 为什么说AI芯片是FPGA的附庸?
为什么说AI芯片是FPGA的附庸?
央行放水之后,催生出了一大批手握重金的投资机构,而国内优秀的投资标的,特别是高科技领域的标的极为稀缺,AI芯片获得投资易如反掌,一时间冒出来几百家AI芯片公司,也给投机分子可乘之机。
作为国内最优秀的AI芯片公司,深鉴科技被以3亿美元的价格卖给FPGA巨头赛灵思。过去两年,深鉴科技是国内AI芯片领域冉冉升起的一颗明星。这家2016年3月成立的初创公司目前已完成三轮融资,投资方包括金沙江创投、蚂蚁金服、三星风投、赛灵思、联发科等知名机构和公司。据媒体报道,其估值远超过10亿美金。如今以3亿美元卖出,并且据称核心团队要锁定4年内不得离开赛灵思。难道深鉴科技被贱卖?当然没有!这是因为中国真正优秀的企业太少,而追逐的资本太多,优秀企业的估值已经到了完全没有理性的地步。如果这些企业在美国,估值会萎缩数倍以上。
人工智能算法不大可能用ASIC,因为ASIC的开发周期太长,最少也需要3年才能量产,而人工智能算法迭代速度很快,几乎是每半年就迭代一次,所谓人工智能ASIC,没出厂就已经过时。另一个原因是人工智能芯片需要7纳米工艺。
7纳米时代,不是90纳米时代,除非你像谷歌的TPU那样自产自销,否则,铁定长期亏损。根据Gartner推算,10纳米芯片的总设计成本约为1.2亿美元,7纳米芯片则为2.71亿美元,较10纳米高出两倍之多!为什么人工智能芯片一定要用7纳米?
所谓制程纳米,是CMOS FET晶体管闸极的宽度,也就是闸长。闸长可以分为光刻闸长和实际闸长,光刻闸长则是由光刻技术所决定的。由于在光刻中光存在衍射现象以及芯片制造中还要经历离子注入、蚀刻、等离子冲洗、热处理等步骤,因此会导致光刻闸长和实际闸长不一致的情况。另外,同样的制程技术下,实际闸长也会不一样,比如虽然三星也推出了 14nm 制程芯片,但其芯片的实际闸长和 Intel 的 14nm 制程芯片的实际闸长依然有一定差距。
闸长越短,有两大好处,一是可以提高晶体管密度,在同样大小的硅晶圆制造更多的晶体管,需要的运算资源越强,对应的晶体管数量就越多。英伟达的Xavier Tegra处理器号称是“全球第一个AI汽车超级芯片”,将采用台积电16nm FinFET+工艺制造,集成多达70亿个晶体管,性能方面,Xavier预计可以达到30 DL TOPS,比现在的Drive PX 2平台提高50%,同时功耗只有30W。拥有多达八个NVIDIA自主设计的ARMv8-A 64位CPU核心,GPU则会基于下一代“Volta”(伏特)架构,最多512个流处理器,还有基于硬件的视频流编码解码器,最高支持7680×4320 8K分辨率,以及各种IO输入输出能力。
英伟达还有一片GTX 1080 TI,同样采用台积电16nm FinFET+工艺制造,集成多达120亿个晶体管,硅片面积是471平方毫米。英特尔至强E5 2600 V4,引入了14nm工艺,456平方毫米的核心面积里集成了72亿个晶体管,相比之下上代22nm Haswell-EP Xeon E5-2600 v3只有56.9亿个晶体管,而核心面积达662平方毫米。英伟达专为深度学习订做的芯片Tesla P100,则在600平方毫米内集成了150个晶体管,仍然是台积电的16nm FinFET+工艺制造,单精度浮点运算能力达9.3TFLOPS。高通的骁龙835则是集成了30亿个晶体管。
另一个好处是降低功耗。
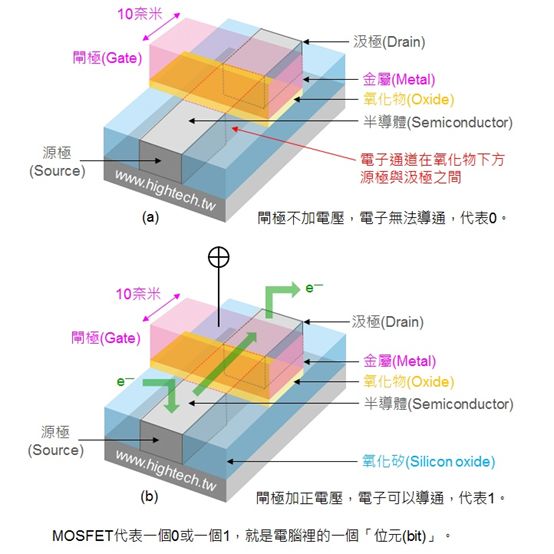
