 DeepMind给AI测IQ,结果出人意料!
DeepMind给AI测IQ,结果出人意料!
活在一个AI“泛滥”的时代,我们几乎每天都能看到 AI 研究上的最新进展。昨天,AI 打 DoTA 战胜人类了;今天,AI 能自己找路了;明天,AI 能假冒人类打电话了。在担心 AI 会灭掉人类的人们眼中,AI 正像一只怪物一样野蛮生长,像一只侵略军一样从远方大跨步逼近。
然而实际上,你所看到的这些进展,只是不同的 AI 在特定方向的进步。虽然当前基于深度学习的 AI 热潮已经有五六年了,还是没有一个独立的 AI,像一个独立的人一样,能够优秀地执行多种任务。
人们在形容 AI 时,通常会用这样一种说法:这个 AI 的智商,跟三岁小孩差不多。 智商 (Intelligence quotient) 简称 IQ,是评价人类智商一个普遍接受的标准 。你有智商,我也有智商,就连三岁小孩也有智商。接下来问题来了:既然说 AI 跟三岁小孩差不多,那么它的智商到底有多少呢
得给 AI 测测智商了。
DeepMind要给AI测IQ
自 AlphaGo 横空出世以来,AI 在解决一些复杂的、策略性的问题上,能力已经得到了证明。但如果想要更像“人”,AI 必须也拥有像人类一样的抽象理解能力。
现在的 AI 计算能力不用说了,推理能力也很强,所以只剩抽象理解能力了。Google 旗下的 AI 科研机构 DeepMind 认为,“基于神经网络的机器学习模型取得了惊人的成绩,但想要衡量其推理抽象概念的能力,却非常困难。”
为了搞清楚现在的 AI 在抽象理解能力上究竟实力如何,DeepMind 还真给 AI 设计了一套测试题:
这套测试题,借鉴了人类的 IQ 测试里著名的瑞文推理测验:给定一组图片,找到符合其“演进”规律的图片。
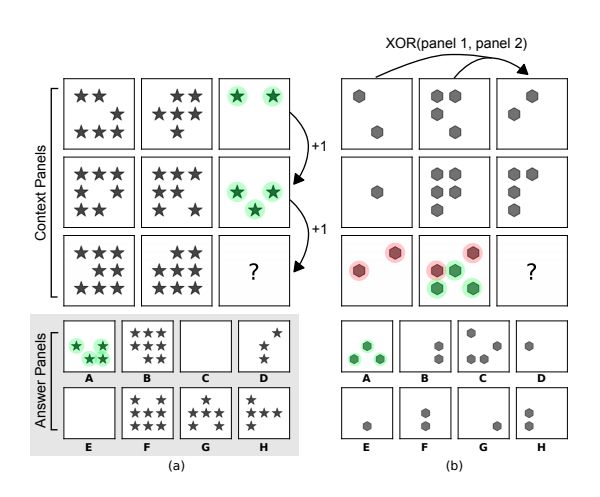
(图片来源:DeepMind 论文)
在这种测试中,题目里并不会告诉你要找到符合什么标准的图形,而是需要我们根据日常生活中学习或掌握到的一些基本原则,来理解和分析测试中出现的简单图案。
要找到正确的答案,往往要借鉴我们从生活中明白的“演进”规律。比如小树苗长成大树,比如从 0 到1、2、3、4、5 的加法,再比如加减乘除。以上这些,就是我们生活中所提炼出的抽象的“演进”(progression)的意义,就是人类的抽象理解能力。
“但是,我们现在还没有找到办法,能让 AI 也可以从 ‘日常经验’中学到类似的能力。” DeepMind 在论文中说。
“不过,我们依然可以很好地利用人类的这种视觉抽象逻辑测试,来设计一个实验。在这个测试中,我们并不是像人类测试那样,考察从日常生活到视觉推理问题的知识转移。而是研究AI在将知识从一组受控的视觉推理问题,转移到另一组问题的能力。”
简单翻译一下这段话就是:DeepMind 先给 AI 喂一组由三角形构成的图像的视觉推理题库,等训练的差不多了,再出一组由方块构成的视觉推理题,让 AI 去回答,看它是能随机应变举一反三,还是学会了三角,换成方块就不灵了。
机器人仍需努力
对于担心 AI 取代人类的朋友来说,DeepMind 的一部分实验结果确实是个好消息:一些最棒的 AI 模型,在这个IQ测试中的表现得并不咋样。
正如预期的那样,当训练集和测试集所采用的抽象元素相同时,多个 AI 模型都表现出超过75%的准确率。
然而,当测试集和训练集出现变化,甚至有时候只是把黑点换成较暗的浅色圆点,AI 的表现就会像无头苍蝇一样,失去了准星。
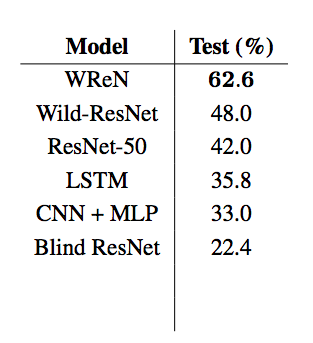
