 GitHub星数最多的Top 10热门项目
GitHub星数最多的Top 10热门项目
本月的最热机器学习项目出来了!Mybridge对过去一个月的近250个机器学习开源项目进行了排名,甄选出GitHub星数最多的10大热门项目。开源项目是机器学习研究的宝库,你一定能从中找到一个能启发你的有趣项目。
Mybridge对过去一个月的近250个机器学习开源项目进行了排名,甄选出GitHub星数最多的Top 10热门项目。
这个列表中10个项目的平均GitHub星星数:1041⭐️
主题包括:DensePose,图像分类, Mulit-Scale训练,移动AI计算引擎,卫星图像,NLP,Python包,Word detection,NCRF,DALI。
开源项目对程序员来说是很有帮助的。希望你能从中找到一个能启发你的有趣项目。
No.1:DensePose:密集人体姿态估计
DensePose是一种实时的方法,可以将所有2D RGB图像的人体像素映射到身体的3D表面模型。[Github 2901颗星]来自Facebook的研究
密集人体姿态估计(Dense human pose estimation)的目的是将RGB图像的所有人体像素映射到人体的3D表面。DensePose-RCNN是在Detectron框架中实现的,使用的是Caffe2。

作者在这个GitHub存储库中提供了训练和评估DensePose-RCNN的代码。同时还提供了notebook,用于可视化收集的DensePose-COCO数据集,并展示与SMPL模型的对应关系。

DensePose-COCO注释的可视化
项目地址:
https://github.com/facebookresearch/DensePose
No.2:Darts:卷积网络和循环网络的可微分架构搜索
[Github 1128颗星],来自CMU Hanxiao Liu,Yiming Yang以及DeepMind Karen Simonyan等人的研究。
这个GitHub库提供了他们的论文“DARTS: Differentiable Architecture Search”中的代码。在这篇论文中,研究者提出通过以可微分的方式表示任务来解决架构搜索可扩展性的挑战。该方法基于架构表示的连续松弛(continuous relaxation),允许使用梯度下降来有效搜索架构。

该方法能够有效地设计用于图像分类的高性能卷积网络架构(在CIFAR-10和ImageNet上)和用于语言建模的循环网络架构(在Penn Treebank和WikiText-2上), 并且只使用一个GPU,比最先进的非可微分技术快几个数量级。
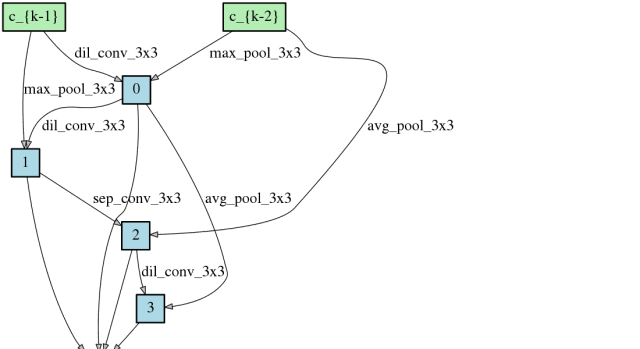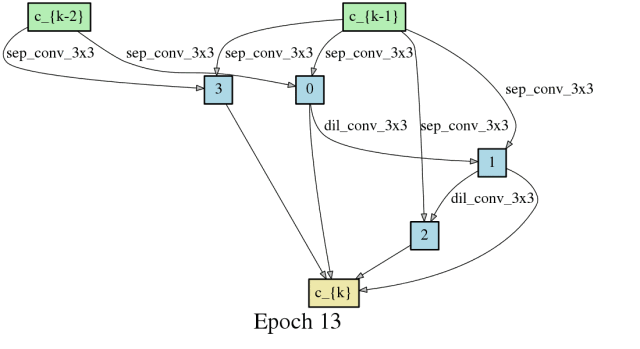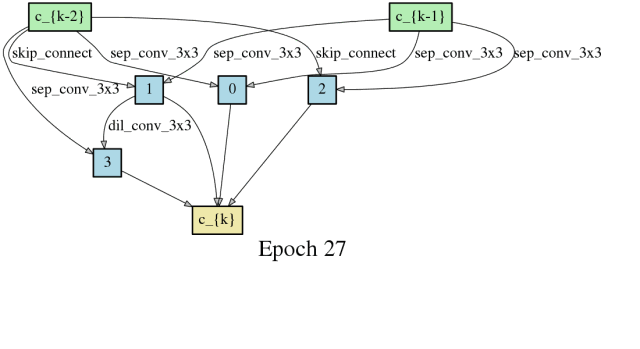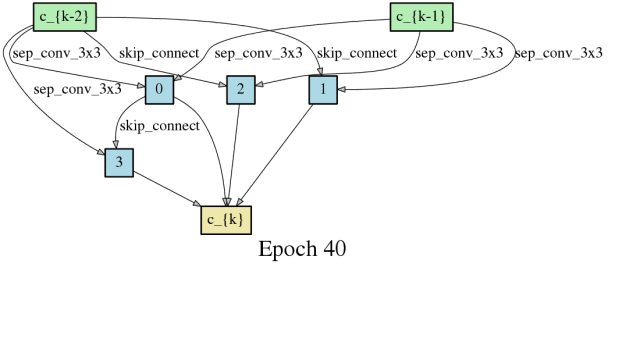
随时间推进,卷积网络架构的搜索

