 由一只小猫带咱们走进深度学习的世界吧!
由一只小猫带咱们走进深度学习的世界吧!
首先就由一只小猫带咱们走进深度学习的世界吧!
对于一个输入样本来说,深度学习和机器学习有着相同的目的,就是要把这个样本进行最准确的分类。咱们从肉眼看很容易这是一只猫,因为我们有着这么多年的积累常识嘛!但是计算机可不这么聪明一眼就能看得出来,在计算机中,一个图像是由像素点所构成的。
这里可能有同学对于计算机视觉不是很了解,我简单的介绍下,像素点是一个从0到255范围内的一个正值,那么这个点的大小意味着这个点所对应区域的一个亮度。咱们也可以把一个图片当成一个三维数组比如[256,256,3]这里的256就分别代表了图片的长和宽的大小,最后的3就是图片的颜色通道,不知道通道是什么也不要紧,咱们暂且知道图片是矩阵组成的就好啦!
这个矩阵就是长的这个样子
那么我们所面临的挑战是什么呢?
我们要面对的可不仅仅是这样一只蹲在我们面前可爱的小猫,在实际中有着很多的可能性,比如光照强度,遮蔽程度,角度等等,这些就成为了我们深度学习任务的一个极大的挑战。
这些异形就是我们所面临的挑战
深度学习要解决的最核心也是最基本的问题就是分类任务了,它也是咱们理解深度学习一个最好的入手点。
分类问题的常规套路
一个分类任务的常规套路大致可以分为三点:
1、收集数据并给定标签:
就是我们要制作训练集了,包括data label这两部分,别小看收集数据了,这部其实很麻烦的,没有合适的数据很难训练出优秀的模型的,两个量都很重要,一个是质量一个是数量,对于我们深度学习来说,数量是很重要的,基本上都要以万为基本单位的。
2、训练一个分类器:这步可以说是很核心的一步,分类器的效果好坏决定了我们最终应用的效果,深度学习之所以效果要超过传统的机器学习在部分领域上比如计算机视觉,主要在于深度学习所训练的分类器更强大,这节课咱们只简单的介绍,干货还是在后面的。
3、测试评估:一个好的分类器,不是咱们通过大量的数据和一个强大的模型结构就可以的。在训练好分类器后,一个更重要的点就是我们要去测试和评估,比如准确率,召回率等衡量指标。我们要通过这些指标反复调节模型参数直到得到最好的模型无论是机器学习还是深度学习都离不开这三步,有了这样的一个流程下面我们就来看一看传统的机器学习算法是如何进行分类任务的。
这个就是数据库,简单说下这个数据库有10类标签,就是有10个类别,接下来要做的就是训练一个分类模型啦。
我的这个做法很多同学可能会说我很二,但是为了更好的给那些刚入门(坑)的同学更直观的表达,咱们简单的来乐呵下就好。

用每个图片的像素点所构成的矩阵去算和它像素点差异最小的那几个数据样本是哪几个。虽然做法很二,但这也是一个简单的K近邻问题,我们通过像素点的L1距离(这个看公式吧)去计算输入和所有训练集中的样本的距离然后找出最小的那K个,输入的样本的类别就是那K个里投票和。
这里我要强调的是,我不是用这种做法去说一个分类的流程,而是让大家看到咱们传统做法所需的一些东西。这里咱们在做分类的时候所需的参数有K近邻中的K的大小,还要选择距离公式也就是L的选择,这只是最少的参数选择,要是更复杂的模型我们所需选择的参数就更多了。不同的参数选择可以说对于最终的结果有着很大的影响,这也就是传统的机器学习算法很头疼的一个问题很多东西都需要咱们不断去尝试。那么深度学习一个很强大的地方就是我们并不需要设定很多这样的超参数。
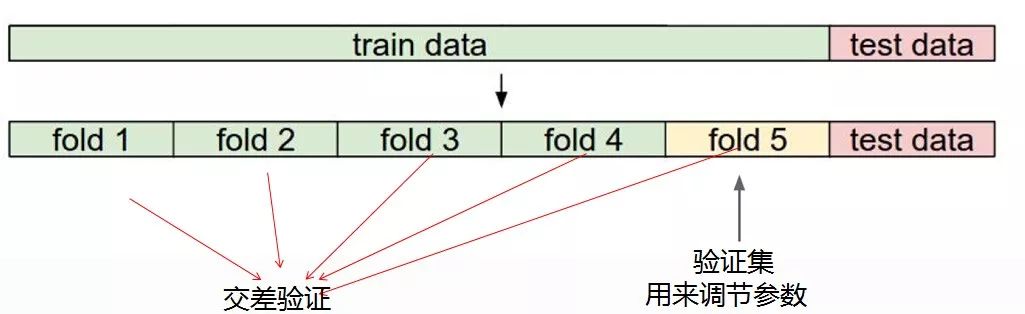
接下来咱们再来强调下上面这张图,这个的目的就是很多同学并没有太多机器学习和实战的基础,需要给大家对数据集的划分有个大致的概念。
我们在训练模型之前的数据准备要把整个数据分成两个大部分,一个是训练数据,一个是测试数据。理论上来说测试数据是很宝贵的,我们只有在最后的时候才能使用测试数据去评估,在训练的过程中决不允许出现测试数据。
还有就是我们还要把训练数据这个大部分切分成几个小份,比如5个小份,这么做的目的是我们还需要验证集,验证集的意思就是我们在训练模型的时候要不断的做一个模型自测试效果的过程,比如用其中的4小份作为训练数据,用另一小份作为验证数据。还有一个知识点要给大家强调下,我们在实际训练模型的时候更多的是使用交差验证,什么是交差呢?就是我们这次取这4个作为训练下次我们再取另外4个作为训练,这样就可以保证咱们训练模型的可靠性更大!
-
分类器
+关注
关注
0文章
152浏览量
13179 -
机器学习
+关注
关注
66文章
8406浏览量
132547 -
深度学习
+关注
关注
73文章
5500浏览量
121105
原文标题:由一只猫看深度学习面临哪些挑战?
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
从零开始走进FPGA世界 V2.0【转】
养一只compass需要什么样的条件?
什么是深度学习?使用FPGA进行深度学习的好处?
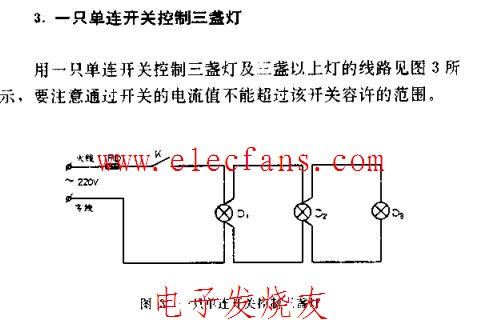
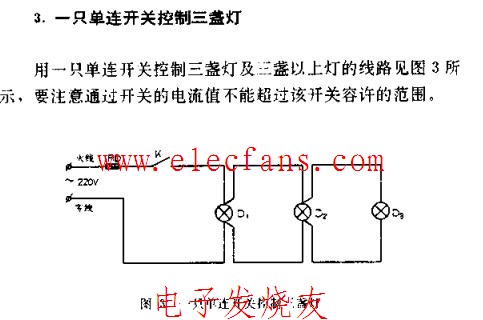

电子玩具--小猫捉鸟电路图
还记得那些年的华硕笔记本电脑吗?让我们一起走进华硕笔记本世界吧!
改进深度学习算法的光伏出力预测方法






 工商网监
工商网监
评论