(一些知名AI模型的表现 图片来源:DeepMind 论文)
上面这些都是深度神经网络领域的当红炸子鸡,测起智商来却没那么灵光了。
ResNet (Deep Residual Network),即深度残差网络在其中一组测试中仅仅得到22.4%的低分。 要知道,它的提出曾被形容为CNN(卷积神经网络)的一个里程碑式事件,它在网络深度上比其他模型提升了n个量级,更重要的是它的残差学习方式,改良了模型的架构,因此一出现就秒杀众前辈。
测试中表现最好的 WReN 模型,则是 DeepMind 在关系网络 (Relation Networks) 模型基础上改良的版本。它增加了对不同图像组合之间关系的分析,并可以对这类 IQ 测试的各种可能性结果进行评估。
不过,DeepMind 针对这个测试的逻辑,对一些模型进行改良,改良后的模型表现出明显的提升。
比如,在一些模型中,DeepMind 加入了元标记(meta-targets) 的辅助训练方法,让模型对数据集背后体现出的形状、属性(形状的数量、大小、颜色深浅等)以及关系(同时出现、递减、递增等等)进行预测,当这部分预测准确时,最终回答的准确率就明显出现提升,预测错误时,回答准确率明显下降。一些极端情况下,模型回答的准确率更是从预测错误时的32%提升至了87%。
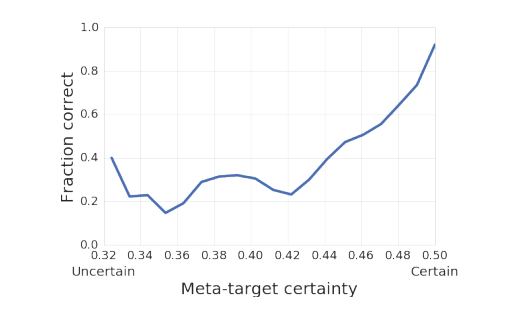
(元标记预测准确度与最终答案准确率的关系图)
DeepMind 表示,他们设计的这个实验,最终目的并不是为了让 AI 能够通过这种 IQ 测试。他们关注的是 AI 泛化能力的问题。
泛化是指模型很好地拟合以前未见过的新数据的能力,这是机器学习界的术语,你也可以粗暴的理解成一个 AI 模型能否在各类场景中“通吃”。AI 的泛化能力越强,离啥都能干的所谓“通用人工智能”就越近。
DeepMind 在博客最后这样说道:
研究表明,寻找关于泛化问题的普遍结论可能没有任何意义。我们测试的神经网络在某些泛化方案中表现优秀,但是其他方案下却很糟糕。
诸如所使用模型的架构、模型是否被训练从而能解释答案背后的逻辑等一系列因素,都会对泛化效果带来影响。而在大多数情况下,当需要处理过往经验从未涉及的、或完全陌生的情景时,这些 AI 的表现很糟糕。
至少现在看来,AI 还有很长的路要走啊。
-
AI
+关注
关注
87文章
30758浏览量
268902 -
DeepMind
+关注
关注
0文章
130浏览量
10850
原文标题:DeepMind给最厉害的AI测了IQ,结果让人轻松了不少!
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
特斯拉“出人意料”三季度报!马斯克:明年推平价车型,预期销售增三成
OpenAI推迟GPT-5发布,专注草莓计划GPT-o1及AI代理愿景
投影双雄极米与当贝意外携手,共谋行业新篇章

谷歌Vertex AI助力企业生成式AI应用
基本电子元件的内在之美
谷歌DeepMind推出新一代药物研发AI模型AlphaFold 3
希捷科技业绩出人意料,四财季利润可能超华尔街预期
开发者手机 AI - 目标识别 demo
微软发布AI生成解决方案,预防失控风险
谷歌DeepMind推出SIMI通用AI智能体
谷歌DeepMind推新AI模型Genie,能生成2D游戏平台
谷歌DeepMind资深AI研究员创办AI Agent创企
谷歌DeepMind科学家欲建AI初创公司
再登Nature!DeepMind大模型突破60年数学难题,解法超出人类已有认知






 工商网监
工商网监
评论