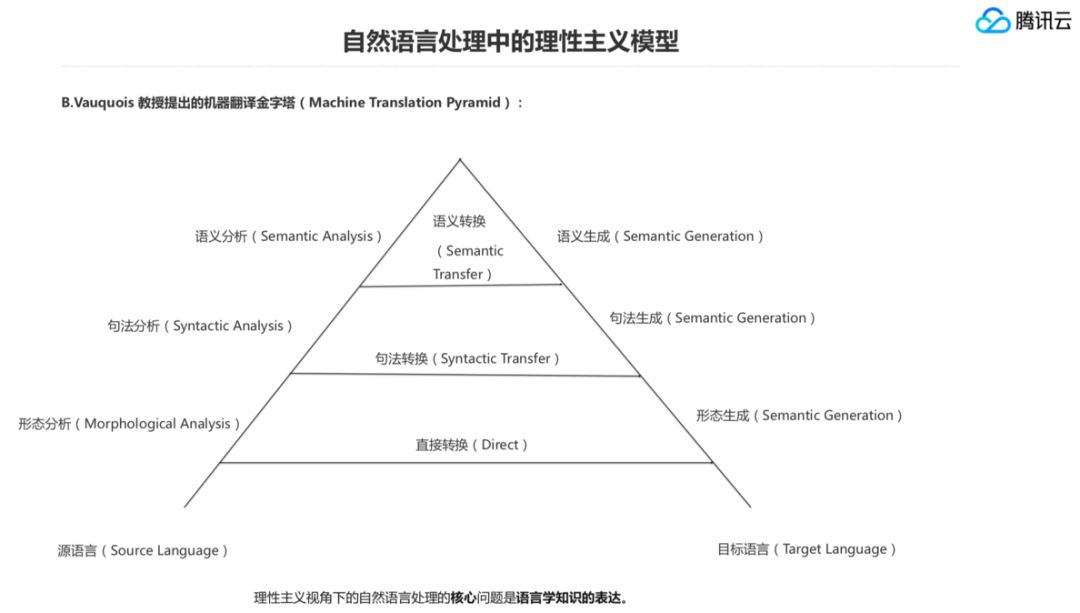
我们从这个视角看语言,要先做形态分析,然后再做句法分析,语义分析,再往上是中间语言最高的形式,然后往右边去转换,这是一个机器翻译的过程。就是说给一个源语言的句子,然后转换成目标语言的句子,那么它认为从上到下是一个递进的,从左到右是一个层层转化的过程,所以它在处理某一任务的时候也是基于语言学结构来处理,这是理性主义模型下一个非常经典的看法。
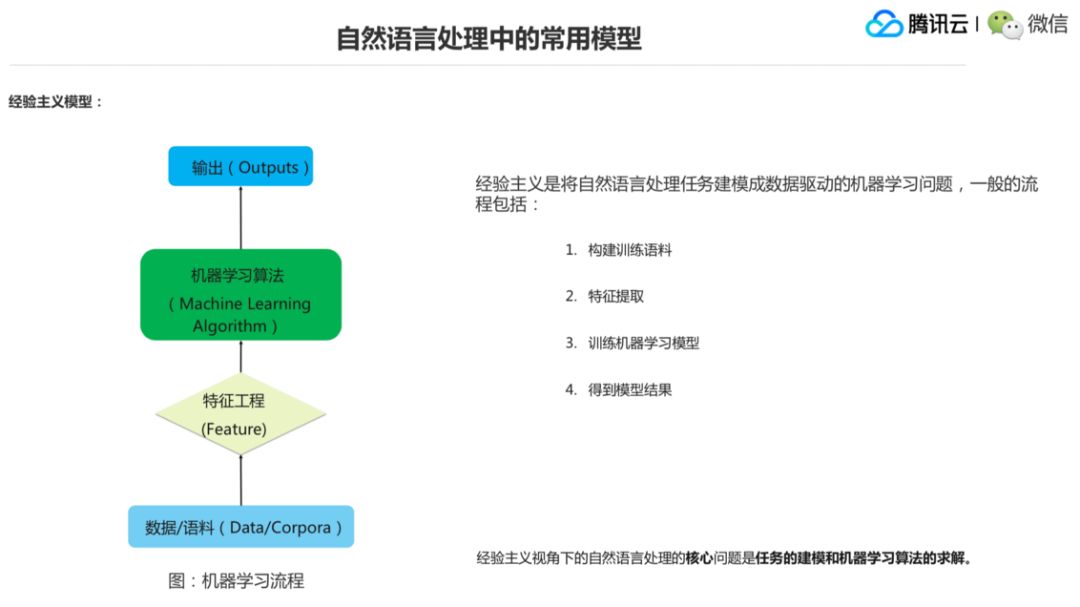
到经验主义模型基本上是这样的,其实就是一个机器学习的过程,就是先构建语料,做标注,然后再设计特征,做特征提取,然后后面是交给到机器学习算法,然后训练好模型做输出。我们说前面的阶段一个核心问题是语言学知识表达的问题,后面经验主义模型下一个核心的问题实际上是对这个任务的建模和机器学习算法的求解。
▌2.自然语言处理常用的问题模型
首先我们在这里区分两个概念,一个叫问题模型,一个叫算法模型。问题模型就是把这个任务怎么把它形式化出来,是一个建模的过程。算法模型是说怎么来拿某个算法去解决这个问题建模好的形式,就是给你一个事情,你把它分解开来,然后看看它到底能套哪个模型,然后后面就是对这个模型的求解问题。
NLP 当中常用的问题模型包括分类模型、序列标注模型和序列生成模型。
分类模型是一个比较狭义的分类概念。实际上序列标注模型和序列生成模型也可以理解成一个广义分类的问题。分类是说是指大概像文本分类或者给句子做情感分析之类的狭义的模型。
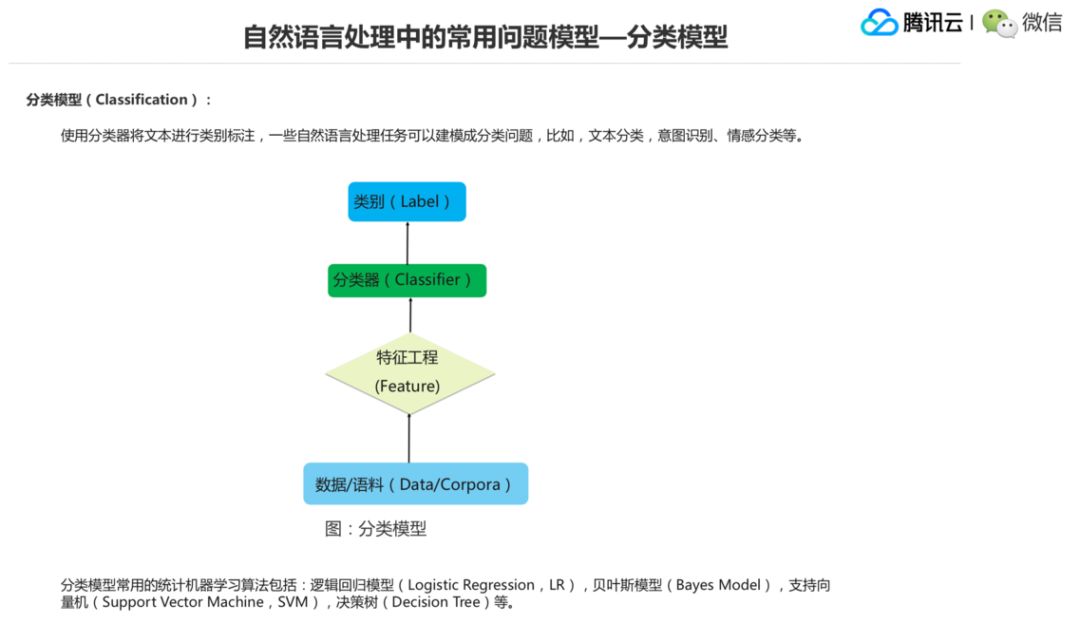
第一个分类问题就是给你一段文本做类别的标注,比如你对它进行文本分类,给你一个新闻,它到底是一个政治、体育、财经或者其他类别的新闻。那么意图识别,就是前面说到的你和一个对话机器人聊天的时候你给它一句话,然后这个机器人它能识别出来你的意图是要干嘛。情感分类的话就是前面说的你买的东西,你对它做一个评价,这是正向的还是负向的,实际上都可以抽象成问题模型里面的一个分类模型。
分类模型传统的一个解决方法就是说标带标注的语料,再特征提取,然后训分类器进行分类,然后类别。这个分类器就会用比如说逻辑回归、贝叶斯、支持向量机、决策树等等。
第二个是序列标注模型。序列标注我们拿分词这个事情来做一个比较好的举例,实际上数学建模是这样,你有 N 个 X,它构成一个序列,你可以认为它是 N 个字词,这个句子里面有 N 个字词,,然后你给每个字词加上一个标签,它生成 N 个序列的标签,那么分词这个问题就抽象成字的序列标注的模型。
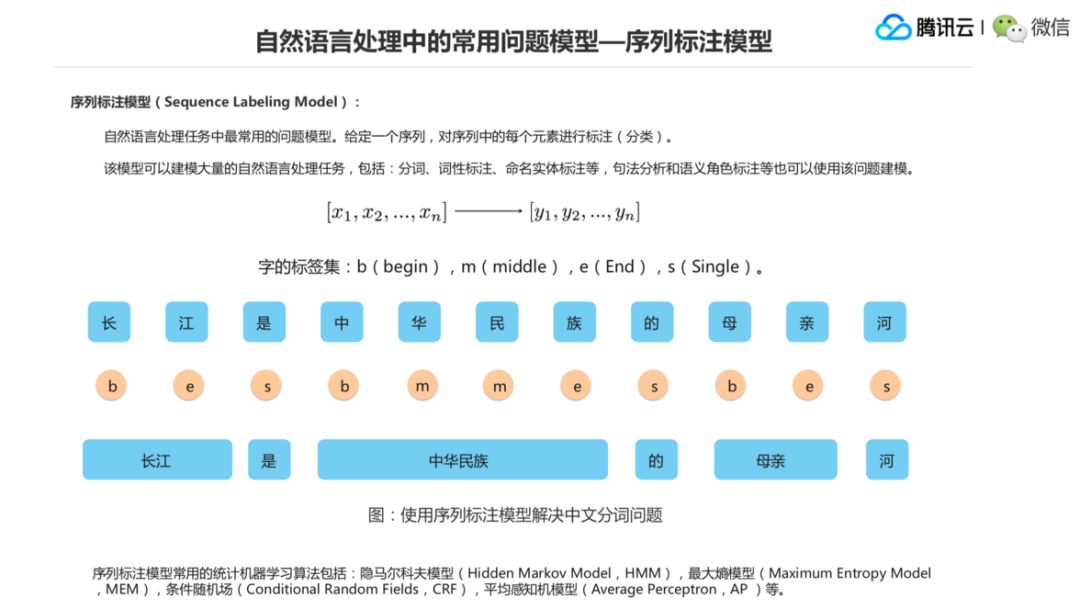
比如说“长江”它应该是构成一个词的,那么就给它分成分类的侯选标签,就是 begin、middle、end 或者 single。,这个是说 B,就是说“长江”应该在 begin 的位置,“江”应该在 end 的位置,如果它标成 b 了,它标成 e 了,很明显是它们两个字要构成一个词了。假如这个模型是标注成了 s,那就是 single,它就是自己一个词。“中华民族”这个就是 begin,middle,middle,end,那这四个合起来就是“中华民族”这一个词。
后面我们就都类似了。那么整个分词的过程,就是从上面这一行蓝色到下面这个词的蓝色的,那就是一个序列标注,你只要对每个字分类分正确了,那你分词的结果结构就是对的。
