 第一种用于主动双目立体成像系统的深度学习方法
第一种用于主动双目立体成像系统的深度学习方法
本文是计算机视觉顶会ECCV 2018录取论文中备受关注的一篇,来自谷歌&普林斯顿大学的研究人员提出了第一个主动双目立体成像系统的深度学习解决方案,在诸多具有挑战性的场景中展示出最先进的结果。
深度传感器(Depth sensors)为许多难题提供了额外的3D信息,如非刚性重构(non-rigid reconstruction)、动作识别和参数跟踪,从而给计算机视觉带来了革新。虽然深度传感器技术有许多类型,但它们都有明显的局限性。例如,飞行时间系统(Time of flight systems)容易遭受运动伪影和多路径的干扰,结构光(structured light )容易受到环境光照和多设备干扰。在没有纹理的区域,需要昂贵的全局优化技术,特别是在传统的非学习方法中, passive stereo很难实现。
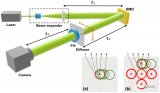
主动双目立体视觉(Active stereo)提供了一种潜在的解决方案:使用一对红外立体相机,使用一个伪随机模式,通过图案化的红外光源对场景进行纹理化(如图1所示)。通过合理选择传感波长,相机对捕获主动照明和被动光线的组合,提高了结构光的质量,同时在室内和室外场景中提供了强大的解决方案。虽然这项技术几十年前就提出了,但直到最近才出现在商业产品中。因此,从主动双目立体图像中推断深度的先前工作相对较少,并且尚未获得大规模的ground truth训练数据。
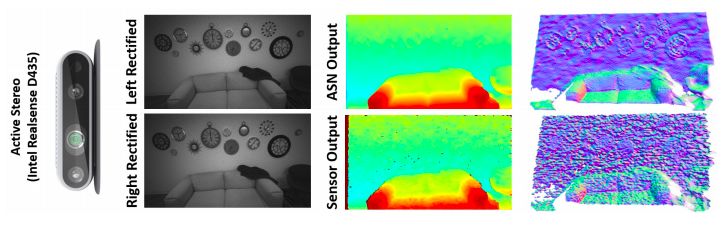
图1:ActiveStereoNet (ASN)通过使用 Intel Realsense D D435相机获得的一对经过修正的红外图像,产生平滑、详细、无量化的结果。
在主动双目立体成像系统中必须解决几个问题。有些问题是所有的双目系统问题共有的,例如,必须避免匹配被遮挡的像素,这会导致过度平滑、边缘变厚和/或轮廓边缘附近出现飞行像素。但是,其他一些问题是主动双目系统特有的,例如,它必须处理非常高分辨率的图像来匹配投影仪产生的高频模式;它必须避免由于这些高频模式的其他排列而产生的许多局部最小值;而且它还必须补偿附近和远处表面投影图案之间的亮度差异。此外,它不能接受ground truth深度的大型主动双目数据集的监督,因为没有可用的数据。
在这篇论文中,我们介绍了ActiveStereoNet,这是主动双目立体成像系统(active stereo systems)的第一个深度学习解决方案。由于缺乏ground truth,我们的方法是完全自我监督的,但它产生了精确的深度,子像素精度是像素的1/30;它没有遭到常见的过度平滑问题,保留了边缘,并且明确地处理了遮挡。
我们引入了一种新的重构误差(reconstruction loss),它对噪声和无纹理补丁(patches)更具稳健性,并且对光照的变化保持不变。我们提出的损失是通过基于窗口的成本聚合和自适应的支持权重方案优化的。这种成本聚合使边缘保留并使损失函数平滑,这是使网络达到引人注目的结果的关键。