电流从 Source(源极)流入 Drain(漏级),Gate(闸极)相当于闸门,主要负责控制两端源极和漏级的通断。电流会损耗,而栅极的宽度则决定了电流通过时的损耗,表现出来就是手机常见的发热和功耗,宽度越窄,功耗越低。
业内公认,10纳米不是关键,关键是7纳米,10纳米只是低功耗过渡工艺,性能上与14纳米相差无几,意义不大,7纳米才是关键之战。
ASIC性能与功耗比最好,但开发周期长,开发成本最高,灵活性最差,如果出货量低的话(如果采用7纳米工艺,最低也要每年1亿的出货量,才能将芯片单价降低到100美元以下),要么单价高到几千美元,要么厂家毛利率就是负的。最终结果都一样,长期亏损。
无人车领域将是ASIC的噩梦,汽车领域对价格非常敏感,有些汽车厂家为了省成本,几元钱的摇窗电机都要节约。能用商规元件就不用工规,成本也就差几元。再有就是汽车出货量低,全球汽车市场每年不过1亿辆,远不能和手机与笔记本电脑比。高端车出货量更低,每年大约1000万辆,无人车比高端车还要低。即便你市场占有率再高,出货量也是很低。再有就是生命周期在缩短,以前一个车型可以有7-8年生命周期,现在竞争激烈,尤其中国市场,三四年不大改款的车就无人问津。虽然相对手机市场生命周期还算长,但趋势已经很明显,一款车型的生命周期正在迅速缩短。
台积电会把你的订单放到最后一个
芯片代工领域,台积电拿下所有的7纳米订单,包括独家供应苹果的A12,这也是台积电首次超越英特尔成为半导体制造工艺最先进的厂家,像人工智能这种强调运算能力的数字类逻辑芯片,先进工艺是必须采用的。所以说台积电也拿下了所有人工智能芯片订单, 三星毫无能力抢单。
韩国媒体报导三星的7奈米拿下高通骁龙855手机芯片订单,消息应为误传。高通还是会把90%订单交给台积电,只把10%产品转向三星,实际是为了降低供应链风险采取的策略。台积电自然会优先照顾苹果、高通、AMD、英伟达、华为、联发科这些出货量上亿的大客户,把小客户订单排在最后,这对Mobileye来说也非常不利。
对于台积电来说,与一个大客户合作需要的精力和一个小客户合作所需要的精力是一致的,台积电自然要优先照顾大客户。三星一直是低价抢单,但目前来看,客户完全不认同,比如华为,原本外界预估,因为台积电代工费用较高,因此麒麟 710 处理器选择三星的 10 奈米 LPP 制程来生产制造。但是,如今根据华为官方公布的结果,麒麟 710 处理器仍旧由台积电的 12 奈米制程来进行代工生产,而非原先传出的三星 10 奈米制程。显示之前一直传三星以较低价格抢单的情况,并没有发生任何功效。最新的 EUV 曝光机一台价格超过 1 亿欧元,是 DUV 曝光机价格的 2 倍多,且使用 EUV 曝光机批量生产时会消耗 150万瓦电力,远超过现有的 DUV 曝光机。最重要是EUV技术不够成熟,且成本略高,而三星欲速则不达,为了超越台积电,导入EUV技术,台积电仍然是DUV技术。当然,等EUV成熟,台积电也会用。
为何台积电总能在先进制程上屡战屡胜呢?首先也是最重要的一点,台积电从来不会试图跳跃式发展,一步一步来,慢不代表错,快不代表对。其次不像其他竞争者,与台积电无利益冲突的客户群(苹果、赛灵思、英伟达、博通/华高、瑞萨、谷歌、海思、联发科、AMD等)数量庞大,不断地追求先进制程,投入研发,改善设计规则,与台积电共同改善制程良率、降低成本,来加快量产速度。也就是说,台积电不是一个人在战斗,台积电背后有着全球所有最顶尖的IC设计公司在支持。而且台积电有超过50%产能,已完全折旧、做成熟制程;而且五年折旧的新机器设备,约可使用十五年以上,这样可提供足够的现金流,来大量投资初期获利较差的最先进制程。