这是一个序列标注的模型,这个分词是一个非常经典的任务。词性标注、命名实体识别,甚至说现在大家做句法分析或者做语义角色标注,也开始使用这个序列标注模型来做了。那么传统做序列标注模型的一些方法,包括隐马尔科夫、最大熵、条件随机场、平均感知机等等,很多去求解这个序列标注的算法模型,是用来怎么来求解序列标注的问题的。?这两个层面上的模型我们要分开。
第三个是序列生成模型。所谓的序列生成模型就是如何生成一段文本,逐个词地来生成,使得然后生成的这个文本是合理的。怎么来评价它的合理性?如果你是单语生成的话,那么可以使用可能像语言模型,保证流畅度、合理性越高越好。
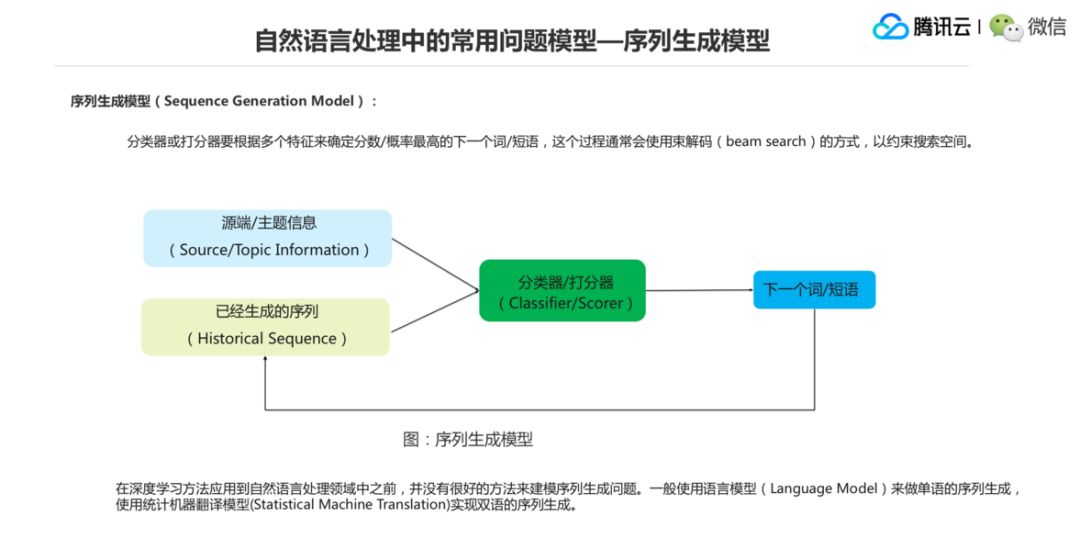
如果它是一个双语生成的任务,像机器翻译任务,你就要约束约定它跟原来的语义接近的情况下,然后生成的序列更合理。在深度学习方法出来之前,其实没有太好的方法来建模序列生成问题,一个就是这个语言模型来做单语生成,再一个就是用统计机器翻译模型来做双语生成。然后生成的过程当中基本上是要用一个束解码的方式来约束搜索空间。
▌3.统计机器学习算法模型的不足
我们前面讲的是一些统计的学习算法,比如像 SVM、LR 之类,这些算法有什么不足呢?一个就是前面需要设计一些复杂的特征,这些特征是要人工地去设一个特征模板,用这些特征模板去匹配句子里面的一些特征,把它抽出来,作为一个离散化的特征来输入到模型里面去,这一块是非常复杂的。
第二个是这个算法模型对序列建模的能力很差,这个特征在词方面都是非常稀疏的,在那么你对句子抽特征的时候这个就更稀疏了。比如整个语料当中有 1 万个不同的词,那么这个句子里非常有可能出现了一个词会只在几个句子里出现过,所以它的特征会非常稀疏。第三个就是你前面抽出特征是一步,训练模型是一步,这个其实中间会有错误的误差,甚至有一些复杂的任务,它是要去进行多步的操作,这会产生一个非常严重的错误传播问题。后面我们也会用具体的模型来解释这个错误传播的问题。
我们看一下深度学习,它可以就是我们来解决前面说的分类问题、序列标注问题、序列生成问题用到的一些基本组件,现在主要应用到的比如前向神经网络,就是一个最简单的全链接网络。循环神经网络,包括纯的 RNN,不加任何门控的 RNN,还有 LSTM,这种加门控的一些神经网络的单元。还有就是卷积神经网络,这个在图象方面用的比较多,NLP 里面也会用。再一个就是注意力机制,这些是一些深度学习的基本组件,大家有兴趣的可以自己去看公式,了解一些基本的模型。
为什么说深度学习方法比前面我们说的统计机器学习的模型要强大?我们现在来逐条分析。
▌4.强大的深度学习方法—分布式表示
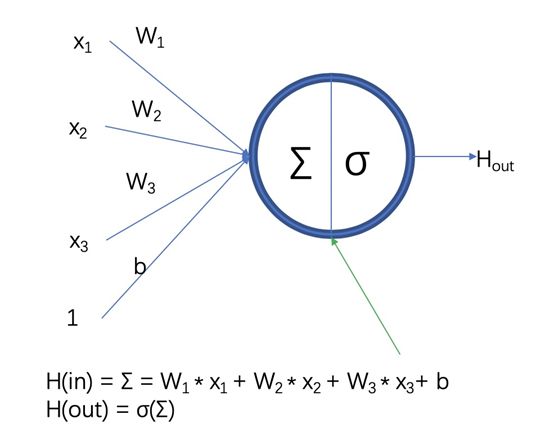
一个是分布式表示(Distributed Representation),或者更具体一点叫 Word Embedding/Word Representation 之类的。也就是拿这个数值来表示这个特征,而不再是之前的离散的特征,这是一个比较经典的任务,也就是 Bengio 提出的神经网络语言模型,他把这个词通过一个矩阵,然后通过查表的方式形式得到做成一个 Word Embedding,然后交到后面去训练这个神经网络的语言模型。,现在后面就是 NLP 所有的任务基本都基于都在 Word Embedding。
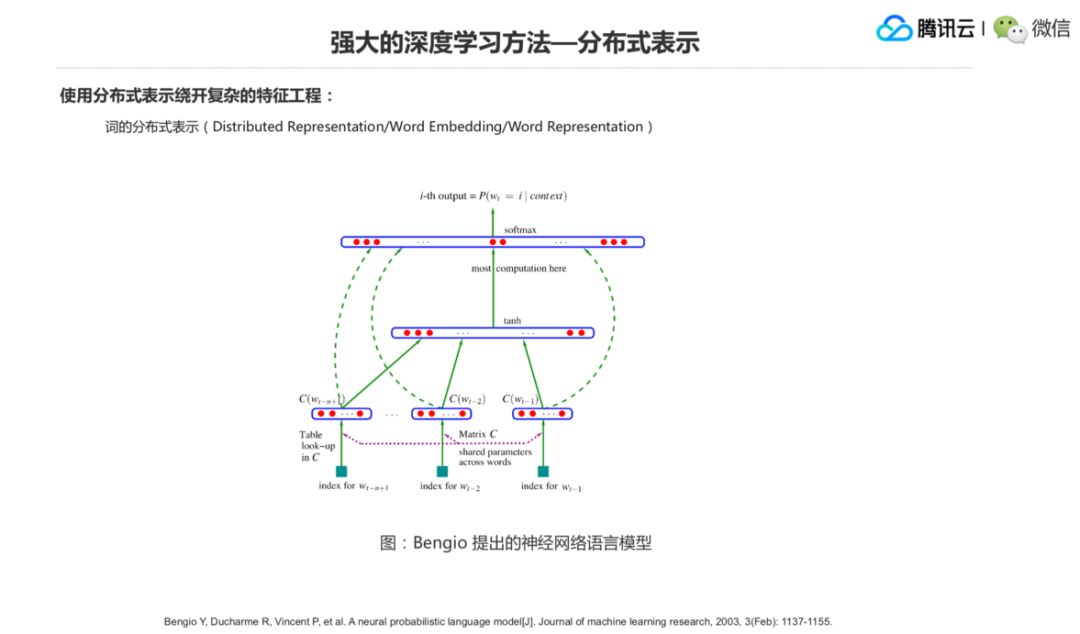
Word Embedding 这一步怎么来做?假如有 V 个词,一个词就是 W1、W2 一直到 Wv,构建一个矩阵,然后每一个词可向量的维度是 M维v,那么这个 W1 过来了以后,我查表会查到 W1 对应这一类的词向量作为它的一个表示,这个表叫 Lookup Table,这就把这个词的符号转换成一个向量的一个形式的过程。