最后,我们展示了预测无效区域(如遮挡)的任务是如何在没有ground truth的情况下完成的,这对于减少模糊至关重要。我们对真实数据和合成数据进行了大量的定量和定性的评估,证明了该技术在许多具有挑战性的场景中得到了state-of-the-art的结果。
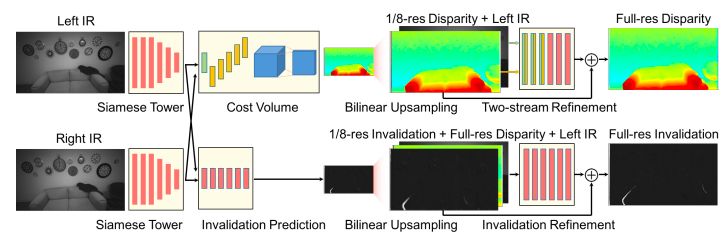
图2:ActiveStereoNet的架构
ActiveStereoNet的架构如图2所示。我们使用一个两阶段的网络,其中一个低分辨率的成本体积被构建来推断第一视差估计。一个双线性上采样后的残差网络用来预测最终视差图。底部的Invalidation Network也被端到端地训练来预测置信度图。

图3:光度损失(左)、LCN损失(中)和建议的加权LCN loss(右)的比较。
我们提出的loss对于遮挡更强健,它不依赖于像素的亮度,也不受低纹理区域的影响。
实验和结果
我们进行了一系列实验来评估ActiveStereoNet(ASN)。除了分析深度预测的准确性,并将其与以前的成果相比之外,我们还提供消融研究的结果,以研究拟损失的每个组成部分会对结果造成什么影响。在补充材料中,我们还评估了我们提出的self-supervised loss 方法在passive (RGB) stereo中的适用性,该方案表现出更高的泛化能力,在许多基准测试中达到了令人印象深刻的结果。
双目立体匹配评估
在本节中,我们使用传统的双目立体匹配指标(如抖动和偏差),定性、定量地将我们的方法在实际数据的实验中与最先进的立体算法进行比较。
抖动与偏差
假设某立体声系统的基线标准为b,焦距为f,子像素视差精度为δ,则视差精度的深度误差e与深度Z的平方成正比。由于视差误差对深度的影响是可变的,一些简单的评估度量(如视差的平均误差)不能有效地反映估计深度的质量。而我们的方法首先标出深度估计的误差,然后计算视差中的相应误差。
为了评估ASN的子像素精度,我们记录了相机在平坦的墙壁前记录的100帧图像,相机距离墙壁的范围从500毫米到3500毫米不等,还有100帧,然后让相机成50度角朝向墙壁,再记录100帧,用来评估倾斜表面上的图像。在本例中,我们将得到的结果与高鲁棒性的平面拟合获得的“ground truth”进行对比评估。
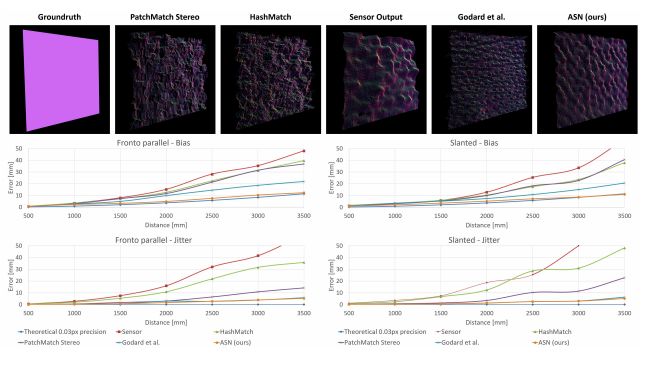
图5.对最新技术的定量评估。
我们的方法的数据偏差降低了一个数量级,子像素精度为0.03像素,而且抖动非常低(参见文本)。我们还展示了距离墙壁3000毫米时,多种方案下预计出现的点云。请注意,尽管距离较远(3米),但其他方法相比,我们的结果噪音更低。
为了表示精度,我们将偏差计算为预测深度和真实值之间的平均误差l1。图5所示为关于我们所用的方法的深度偏差和传感器输出、现有最佳技术的局部立体化方法(PatchMatch,HashMatch),以及我们所使用的最先进的非监督式训练出的模型,并对点云做了表面法线着色处理的可视化操作。我们的系统在距墙壁全部距离上的性能都明显优于其他方法,并且其误差不会随着深度增加而显着增加。我们系统对应的子像素视差精度为1/30像素,这是通过使用上述方程(也在图5中给出)拟合曲线而获得的。这比其他方法的精度(不高于0.2像素)精确一个数量级。