而三星和英特尔因不具足够晶圆客户,三星和英特尔尽量将旧制程转换成新制程(机器设备多使用三至五年),并利用主流产品(三星的内存,英特尔的中央处理器)现金流,来补助晶圆代工的投资;因此三星会出现亏损,英特尔的营业利润率和净利率会远远落后台积电。台积电则使用其优异的布线,来微缩芯片尺寸和加快速度,而不是一味追求最小硅间闸和金属间闸(metal pitch or interconnects),进行可能威胁顺利量产的微缩。
英特尔也深知晶圆代工这个领域与台积电竞争无异于自杀,与台积电合作是双赢之路。因此英特尔的FPGA大部分仍然由台积电代工。
FPGA已经不是FPGA,更接近于ASIC
不是短期盈利无望,而是长期盈利无望,卖身给FPGA厂家肯定是最明智的选择。在大部分人眼里,FPGA缺乏技术含量,纯粹靠专利建立起护城河,FPGA只是个躯壳,算法才是灵魂。是深鉴让FPGA获得灵魂。果真如此的话,那估值就不是3亿美元。实际上声称有能力做机器学习算法的公司据说超过3000家,而大规模生产FPGA的独立厂家全球仅Xilinx一家。
算法应该说像人的视觉系统,FPGA则是人的大脑和躯壳。现在的FPGA早已不是当年的简单地把寄存器和LUT整合在一起的白纸了,而是越来越像ASIC,或者说SoC。现在的FPGA都包含了复杂的接口资源,收发器资源,存储器资源,有些则直接加入了多个ARM内核。单纯的FPGA几乎不存在了。
以深度学习、高性能运算、图形科学领域最常见的Kintex FPGA来看,国内百度、腾讯、阿里都采用了KU115做计算加速。这款FPGA集成了大量资源,包括各种片上存储器,Xilinx的FPGA中主要有分布式RAM 和 Block RAM 两种存储器。用分布式RAM 时其实要用到其所在的SliceM,所以要占用其中的逻辑资源;而Block RAM 是单纯的存储资源,但是要一块一块的用,不像分布式RAM 想要多少bit都可以。顶级的Virtex系列FPGA更继承了高达8GB的HBM高宽带内存。时钟方面,有MMCM/PLL。
MMCM(mixed-mode clock manager):混合模式时钟管理器,用于在与给定输入时钟有设定的相位和频率关系的情况下,生成不同的时钟信号。PLL(phase-locked loop):锁相环,主要用于频率综合,使用一个PLL可以从一个输入时钟信号生成多个时钟信号。这些主要用在收发器领域。
KU115里还包含5520个DSP,能够大幅度提高图像和视频类任务的处理速度,这是类似GPU的并行运算架构,可以说这片FPGA还包含一个小GPU。这个DSP可以对应乘法累加器、乘加器或单步/n步计数器。级联多个DSP48E逻辑片可执行复杂的功能。例如,不使用额外的FPGA架构资源的情况下实现复杂乘法器或n阶FIR滤波器。对某些如FFT运算,速度大大提升。Virtex系列顶配有12288个DSP,性能达21897GMAC/s。

Xilinx的Soc+FPGA系列产品则完全可以叫SoC了,其不仅包含多个ARM CPU内核,还有针对安全领域的R5内核,还有Mali 400这样的GPU,最夸张的是RFSoC把射频的ADC/DAC也集成了,还有SD-FEC。
