 基于计算机视觉领域中所提出的图像字幕,能够输出趣味字幕的系统
基于计算机视觉领域中所提出的图像字幕,能够输出趣味字幕的系统
可以毫不夸张地说,笑是一种特殊的高阶功能,且只有人类才拥有。那么,是什么引起人类的笑声表达呢?最近,日本东京电机大学(Tokyo Denki University)和日本国家先进工业科学和技术研究所(AIST)的科学家们提出了一种新方法,通过使用它就能够生成引人发笑的字幕。
想问大家一个问题:什么是能够引起人类笑声的有效表达?在本文中,为了从学术角度思考这个问题,我们用计算机生成了一个能够引人“大笑”的图像字幕(image caption)。我们构建了一个基于计算机视觉领域中所提出的图像字幕,能够输出趣味字幕的系统。此外,我们还提出了“趣味分数”(Funny Score),它能够根据一个评估数据库灵活地给出权重。滑稽分数能够更有效地带出“笑声”从而对模型进行优化。另外,我们构建了一个自收集的BoketeDB,其中包含一个主题(图像)和张贴在“Bokete”上的趣味字幕(文本),这是一个Image Ogiri网站。在实验中,我们通过比较使用所提出的方法获得的结果和使用MS COCO预先训练的CNN + LSTM(这是由人类创建的基线)获得的结果,从而验证所提出的方法的有效性。我们将所提出的方法称为神经玩笑机器(Neural Joking Machine,NJM),该方法使用BoketeDB预训练模型。
图1:NJM从图像输入中生成的有趣字幕样本
可以毫不夸张地说,笑是一种特殊的高阶功能,且只有人类才拥有。在对笑声的分析中,正如维基百科所言,“笑声被认为是构图(模式)的转变”,并且当接受者的构图发生变化时,笑声就会经常发生。然而,笑声的视角在很大的程度上取决于接受者的位置。因此,想要对笑声进行定量测量是非常困难的。最近出现了诸如“Bokete”等网络服务的Image Ogiri,其中,用户在主题图片上发布有趣的字幕,而字幕也会并在类似SNS的环境中进行评估。用户进行竞争以获得最多的“星星”。虽然对笑声进行量化被认为是一项非常困难的任务,但Bokete评估和图像之间的对应关系使得我们我们能够定量地处理笑声。图像字幕是计算机视觉中的一个活跃话题,而且我们认为可以实现幽默的图像字幕。本文的主要贡献如下:
我们基于最近在计算机视觉领域的图像字幕研究,提出了一个用于趣味字幕生成器的框架。
我们定义了趣味分数(Funny Score),这是一个基于数据库中现有滑稽字幕评估的权重系统。而这个趣味分数常用于损失函数。
我们收集了数据以从Web服务Bokete上创建BoketeDB。该数据库包含999,571张图像和字幕对。
BoketeDB
在实验部分,我们将所提出的基于趣味分数和BoketeDB预训练参数的方法与MS COCO 预训练的 CNN + LSTM所提供的基线进行了比较。我们还将NJM的结果与人类所提供的趣味字幕进行比较。在人类的评估中,该方法所提供的结果排名要低于人类所提供的结果(22.59%VS 67.99%),但排名要高于基线(9.41%)。最后,我们显示了若干张图像中所生成的趣味字幕。

图2:所提出的有趣字幕生成的CNN + LSTM体系结构
相关研究
凭借在深度神经网络(DNNs)所取得的重大研究进展,我们发现卷积神经网络和循环神经网络(CNN+RNN)的组合,是一种用于特征提取和序列处理的成功模型。尽管没有明确的划分,但CNN通常用于图像处理,而RNN通常用于文本处理。此外,这两个领域是相互统一的。一项成功的应用是使用CNN+LSTM(CNN+长短期记忆)生成图像字幕。该技术可以从图像输入中自动生成文本。然而,我们认为图像字幕需要人类的直觉和情感。在本文中,我们将帮助引导一个图像字幕进行有趣的表达。接下来,我们将介绍幽默图像字幕生成的相关研究。