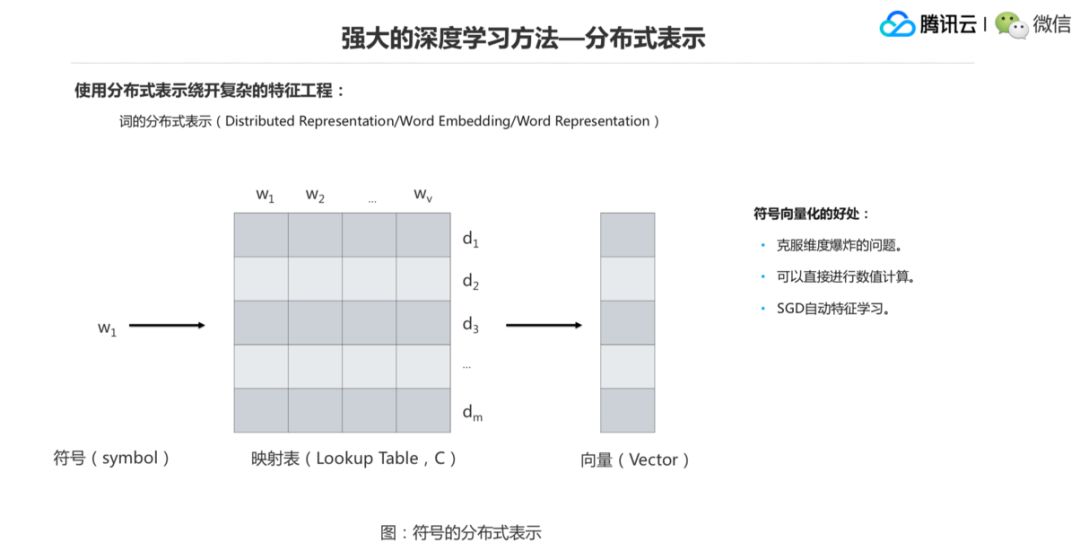
最右边这个就是它的词向量,这个词向量是在整个模型的训练中,可以通过 SGD 下降的方式给它回传做调整,也就是说我们最终得到的词向量是非常适合于这个任务的词向量,也是得到了这个任务的目标函数下这个词非常好的一个表达形式。那么符号向量化的第一个好处就是克服维度爆炸的问题,One-hot会到一个非常高的维度,但是词向量最小可以把它设成 20、50 之类的就解决掉了。再一个就是说它可以直接进行数值运算,因为它就是向量,向量就是数值,后面就交到后面做很大的矩阵运算,这完全没有问题。再一个就是 SGD 自动特征学习,这个前面我们说到了,就是 SGD 怎么去调 Word Embedding。
▌5.强大的深度学习方法—序列建模方法
深度学习方法强大的第二个优点,就是序列建模。前面说序列建模很难,在前面的一些特征设计方法里面,在深度学习里面,序列建模的方法就变得非常简单了,就是以词汇层面的分布式表示为基础,然后对词之间的交互进行计算,然后生成整个句子的一个分布式表示。整个过程都是在做计算,而不是在做特征模板的设计。
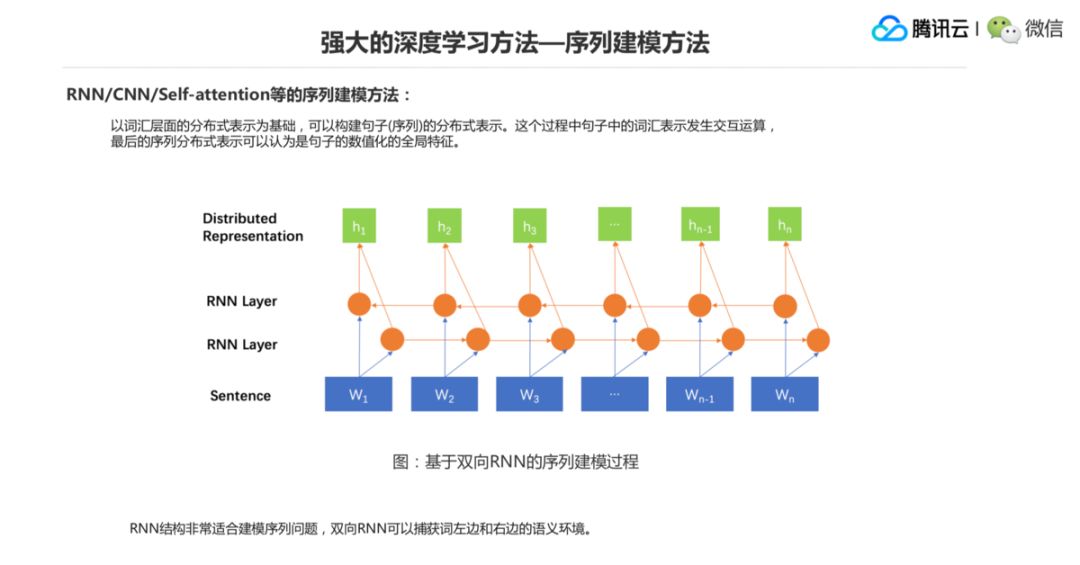
这个图是一个比较具体的基于双向 RNN 的一个序列建模模型,我们看到会有两层 RNN 层,第一层是从左向右地对词向量进行压缩表示,第二层是从右向左做压缩表示,然后两层的表示连接起来,作为最终整个句子的表示,用 N 个词,你后面生成的分布式表示就可以是 N 个向量,每个向量可以认为是它对应的下面这个词的一个上下文环境的语义表示,作为整个句子的特征。也可以用最后面一个,就用 Hn 也可以表示一个句子的特征,也可以把这些东西作为一个句子特征的表示。也就是说这个地方你用神经网络的方式直接基于词做计算得到句子的特征表示,就绕过了特征模板,非常方便。
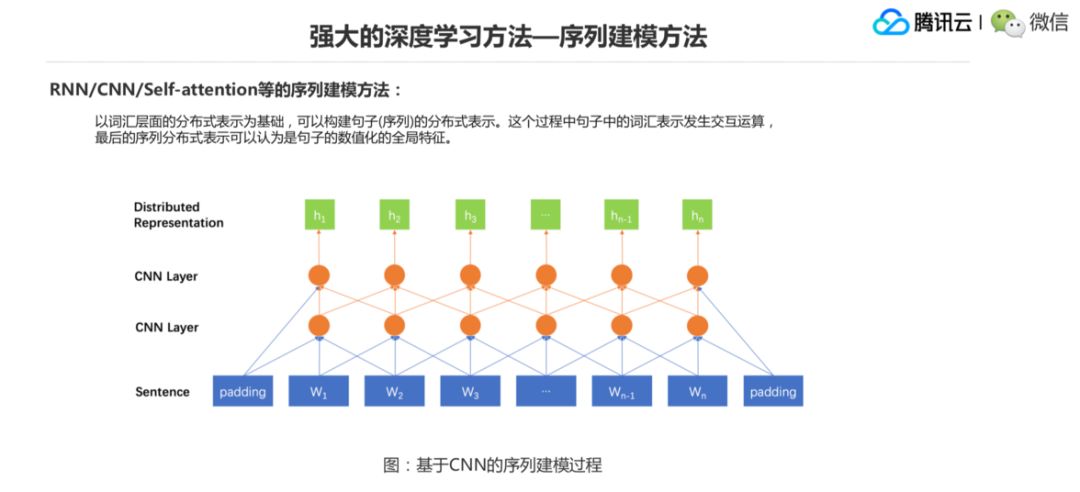
这是基于 CNN 的序列建模的一个方法,CNN就是一个窗口,把一个词通过不同的权重做加和,然后形成一个表示。第二层也是一个窗口,这样一层层上去以后,越上面的一些 CNN 的结点它覆盖的词的范围就越大。实际上到最上面这一层绿色的表示,也可以认为跟前面那个模型一样,就是作为整个句子的一个特征表示,然后结合后面的任务就好了。
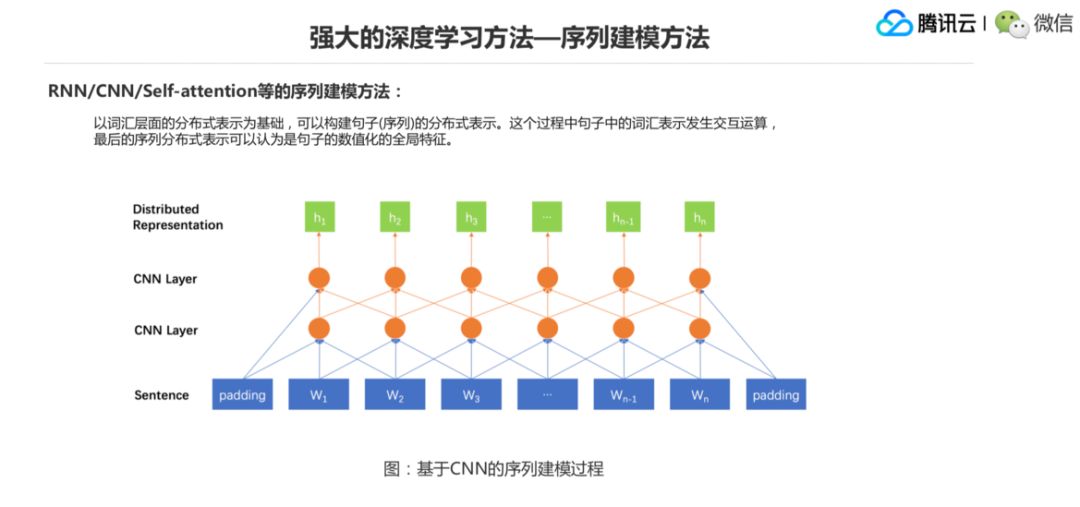
在最近的工作有就是基于 Self-Attention 的这种序列建模方式,在 W1 生成 H1 的过程中它需要参考所有句子里面的词,然后计算和所有词的一个相关程度,决定其他所有词在最终形成它的表示的过程中所占的权重比例。这个话有点绕,就是像前面的这些模型,W1 生成 H1 的时候,它可能只是一个局部窗口,只考虑一个局部范围跟它交互的一些词的范围,在 Self-Attention 里面,它要考虑跟它所有词的关系,然后来构成最终的一个表示。
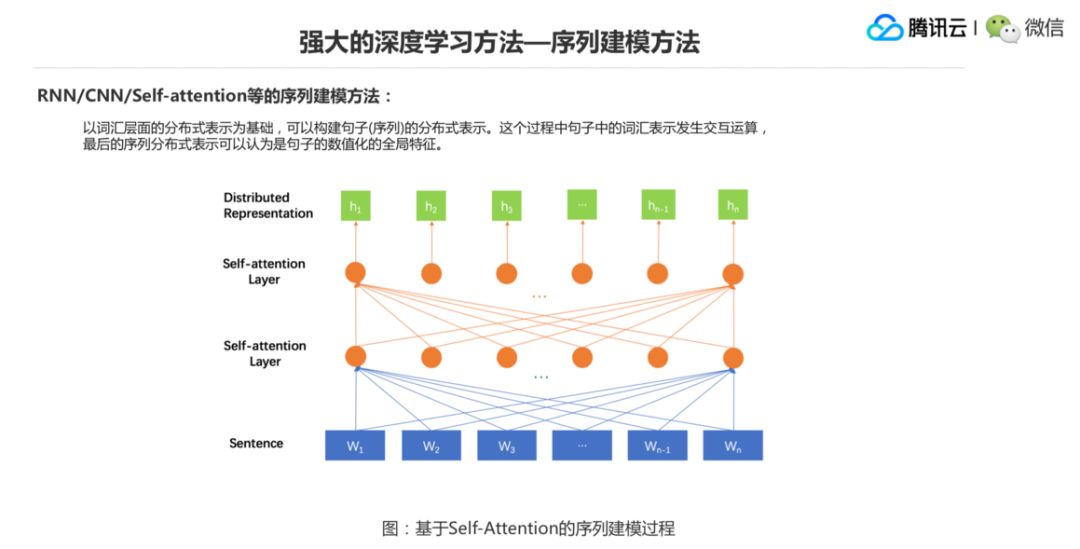
▌6.强大的深度学习方法—参数统一优化
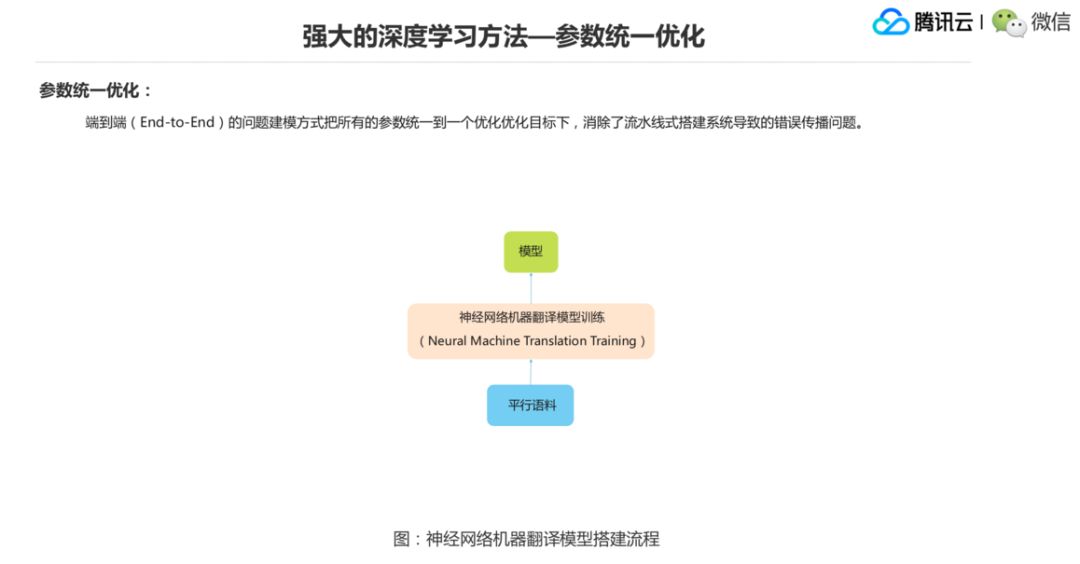