随时间推进,卷积网络和神经网络架构的搜索
项目地址:
https://github.com/quark0/darts
[Github 1352颗星]
SNIPER是一种高效的多尺度(multi-scale)训练方法,用于实例级的识别任务,例如目标检测和实例级分割。SNIPER不是在图像金字塔中处理所有像素,而是有选择地处理ground truth对象周围(也就是芯片)的上下文区域。这大大加快了在低分辨率芯片上运行的多尺度训练。由于其内存的设计十分高效,SNIPER可以在训练过程中受益于batch normalization,并且可以在单个GPU上完成更大batch-sizes 的实例级识别任务。因此,我们不需要跨GPU同步batch-normalization 数据,我们可以训练对象检测器,就像做图像分类一样!
项目地址:
https://github.com/mahyarnajibi/SNIPER
No.4:Mace:专为移动端异构计算平台优化的深度学习推理框架
[Github 2118颗星]。 来自小米
Mobile AI Compute Engine (MACE)是小米开源的移动端深度学习框架,它针对移动芯片特性进行了大量优化,目前在小米手机上已广泛应用,如人像模式、场景识别等。
Mace主要从以下的角度做了专门的优化:
性能
代码经过NEON指令,OpenCL以及Hexagon HVX专门优化,并且采用Winograd算法来进行卷积操作的加速。 此外,还对启动速度进行了专门的优化。
功耗
支持芯片的功耗管理,例如ARM的big.LITTLE调度,以及高通Adreno GPU功耗选项。
系统响应
支持自动拆解长时间的OpenCL计算任务,来保证UI渲染任务能够做到较好的抢占调度, 从而保证系统UI的相应和用户体验。
内存占用
通过运用内存依赖分析技术,以及内存复用,减少内存的占用。另外,保持尽量少的外部 依赖,保证代码尺寸精简。
模型加密与保护
模型保护是重要设计目标之一。支持将模型转换成C++代码,以及关键常量字符混淆,增加逆向的难度。
硬件支持范围
支持高通,联发科,以及松果等系列芯片的CPU,GPU与DSP(目前仅支持Hexagon)计算加速。 同时支持在具有POSIX接口的系统的CPU上运行。
项目地址:
https://github.com/XiaoMi/mace
No. 5:Robosat:用于航空和卫星图像的语义分割工具
[Github 886颗星]。由Salesforce打造
RoboSat是用Python 3编写的一个端到端的pipeline,用于从航空图像和卫星图像中提取特征。特征可以是任何视觉上可区分的东西,例如:建筑物,停车场,道路,或汽车。
RoboSat提供的工具可分为以下几类:
数据准备:为训练特征提取模型创建数据集
训练和建模:用于图像中特征提取的分割模型
post-processing:将分割结果转换为简洁的几何图形
项目地址:
https://github.com/mapbox/robosat
No.6 decaNLP:处理自然语言任务,一个顶十个
[Github 776颗星]
自然语言十项全能(decaNLP)的目标是构建一个能够完成十项自然语言任务的通用模型,这些任务包括:问答、机器翻译、摘要、自然语言推理、情感分析、语义角色标注、关系抽取、目标导向对话、语义分析、常识代词消解。每个任务都被转换为问答问题,以便使用新的多任务问题应答网络(Multitask Question Answering Network,MQAN)。该模型联合学习decaNLP中的所有任务,并且在多任务设置中不使用任何特定于任务的模块或者参数。