为了表示噪声,我们将抖动(Jitter)计算为深度误差的标准偏差。图5表明,与其他方法相比,我们的方法在几乎每个深度上都能实现最低的抖动。
与现有最优技术的比较
在具有挑战性的场景中对ASN的更多定性评估如图6所示。可以看出,像PatchMatch和HashMatch这样的局部方法无法处理有源光和无源光的混合照明场景,因此会产生不完整的差异图像(缺失像素显示为黑色)。使用半全局方案的传感器输出更适合此类数据,但仍然容易受到图像噪声的影响(请注意第四列中的噪声结果)。相比之下,我们的方法可以产生完整的视差图并保留清晰的边界。

图6.对现有最佳技术的定性评估。我们的方法可以生成详细的视差图。而目前最先进的方法会受到无纹理区域的影响。传感器半全局方案的噪声更大,输出过于平滑。
关于真实序列的更多例子如图8(右)所示,其中我们给出了由表面法线着色的点云。我们的输出保留了所有细节,噪音很低。相比之下,我们使用自监督方法进行训练的网络产生了过度平滑的输出。
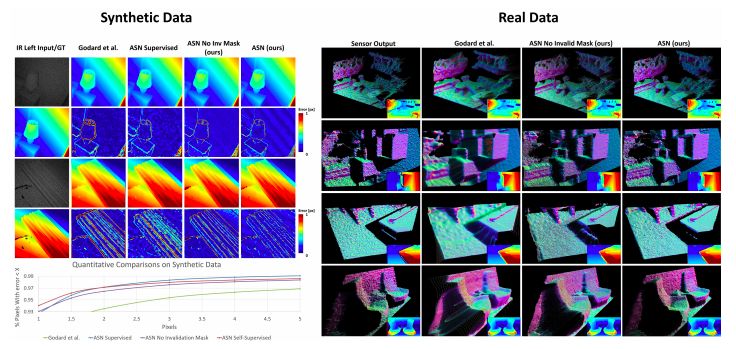
图8:在合成数据和真实数据上的评估
我们的结果也不存在纹理复制问题,这很可能是因为我们使用成本量来明确地对匹配函数进行了建模,而不是直接从像素密度中学习。即使训练数据主要是从办公室环境中捕获的,我们仍然发现,ASN很好地涵盖了各种测试场景,如起居室、游戏室,餐厅和各式各样的目标,比如人、沙发、植物、桌子等。具体如图所示。
讨论、局限性和未来方向
我们在本文中介绍了ActiveStereoNet(ASN),这是第一种用于主动双目立体成像系统的深度学习方法。我们设计了一个新的损耗函数来处理高频模式,照明效果和像素遮挡的情况,以解决自我监督设置中的主动立体声问题。我们的方法能够进行非常精确的重建,子像素精度达到0.03像素,比其他有源立体匹配方法精确一个数量级。与其他方法相比,ASN不会产生过于平滑的细节,可以生成完整的深度图,保留有清晰的边缘,没有乱飞的像素。而失效网络作为一个副产物,能够得出可用于需要遮挡处理的高级应用的视差置信度图。大量实验显示,使用NVidia Titan X显卡和最先进的方法,用于不同具有挑战性场景的处理任务,每帧运行平均时间为15ms。
局限性和未来方向
尽管我们的方法产生了令人信服的结果,但由于成本量的低分辨率,仍然存在透明对象和薄结构的问题。在未来的工作中,我们将提出解决方案来处理更高级任务的实施案例,比如语义分割。
-
成像系统
+关注
关注
2文章
199浏览量
13996 -
深度学习
+关注
关注
73文章
5521浏览量
121669
原文标题:ECCV18:谷歌普林斯顿提出首个端到端立体双目系统深度学习方案
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
双目立体视觉原理大揭秘(一)
双目立体视觉的运用
双目立体视觉在嵌入式中有何应用

一种模糊森林学习方法
一种基于块对角化表示的多视角字典对学习方法
一文详细剖析深度相机之双目成像







 工商网监
工商网监
评论