第三个深度学习方法强大的一个优点就是参数统一优化的问题。之前我们说前面设计特征模板,后面交一个分类分离器,更严重的就是搭一个系统的时候需要做很多步的模型搭建,比如传统的统计机器翻译里面有一个短语模型的搭建流程,我有语料,然后我先要做词对齐,然后在词对齐的结果上抽短语,抽完短语以后做短语特征方面的抽取。
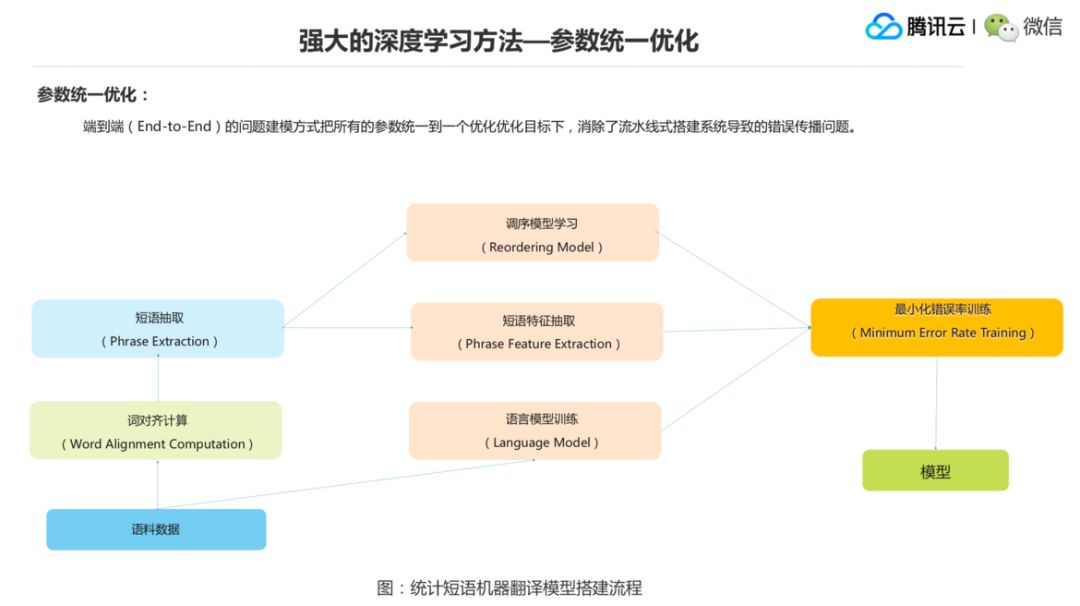
在短语这个层面还要学一个调序模型,在语料这个层面上其实还需要学一个语言模型,这些模型最后加一块来融合,达到最后的模型,但实际上中间这些模型训练的时候都是非常独立的,有一些递进的关系,然后就会出现一个错误传播的问题,这些所有的参数并不是统计到一个优化目标函数下去训练的,但深度学习方法里,尤其 End-to-End 这个模型,就是能把所有的参数统一到一个优化目标函数下去缓解这种传统的系统搭建方法的一个错误传播的问题。这是一个基于统计的短语机器翻译系统的一个搭建流程。
然后我们看一下基于神经网络的机器翻译模型搭建的过程。下面有平行语料,就交到这个模型里面去训练,结果模型会有一个优化函数,最后能得到这个模型,整个这个模型来建模平行语料里的翻译知识。具体怎么来做,后面我们会有更加详细的介绍。这里想表达的是深度学习方法,可以把所有的参数做统一优化。
我们来看一下前面提到自然语言处理中提到了三个问题的不良语言处理里面提到了单个问题模型,一个叫分类,一个叫序列标注,另一个叫序列生成。在传统的方法下我们看过了它们是怎么来做的。?比如,前面做特征模板设计,后面接分类器,像决策树、SVM、LR 之类的分类器来做。那到了神经网络或者说深度学习时代,这个事情怎么解决?其实底层还是基于特征抽取的一个过程。
看这个图,大家应该看到除了上面橙黄色的这个点,就是前面我们说的一个特征抽取的过程,一个双向 RNN 来抽取一定特征的一个过程。对这个句子特征抽取完了以后,接一个橙黄色的分类器,后面输一个 Softmax,然后输出哪个类别的概率,那就是用这种方法来建模一个分类问题。
比如情感分析问题,或者说一个文本分类问题,你就把句子交到这个神经网络去,然后神经网络把特征抽完了,后面接一个分类的过程,,然后整个的优化都是基于上面这个分类的准确程度来做梯度回传,回传到每一条连接权重,还有词向量上面去,所以整个系统它是一个模型,所有的参数同时在做优化,不存在特征模板的问题,所以就是能够很好地解决分类问题。, 还有序列生成和序列标注的问题。
这是一个序列标注的问题,就是前面说到分词的问题,就是给每一个字加一个合适的类标。其实下面还是一样,抽特征,抽出 N 个表示出来,N 个字的表示出来,就是这些字的特征出来,然后后面每个接 Softmax 的分类器,然后做一个路径最优的寻优学优操作做一个推理,然后找到一条最优的序列路径出来。这是一个深度学习方法解决序列标注问题,
那怎么来做序列生成的问题?就是 Encoder、Decoder,这是一个非常经典的模型。Encoder 就是把原先的句子做表示,然后 Decoder 是根据这个表示来做生成。。然后 Encoder 也可以用 CNN、RNN、Self-Attention,Decoder 也可以分别用这三种。这个模型反映反应的是一个翻译的过程,翻译的过程是计算机可以处理自然语言,我们希望计算机能生成这个结果,也就是一个序列到另一个序列的映射,但是这两个序列之间可能会存在着不同的长度。这是目前大家来做机器翻译问题或者对话聊天里的闲聊通用的一个模型。
▌7.深度学习方法的缺点
我们说说深度学习方法的缺点。缺点一个是模型的可解释性低,首先它是一个数值的运算,你很难解释它每一步的数值代表了什么。,就是整个过程在算,你很难去展现它中间语言学的一些推理过程,效果会很好,但是不好解释,有人把它叫做黑盒。