项目地址:
https://github.com/salesforce/decaNLP
No.7 Magnitude:一个快速、高效的通用矢量嵌入实用包
[Github 427颗星]
Magnitude是一个功能丰富的Python包和矢量存储的文件格式,用于以快速、高效、简单的方式使用机器学习模型中的向量嵌入(由Plasticity开发)。它逐渐成为“轻量版”的Gensim,但却可以用于NPL之外的领域,作为一种通用的关键向量(key-vector)存储。
项目地址:
https://github.com/plasticityai/magnitude
No.8 Porcupine:由深度学习驱动的设备唤醒词检测引擎
[Github 373颗星]
Porcupine是一款自助式,高精度,轻量级的唤醒字检测引擎。它使开发人员能够构建始终监听(always-listening)语音的应用程序/平台。
自助式:开发人员有权在几秒钟内选择任何唤醒词并构建其模型。
在现实场景中用深度神经网络进行训练
由于它紧凑且计算效率高,使其适用于物联网的应用
跨平台:它是在纯定点ANSI C中实现的。目前支持Raspberry Pi、Android、iOS、watchOS,Linux,Mac和Windows。
可扩展性:它可以同时检测数十个唤醒词,几乎不增加CPU/内存占用。
开源:在这个存储库中找到的任何东西都是Apache 2.0许可的。
项目地址:
https://github.com/Picovoice/Porcupine
No.9 NCRF:神经条件随机场,检测肿瘤转移
[Github 290颗星]
由百度深度学习研究院提出,其文章结构如下(附代码和数据):
NCRF介绍
准备工作
数据介绍
模型介绍
训练
测试
项目地址:
https://github.com/baidu-research/NCRF
No.10:NVIDIA DALI
这是一个包含高度优化的构建模块和用于深度学习应用中数据预处理执行引擎的库。NVIDIA DALI可加速深度学习应用程序的输入数据预处理。 DALI 提供加速不同数据管道的性能和灵活性,作为一个单独的库,可以轻松集成到不同的深度学习训练和推理应用程序中。
DALI的主要亮点包括:
从磁盘读取到准备训练/推理的完整的数据流水线;
可配置图形和自定义操作员的灵活性;
支持图像分类和分割工作量;
通过框架插件和开源绑定轻松实现集成;
具有多种输入格式的便携式训练工作流 - JPEG,LMDB,RecordIO,TFRecord;
通过开源许可证可扩展以满足用户的特定需求
-
图像
+关注
关注
2文章
1089浏览量
40607 -
机器学习
+关注
关注
66文章
8457浏览量
133197 -
数据集
+关注
关注
4文章
1212浏览量
24892
原文标题:【干货】7月机器学习Top 10,GitHub平均1041星!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
2012年模拟行业热门事件大盘点Top10
最新热门电路图设计TOP10精华集锦
分享几个在GitHub上嵌入式相关的开源项目
2018 年 2 月份 GitHub 上最热门的开源项目
总结一份GitHub热门开源项目
GitHub热门项目盘点(值得收藏)
丰田CUE类人机器人创造了新记录 连续执行篮球罚球次数最多
10月份GitHub上最热门的Python开源项目上榜详情
2020年全球热门娱乐应用TOP10榜单出炉
2020年11月Github上最热门的11个开源项目





 工商网监
工商网监
评论