目前集成电路设计基本上都是用IP核搭积木的形式。IP核分为行为(Behavior)、结构(Structure)和物理(Physical)三级不同程度的设计,对应描述功能行为的不同分为三类,即软核(Soft IP Core)、完成结构描述的固核(Firm IP Core)和基于物理描述并经过工艺验证的硬核(Hard IP Core)。软核就是我们熟悉的RTL代码;固核就是指网表;而硬核就是指指经过验证的设计版图。ARM还是以软核为主的。
IP软核(Soft IP Core):通常是用硬件描述语言(hardware Description Language,HDL)文本形式提交给用户,它经过RTL级设计优化和功能验证,但其中不含有任何具体的物理信息。据此,用户可以综合出正确的门电路级设计网表,并可以进行后续的结构设计,具有很大的灵活性,借助于EDA综合工具可以很容易地与其他外部逻辑电路合成一体,根据各种不同半导体工艺,设计成具有不同性能的器件。其主要缺点是缺乏对时序、面积和功耗的预见性。而且IP软核以源代码的形式提供的,IP知识产权不易保护。
IP硬核(Hard IP Core)是基于半导体工艺的物理设计,已有固定的拓扑布局和具体工艺,并已经过工艺验证,具有可保证的性能。其提供给用户的形式是电路物理结构掩模版图和全套工艺文件。由于无需提供寄存器转移级(Register transfer level,RTL)文件,因而更易于实现IP保护。其缺点是灵活性和可移植性差。
IP固核(Firm IP Core)的设计程度则是介于软核和硬核之间,除了完成软核所的设计外,还完成了门级电路综合和时序仿真等设计环节。一般以门级电路网表的形式提供给用户。
深鉴只是做了最上层的基于PC的应用算法,要想让算法在嵌入式系统中流畅运行,还需要大量的工作,而这正是Xilinx做的。这就好像图像识别算法,基于PC的几百家都不止,但要一直到车内的ARM系统上,表现会大大折扣,完全不具备实时性,也就无法应用。
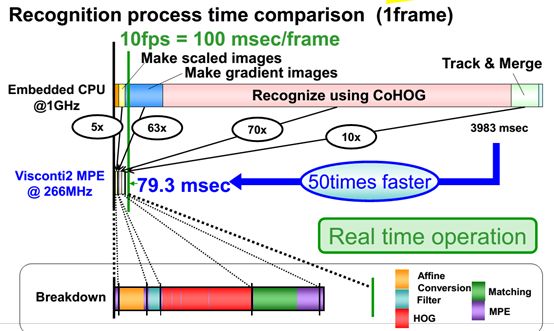
上图是一个典型的行人识别算法HOG+SVM所需要时间的对比,硬核只需要79.3毫秒,软核需要3983毫秒,所以纯软核的设计要么用极简单的算法,要么用英伟达贵到飞起的芯片,即便如此,也不能和硬核比。所以单纯的算法公司,特别是复杂视觉处理算法公司如果不能将算法用芯片来承载,那就不可能成功。当然,融资还是能成功的,毕竟还有很多投资者不是真正懂技术。
-
FPGA
+关注
关注
1629文章
21748浏览量
603809 -
人工智能
+关注
关注
1791文章
47349浏览量
238732
原文标题:AI芯片可能只是FPGA的附庸
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI芯片可能只是FPGA的附庸
手把手教你设计人工智能芯片及系统--(全阶设计教程+AI芯片FPGA实现+开发板)
29页PPT,详细介绍Ouroboros的语音AI芯片
【免费直播】让AI芯片拥有最强大脑—AI芯片的操作系统设计介绍.
AI芯片格局最全分析 精选资料分享
ai加速芯片
今日说“法”:FPGA芯片如何选型?
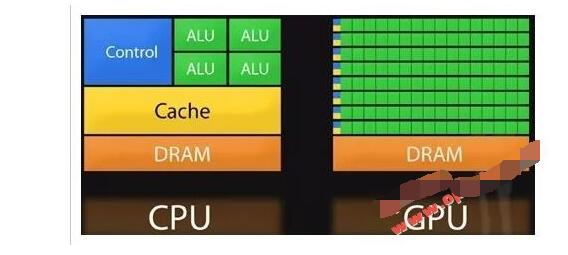
浅析GPU、FPGA、ASIC三种主流AI芯片的区别
用FPGA迎接AI时代而不是专用芯片
FPGA能满足边缘AI计算吗?
FPGA、ASIC等AI芯片特性及对比





 工商网监
工商网监
评论