再一个就是因为它都是基于数值的,所以就比较难去融入一些鲜艳符号的规则进来,这个语言学的知识或者人类的一些运行约束,很难去融入进来。再一个就是这个模型它需要的计算量比较大,有很大权重矩阵的运算,矩阵乘法,或者做 Softmax 之类的这种计算,所以需要计算的还是比较重的,尤其是训练大模型的时候,一般现在是用多显卡,最起码是多卡,或者是多机来训一个比较大的模型。
这个模型的表现除了依赖于本身的结构,它还依赖于比较多的训练技巧,所谓的训练技巧就是指说中间某些参数的初始化方法,网络的超参设计,还要加一些其他东西,比如本身就给你一个 RNN,它其实可能表现不好,但加上很多训练的方法进去,这个模型表现才会好起来。
所以有很多人说这是一个炼丹的过程,但是这个炼丹的过程到目前大家研究的也越来越透彻了,有很多分析的论文已经出来了,所以我们也希望这个模型能够可解释性更好一点,这些训练的技巧方法能够在数学上找到更好的理论,然后拿实验去验证它,而不是说我们就真的是像炼丹师一样去炼一个模型出来,这不是科学。
这章主要的内容就是介绍了自然语言处理里面常用的一些问题模型和算法模型,对比了统计机器学习方法和深度学习方法,然后分析了它们的优劣之处。
三、对话和机器翻译中的深度学习模型和云端应用
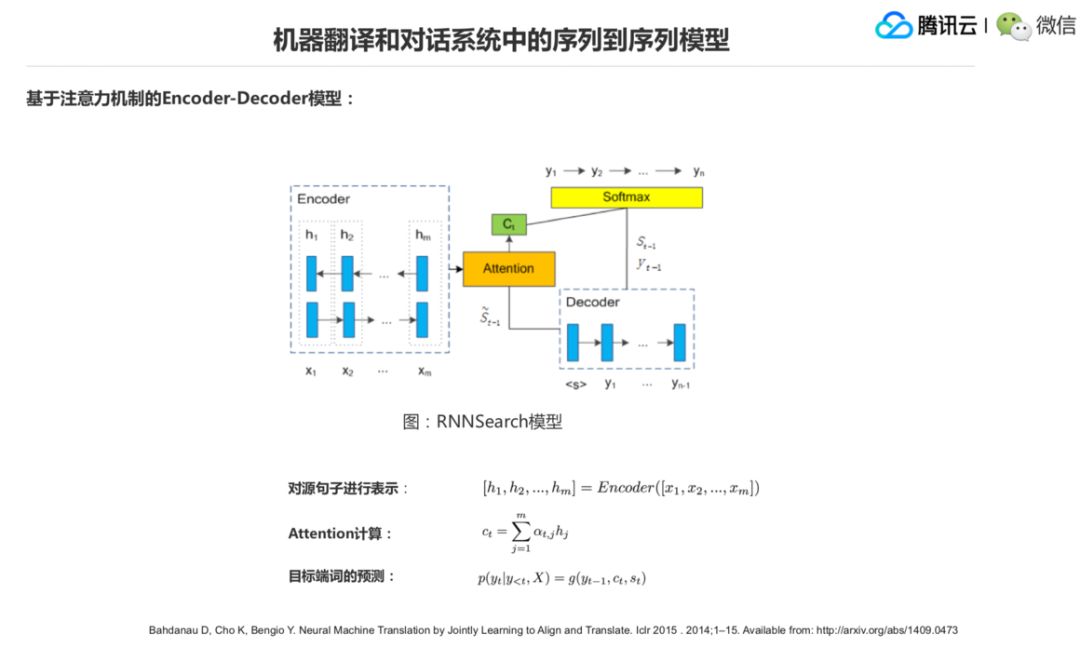
▌1.机器翻译和对话系统中的序列到序列模型
前面我们说到了对话机器人和机器翻译,这它两个问题其实差不多,一个就是对话机器人它是一个单语的聊天,你说中文它给你回复一个中文。机器翻译的过程其实是从一个语言到另外一个语言,它说“很高兴认识你”,翻译出来“Nice to meet you”,但两个问题实际上都是序列到序列的问题,也就是字和字。那么机器翻译模型和对话系统里面的闲聊,给你回复的这种,它可以用一个通用模型,就是前面说的 Encoder和Decoder 来解决。
数学形式的话就是这样,X 和 X1 到 Xm,Y 是 Y1 到 Yn,前面可以认为是 M 个词或者 M 个字,这边是 N 个词或者 N 个字,建模就两个序列之间的映射关系,就是第三个公式。只要把这个映射关系学到了,那么就知道给定了 X1 到 Xm 的时候,我怎么给出一个更好的 Y1 到 Yn,是一个更好的回复或者更好的翻译,这是一个序列到序列的问题模型。
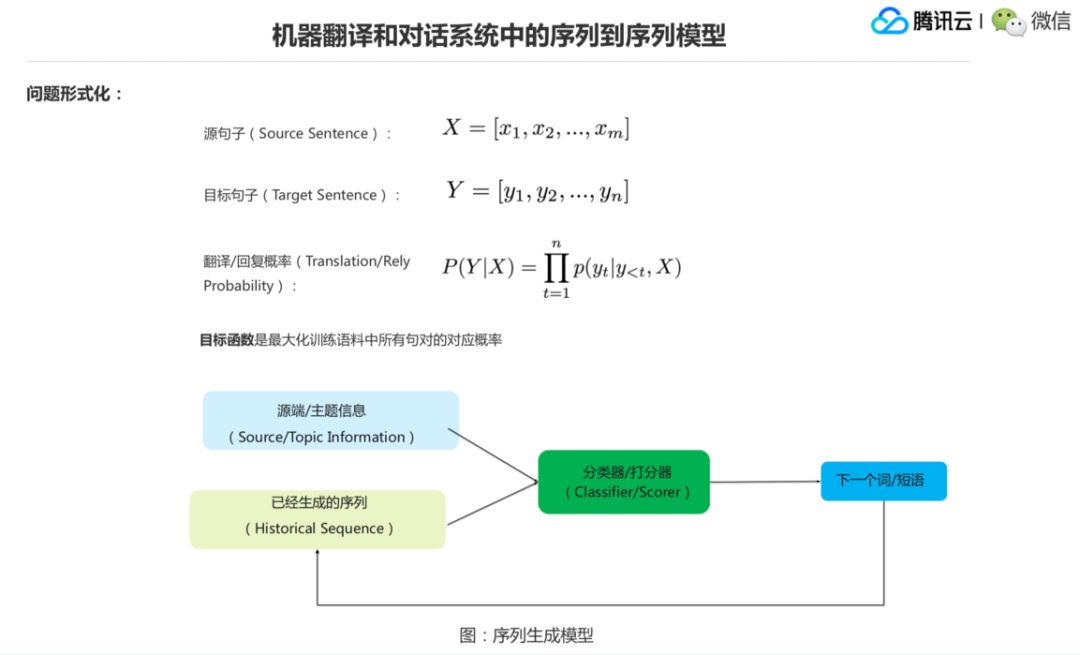
前面我们已经看过这个模型了,它怎么来生成这个 Y2?首先它要考虑源端的信息,比如 X1 到Xm,它是一个语义。再一个就是它还要考虑到已经生成了什么出来,因为它是逐个生成的,从 Y1 到 Yn,Yn 是逐个生成的。所以已经生成的序列加上源端的信息或者主题的信息,我们可以认为大 X 是一个源端信息或者主题信息,然后经过一个分类器来预测下一个词,下一个词预测出来又到这儿来了,加到已经生成的序列后面,这个序列变长了,然后再预测下一个词,直到预测出一个句子的终结符出来,这个序列的预测就算生成完成了,大概流程就是这样,抽象的数学表示就是上面三个公式。
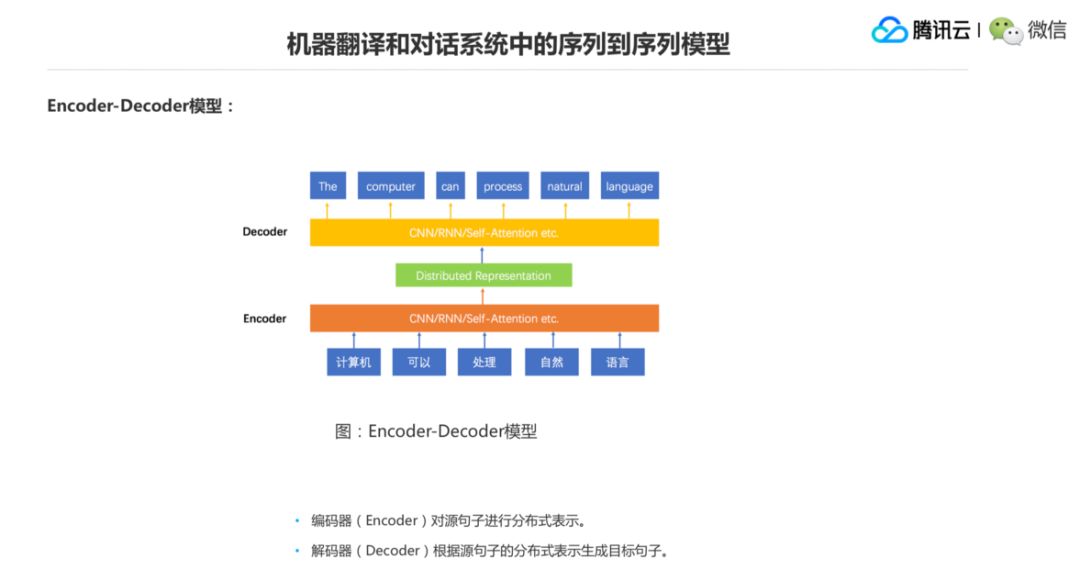
这个图是一个比较经典的 Encoder-Decoder 结构,左边是一个 Encoder,右边是一个 Decoder,中间是一个 Attention 注意力机制。当 Decoder 其中一个词的时候,比如说 Yt 这个词的时候,去源端寻找跟它相关语义的时候,用一个 Attention 的形式,它到底是 H1 扮演的权重大一些,还是 H2 扮演的权重大一些,还是 Hm 扮演的权重大一些,这是一个 Soft Attention 的过程。
