 介绍pandas的两种数据结构
介绍pandas的两种数据结构
对于Python而言,坊间早有这种说法:在有了 pandas之后,Python才算有了数据分析的能力。在此之前,要想用Python来做数据分析,可能就没那么友好了,可见pandas在学习数据分析时候的重要程度。对于 pandas来说,很多功能的实现也是要基于科学计算库 numpy的,所以 numpy+ pandas的组合在Python数据分析中就显得尤为关键。
从本篇开始,小编就给大家详细讲解 pandas的基本用法和应用案例,熟悉R的朋友们也可以将其与R的数据分析功能进行对比,定能有所收获。本篇先对 pandas的数据结构进行介绍,跟R大不相同的是,Python并没有太多不同的数据结构和对象, pandas中主要包括 Series和 DataFrame两种数据结构。
Series
Series有点类似于 numpy中的一维数组对象,一般由一组数据和数据相关的标签或者索引构成,由一组数构成最简单的 Series如下:
from numpy import *
from pandas import *
创建 Series:
obj = Series([-1,3,-4,6])
print(obj)
0 -1
1 3
2 -4
3 6
dtype: int64
可以看到的是,由一组数创建的 Series对象索引在左边,值在右边。我们也可以通过索引和值标签分别访问相应的对象:
#Series对象值
obj.values
array([-1, 3, -4, 6], dtype=int64)
#Series对象索引
obj.index
RangeIndex(start=0, stop=4, step=1)
当然,我们可以在创建Series对象的时候就对索引进行标记或者命名:
#对Series索引进行命名或者标记
obj2 = Series([-1,3,-4,6],index = ['a','b','c','d'])
print(obj2)
a -1
b 3
c -4
d 6
dtype: int64
#查看索引
obj2.index
Index(['a', 'b', 'c', 'd'], dtype='object')
根据 Series索引访问对象值:
obj2['a']
-1
obj2[['a','b','c']]
a -1
b 3
c -4
dtype: int64
也可以对Series对象进行数组运算:
obj2[obj2 > 0]
b 3
d 6
dtype: int64
obj2*2
a -2
b 6
c -8
d 12
dtype: int64
np.exp(obj2)
a 0.367879
b 20.085537
c 0.018316
d 403.428793
dtype: float64
除了直接以数组形式创建 Series对象之外,通过字典来生成 Series也是较为普遍的做法:
nba = {'Kobe Bryant':30.3,'Allen Iverson':29.4,'Tracy McGrady':30.1,'Vince Carter':25.6}
obj3 = Series(nba)
print(obj3)
AllenIverson 29.4
KobeBryant 30.3
TracyMcGrady 30.1
VinceCarter 25.6
dtype: float64
创建完之后可以对 Series对象和索引进行命名:
obj3.name = 'nbastats'
obj3.index.name = 'player'
print(obj3)
player
AllenIverson 29.4
KobeBryant 30.3
TracyMcGrady 30.1
VinceCarter 25.6
Name: nbastats, dtype: float64
另外, Series索引可以随时进行更改:
obj3.index = ['A.Iverson','K.Bryant','T.McGrady','V.Carter']
print(obj3)
A.Iverson 29.4
K.Bryant 30.3
T.McGrady 30.1
V.Carter 25.6
Name: nbastats, dtype: float64
除了上述创建 Series对象的方法以外,从 DataFrame中单独拿出一行也可以用来创建 Series。关于 Series数据结构的基本内容就介绍到这里,下面看 DataFrame。
DataFrame
说到 DataFrame,可能大家更熟悉的是R语言中的 data.frame,Python中的 DataFrame跟它也较为类似。在Python中, DataFrame是一个表格型的数据结构,它含有一组有序的列,每列的数据类型可以不一样,与R中的数据框相比,Python中的 DataFrame行列操作较为平衡。 构建DataFrame方法很多,最常用的是直接传入一个由等长列表或NumPy数组组成的字典:
data = {'city':['LAL','HOU','PHI','TOR'],
'year':[1996,1997,1996,1997],
'score':[30.3,30.1,29.4,25.6]}
frame = DataFrame(data)
frame
city score year
0 LAL 30.3 1996
1 HOU 30.1 1997
2 PHI 29.4 1996
3 TOR 25.6 1997
可以看到,字典在转化为数据框的过程中,键是作为列名而存在的。
#按指定列进行排列
DataFrame(data,columns=['year','city','score'])
year city score
0 1996 LAL 30.3
1 1997 HOU 30.1
2 1996 PHI 29.4
3 1997 TOR 25.6
根据字典传入时,若是指定列找不到数据则会自动填补为缺失:
#若传入的列找不到数据则会产生NA
frame2 = DataFrame(data,columns=['year','city','score','assist'],
index=[1,2,3,4])
print(frame2)
year city score assist
11996 LAL 30.3 NaN
21997 HOU 30.1 NaN
31996 PHI 29.4 NaN
41997 TOR 25.6 NaN
如前述,我们可以通过 data.frame来获取一个 Series对象:
frame2['city']
1 LAL
2 HOU
3 PHI
4 TOR
Name: city, dtype: object
frame2.score
1 30.3
2 30.1
3 29.4
4 25.6
Name: score, dtype: float64
也可以通过 loc方法访问 DataFrame的行:
frame2.loc[3]
year 1996
city PHI
score 29.4
assist NaN
Name: 3, dtype: object
对缺失的变量进行重新赋值:
frame2['assist']=5.6
print(frame2)
year city score assist
11996 LAL 30.3 5.6
21997 HOU 30.1 5.6
31996 PHI 29.4 5.6
41997 TOR 25.6 5.6
按索引传入时,没有被指定的记录产生缺失:
val = Series([4.5,3.9],index=[1,4])
frame2['assist']=val
print(frame2)
year city score assist
11996 LAL 30.3 4.5
21997 HOU 30.1 NaN
31996 PHI 29.4 NaN
41997 TOR 25.6 3.9
对于嵌套字典转化为 DataFrame,一般外层字典的键作为列,内层字典的键作为行索引:
nba = {'kobe':{2005:35.6,2006:32.1},'McGrady':{2005:26.7,2006:24.3}}
frame3 = DataFrame(nba)
print(frame3)
McGrady kobe
2005 26.735.6
2006 24.332.1
关于pandas的两种基本数据结构Series和DataFrame,小编就暂且介绍到这里了,关于如何在实际的数据分析过程熟练使用这两种数据结构的基本操作,小编在后续的推文中会进一步的讲解。
-
数据分析
+关注
关注
2文章
1421浏览量
33994 -
python
+关注
关注
55文章
4777浏览量
84396
原文标题:利用pandas进行数据分析(一):Series和DataFrame数据结构
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Python的列表和元组两种数据结构区别差异分析
盘点几种常见的数据结构

数据结构是什么_数据结构有什么用
java中几种常用数据结构
为什么要学习数据结构?数据结构的应用详细资料概述免费下载
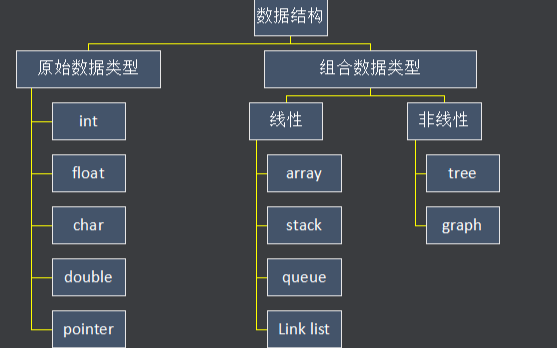
什么是数据结构?为什么要学习数据结构?数据结构的应用实例分析
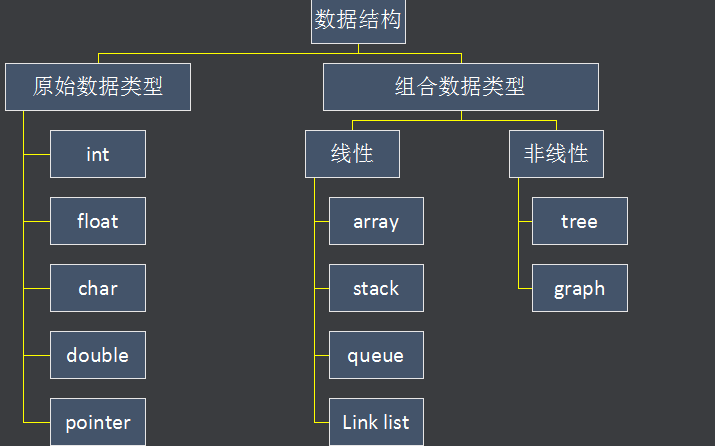
数据结构解决滑动窗口问题
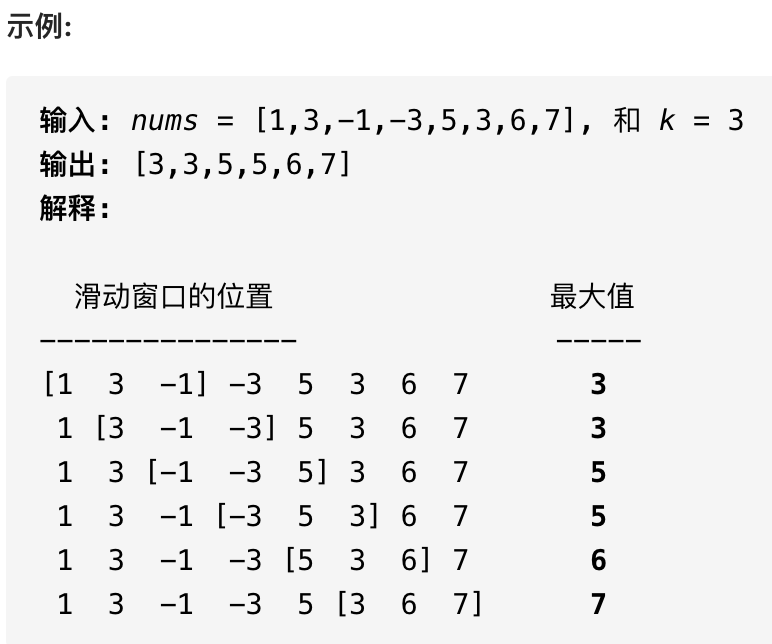
Linux内核中使用的数据结构





 工商网监
工商网监
评论