 寒武纪MLUv01架构采用台积电16FF,MLU-100芯片
寒武纪MLUv01架构采用台积电16FF,MLU-100芯片
寒武纪科技公司与华为海思合作,为麒麟970智能手机芯片组提供AI IP,并为数据中心创建了自己的系列芯片。
麒麟970内部的IP被称为Cambricon-1A,是该公司的第一个可授权IP。当时,查找寒武纪的信息非常困难:它的网站是一系列静态图像,中文嵌入图像本身。有趣的是,我们的AI加速翻译功能应用在华为Mate 10上来翻译网站内容。快进12-18个月,寒武纪网站现在可以互动并提供即将推出的产品的相关信息,包括一些最近发布的信息。
大芯片:走向数据中心
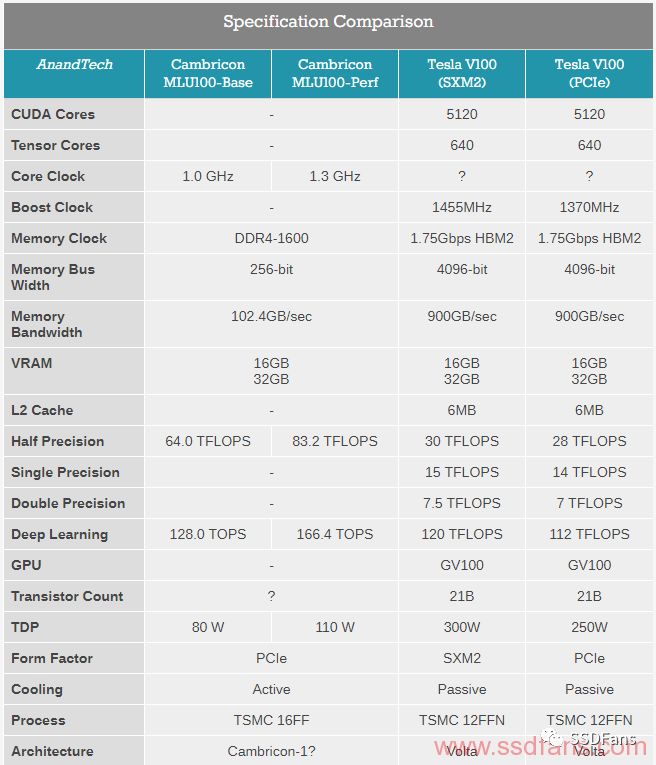
基于台积电16FF,MLU-100是一款80W芯片,在1.0 GHz,或'标准'模式下,使用机器学习算法中常用的8位整数度量,具有64 TFLOPS的传统半精度或128 TOPS功能。寒武纪的首席执行官陈天石博士表示,他们的新芯片具有1.30 GHz的高性能模式,允许83.2 TFLOPS(16位浮点)或166.4 TOPS( 8位整数),但功耗上升到110W。 这在技术上降低了能源效率,但是允许使用更快的芯片。 所有这些数据都依赖于启用稀疏数据模式。
该芯片背后的技术是寒武纪最新的MLUv01架构,该架构被理解为是用于麒麟芯片组的Cambricon-1A的一种变体,但规模更大更快。显然,与移动IP相比,必须对数据和电源管理实施额外的优化。 寒武纪也有它的1H架构和最新公布的1M架构,但是没有公开如何将数据传递到芯片。
WikiChip的David Schor指出,如果提供给商业合作伙伴,这可能是NVIDIA的首次机器学习ASIC竞赛。为此,寒武纪还在制造PCIe卡。
很明显,NVIDIA在这方面拥有强大的用户群和多代产品,以及利用其硬件优势的软件。 Cambricon没有详细说明他们计划如何支持新芯片的SDK,但是它的网站上有一系列的SDK,支持TensorFlow,Caffe和MXNet。
进入数据中心:PCIe
在数据中心中即插即用的最佳方式是通过PCIe卡。 Cambricon的MLU100加速器卡就是这样的:一个PCIe 3.0 x16实现256位16或32 GB DDR4-3200内存,这对于102.4 GB / s的带宽是有好处的。要在NVIDIA上获得大量内存,需要高端显卡,但这些显卡提供多倍的显存带宽。 MLU100卡上的存储器也启用了ECC。
迄今为止的报告称,联想将其卡作为ThinkSystem SR650双Intel Xeon服务器的附加产品; 每台机器最多两个。 从联想网站上看,它目前并不能使用。 鉴于华为在企业中的巨大影响力,我们很可能会看到这些系统中的芯片。
下一代:5TOPS/Watt
另外报道的是新的Cambricon-1M IP,尽管该公司没有提供细节。 WikiChip公司表示,这款新IP主要针对7nm制造,所以当华为/海思开始发布7nm移动处理器,然后进入下一代面向服务器的产品时,我们很可能会看到它。与ARM的IP所宣传的3 TOPS /瓦特相比,这个IP的目标是达到5 TOPS /瓦特。 寒武纪今年晚些时候会有一个培训和推理芯片计划,并在2019年再次进行更新。
-
芯片
+关注
关注
458文章
51475浏览量
429114 -
台积电
+关注
关注
44文章
5711浏览量
167301 -
机器学习
+关注
关注
66文章
8458浏览量
133289
原文标题:华为的麒麟NPU IP制造商寒武纪,生产出一个大AI芯片和PCIe卡
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
寒武纪3000亿市值与GPU厂商密集IPO,AI芯片正是当打之年

寒武纪增资全资子公司上海寒武纪
寒武纪发布2024年度业绩预告
高通明年骁龙8 Elite 2芯片全数交由台积电代工
谷歌Tensor G系列芯片代工转向台积电
台积电美国工厂投产A16芯片,苹果成首批客户
台积电美国工厂启动生产苹果A16芯片
X86架构处理器有哪些优点和缺点
算力概念股寒武纪20cm涨停市值重回千亿
台积电正积极研发并推广背面供电网络(BSPDN)方案
台积电准备生产HBM4基础芯片
移动端芯片性能提升,Armv9架构新升级引发关注
寒武纪2023年报出炉:营收稳健亏损收窄 毛利率达69.16%
“AI芯片第一股”寒武纪发布2023年度业绩快报 亏8.36亿元!





 工商网监
工商网监
评论