这么讲其实有点泛,可以看公式,第三个公式,就是说我们来预测 Yt,Y 小于 t 了,就是说我们知道了前面已经生成的 t-1 个词,然后 x 是整个源端的信息,它需要参考一个 ct,ct 就是这个 Attention 完的一个结果。
然后就是前面刚生成完的一个 Decoder 顶层的一个状态,它在算源端的一个相关程度的时候,用的就是中间这一项公式。这个地方归比较绕,大家可以看一下公式。后面一个关于 Attention 机制的另外一个视角的看法,可能会更好理解一些。
还有一个是从检索的视角来看 Attention 机制,实际上就是一个 query 的过程,有一个 query key,然后来检索一个 Memory 的区域,实际上在上面的这个过程当中,拿前面这个 Decoder 的状态,它作为 query 的 key 去查 Encoder 的 Memory,这个 Memory 长度是 m,宽度是源端的表示维度,大概是查每一块对它的权重。我们做一个类比的话,知道计算机内存里面去保存,一般是有一个定位的过程,再一个就是保存的一个过程。
不同的是这个定位是 soft 的定位,假如你有 10 个格子去访问,不是说定位到第 3 个格子就读第 3 个格子的信息,而是说它要计算这 10 个格子里面的内容,构成最后那个内容的一个权重。比如给第一个格子分了 0.1,第二个格子分了 0.2,第三个格子分 了0.3,依此类推,那到最后整个表示的时候,就是每个格子内容乘上它的权重,然后加起来。这,可以认为是一个 qurery 的过程,检索一个 Memory 的过程,不再是计算机硬件里面这种硬性的 qurery,而是一个 soft 的 qurery。
这个 qurery 里主要是存在着两个 key 的运算,一个就是 qurery 可以和 Memory 里面 key 的一个运算来计算相关程度。相关程度计算完以后,通过 softmax 做概率的规划,然后把它转到概率空间上面,再根据这个概率对每一个值做权重的加和,得到最后的 result,大家可以看这一块的公式。relation 函数就是一个怎么来衡量两个东西关系的一个 relation 函数,一般可以用一个 BP 神经网络,就是一个前向网络来做。relation 函数有很多种选择方式,但它的目的就是算 relation。
广义的 Encoder-Decoder 框架现在用来做泛文本生成的一个问题,也就是说对话机器人、机器翻译或者写文章、写诗、写歌词这种都可以用 Encoder-Decoder 来做。
对它做一个大概总结的话,Encoder-Decoder 就可以把里面的构件随便地替换掉,比如 Encoder 用 RNN,Decoder 用 CNN ,所以我们前面提到一个神经网络里面构建的构件这些你完全可以在这个框架里任意去替换,把它当做模块化的东西来使用。

Attention 的计算过程是基于加法或者基于乘法的,全局的或者局部的,再一个就是它其实可以融入更多的特征进来。在这个框架里融入更多的模块。不变的是 Encoder 就是对文本做表示的,Decoder 就是用来做生成的。前面说了泛文本生成的任务都可以基于该框架来做,所以它是一个非常经典精简的框架。
▌2.机器翻译系统VS对话系统
现在来说机器翻译系统和对话系统之间的区别,前面说都可以用序列到序列的模型来进行建模,但是区别在哪?首先是机器翻译系统的训练语料是一个句对,一个是源语言,一个是目标语言,它们在语义上具有一个非常强的一致性关系,是一个非常标准的序列到序列的任务。再一个就是可以通过大量的平行语料来覆盖近乎全量的翻译现象。
对话系统其实场景非常复杂,那就是源端句子和目标端句子并不是语义上的一致性,不是表达语义,而只是一个相关性或者一个回复的关系,你说一句话,可能有上百种、上千种回复关系,所以你很难去拿语料去覆盖对话场景,并且语料变大的时候,可能会因为这个回复的多样性会导致知识冲突。再一个就是使用序列到序列的建模模型可以很方便地去搭建搭一个聊天机器人,就是你说一句话,它返回来给你一句话,看上去像在聊天,但是很难去搭一个实用的面向任务的对话系统,比如订定机票,更多的是说前面做意图分析,后面再去具体地执行。
对话前面也说了,机器翻译也需要知识库,但是对话这个系统更需要知识库,还有多媒体内容平台,比如你要看电影,它需要有一个电影库在后面支持,那就是对话系统和机器翻译系统区别非常大的一个地方。
▌3.小微对话系统
介绍一下我们微信研发的一套小微对话系统,目前是搭载到了很多硬件上。里面主要的 NLP 任务,内容大家看这个图,会有分词、词性标注、Parsing,还有意图识别、命名实体识别、槽位填充等 NLP 的任务都可以设计到这个系统里,也就是我们前面说的构建一个产品级的自然语言处理系统,一定会涉及到多个层面,多种技术的使用,才最后拼起来这么一个大的系统。
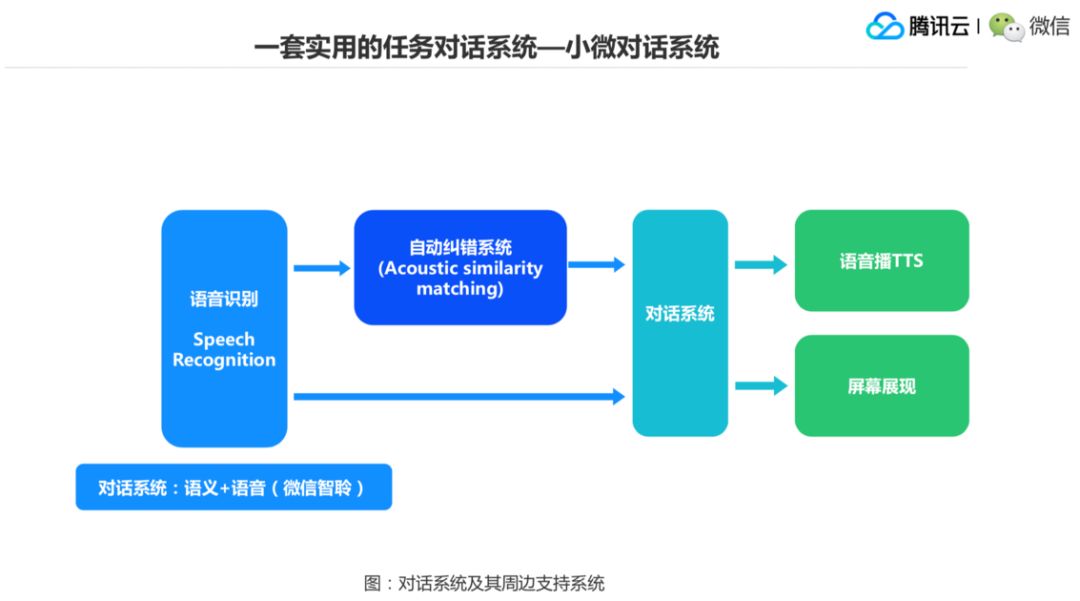
这个对话系统实际上在周边还需要很多支持的系统,现在就是语音交付,前面就是一个语音识别,语音识别可以纠错,然后放到这个对话系统里面,对话系统可以返回一个语音合成的结果或者说一个屏幕展示的结果。所谓语音合成的结果是这样,比如说你问对话系统明天的天气怎么样,那么它就直接给你一段语音就好了。,明天的气温是多少,日照强度是多少,这个就合成文本出来,然后文本再合成语音出来。
再一个就是屏幕展现,比如要看一个什么电影,语音合成肯定不满足你的需求了,那么就是到屏幕展现了,电影就被调出来,然后播放。微信里面语音识别这个系统叫“智聆”,然后给它做一个输入,交到小微里面去,小微做对话方面的计算,然后呈现用户结果。
一些标杆的案例,一个是客服,对话系统可以来做客服,你问它一个问题,然后它返回给你相应的答案。再一个就是闲聊对话机器人,贤二机器僧是一个公众号,你可以跟它去聊一些事情。还有就是车上的对话系统,比如让它去导航、播放音乐、新闻之类的。还有就是外交部的能够自动回复的助手。再一个就是现在大家能接触到的智能音箱或者智能机器人,基本上都要搭载这样一套对话系统。一个对话系统可以搭载到不同的硬件上去,构成不同的一些应用场景。
四、开发者的技能进阶建议
基础篇,其实还是要基于很大量的数学知识,比如说线性代数、矩阵运算这一块,整个神经网络所有的这个模型都是基于矩阵运算来做的,所以这一块要熟悉。然后再一个就是概率论,统计模型是以概率为基础的。还有就是高等数学,在神经网络或者深度学习技术里面用到的就是函数、导数、级数、公式推导这些,在数学模型统计方法里面,这些都是基础的基础,非重要。
第二个建议是熟练使用一种深度学习的平台,现在 python 基本上成了人工智能的一种流程型的语言,大家可以去熟练地掌握,还有然后其他的深度学习平台,像 TensorFlow 这种,能够让你非常方便地来搭建神经网络模型,不用再去关注非常底层的一些运算。
推荐一些公开课,像 Chris Manning,自然语言处理或者 Standford 里面的 Deep Learning 课程,还有 Coursera 里面的一些自然语言处理课程,大家都可以看一下。下面这个博客,有一些非常好的资源,大家可以去听别人讲一些东西,然后接触基础资料,怎么去入门。
进阶篇,进阶篇去研读一下现在优秀的一些深度学习的活动,像 Word2Vec 这种大家用得都非常多的。再复杂一点的,像 GNMT,就是谷歌开源出来的一套神经网络的代码。然后 Tensor2Tensor,大家在看的时候,一方面可以去学习模型,另一方面可以学习深度学习平台的使用方法。也就是你读别人的代码,可以学到很多东西。再一个就是培养问题建模的能力,就是说你要对问题和模型比较熟悉,给你一个问题你大概能判断出它大概用哪个模型去解决会好一点。再一个模型实现,就是你能把它实现出来,然后跑出实验结果出来,就要性能分析、调优,然后加一些训练方法进去,能够很好地实现任务。
创新篇,这是更高阶段的一个目标。要去研究最新的方法,要读论文,然后对这个领域的研究现状和方法都有一个比较清晰的认识,然后看透问题的本质大概是怎样的,然后尝试提出自己的观点和创新性的解决方法,然后能拿合理的实验方法去验证。
五、答听众问
Q:中文分词和深度学习的算法相比差距有多少?还需要学习传统算法吗?
A:我读博前两年做了分词相关的研究,用深度学习方法做过,也用统计的方法做过。那实际上在一个标准的语料上,就是有一个标准的任务,比如在 3 万个句子上做训练,然后在几百个句子上做分词的话,神经网络的方法在表现上面并不具备比传统方法特别好的一个表现,但在标准的任务上,神经网络方法一个好处就是它不需要设计特征模板。
Q:序列化标注模型有什么成熟的模型?
A:其实有很多很成熟的模型和工具,问题模型就是序列标注问题,模型有 CRFCIF 或者 MEMM1Mn等,就是最大熵之类的,这些都有一些开源的开放包,你就直接拿着它然后搞一下特征,输进去,就可以训练了,都是非常成熟的,神经网络也可以做序列标注任务。
Q:有监督和无监督方法哪个更有优势或者两者区别,可以具体说个例子吗?
A:有监督方法和无监督方法的应用场景不一样。目前自然语言处理任务在产品当中应用的难点,一个就是有限的标注数据,要完成很多任务,你先是要去标注数据,需要的人力成本比较高,然后人与人之间的标注数据也会存在一些不一致性,并且你针对某一个具体任务标注的数据它很难迁移到其他任务上去使用,所以这个有监督的方法还是比较局限,然后成本比较高。无监督方法就想解决这个问题,就是怎么把这个成本降下来,但问题是无监督的方法现在的效果不太好,因为无监督它确实知识很少,离应用也会更差一些,但是无监督是一个非常值得研究的问题,如果真的哪天这个问题能够很好地解决,不再需要标数据的方式,那么无监督方法就可以通用了。
-
深度学习
+关注
关注
73文章
5500浏览量
121118 -
自然语言
+关注
关注
1文章
288浏览量
13347 -
nlp
+关注
关注
1文章
488浏览量
22033
原文标题:微信高级研究员解析深度学习在NLP中的发展和应用 | 公开课笔记
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度学习在汽车中的应用
专栏 | 深度学习在NLP中的运用?从分词、词性到机器翻译、对话系统
对2017年NLP领域中深度学习技术应用的总结
回顾2018年深度学习NLP十大创新思路

一文读懂何为深度学习1
一文读懂何为深度学习2
一文读懂何为深度学习3

GPU在深度学习中的应用与优势






 工商网监
工商网监
评论