Wang等人提出了一种自动“meme”生成技术。meme是一种有趣的图像,通常包含幽默文字。Wang等人通过统计分析meme和评论之间的相关性,从而对概率依赖关系(例如图像和文本的依赖关系)进行建模,并自动生成meme。
Chandrasekaran等人通过构造一个分析器来量化图像输入中的“视觉幽默”,从而对图像进行幽默增强。他们还构建了包含有趣的(3200张)和无趣的(3200张)人类标记图像在内的数据集来评估视觉幽默。可以通过定义5个阶段来训练一张图像的“趣味性”。
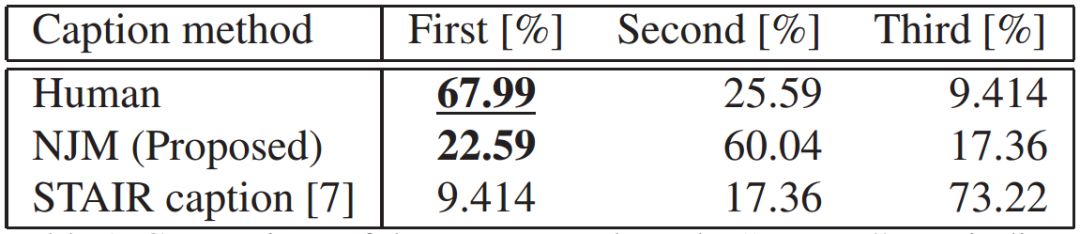
图3:输出结果的比较:“Human”行表示人类用户所提供的字幕,且在Bokete网站上排名最高。“NJM”行表示应用所提出的基于Funny Score和BoketeDB的模型生成的结果。“STAIR字幕”栏表示MS COCO的日语翻译结果。
所提出的方法
我们通过使用所提出的滑稽分数进行权重评估来对趣味字幕生成器进行有效的训练。我们采用CNN + LSTM作为基准,但我们一直在探索有效的评分函数和数据库构建。我们将所提出的方法称为神经玩笑机器(NJM),它是与BoketeDB预训练模型相结合的。
CNN + LSTM
所提出方法的流程如图2所示。基本上,我们采用了Show和Tell中使用的CNN + LSTM模型,但CNN被ResNet-152替代为图像特征提取方法。接下来,我们将详细描述如何使用滑稽分数计算损失函数。该函数能够适当地评估星星的数量和它的“趣味性”。
趣味分数(Funny Score)
Bokete Ogiri网站使用星星的数量来评估字幕的趣味程度。用户对已发布的字幕的“趣味性”进行评估,并为字幕指定一至三颗星。因此,有趣的标题往往会被分配更多的星星。因此,我们关注的是星星的数量,以提出一种有效的训练方法,其中,趣味分数使得我们能够评估字幕的趣味性。根据我们先前实验的结果,拥有100颗星星的趣味分数被视为阈值。换句话说,当星星的数量小于100时,趣味分数输出损失值L;相反,当星星的数量超过100时,趣味分数返回L -1.0。损失值L是用LSTM进行计算的,作为每个小批量的平均值。
图4.使用所提出的NJM获得的可视化结果
总而言之,在本文中,我们提出了一种方法,通过使用它能够生成引人发笑的字幕。我们构建了Bokete DB,其中包含在Bokete Ogiri网站上发布的一个主题(图像)和相应的有趣字幕。通过权重评估,我们有效地训练了一个带有趣味分数的趣味字幕生成器。虽然我们以CNN+LSTM为基准,但我们始终在探索一种有效的评分函数和数据库结构。本次研究的实验表明,NJM比基准STAIR字幕要有趣得多。
-
图像
+关注
关注
2文章
1084浏览量
40461 -
生成器
+关注
关注
7文章
315浏览量
21010 -
计算机视觉
+关注
关注
8文章
1698浏览量
45993
原文标题:「正经字幕」太无聊?用「神经玩笑机」就可以生成逗你笑的趣味字幕
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
计算机视觉领域的关键技术/典型算法模型/通信工程领域的应用方案
深度学习与传统计算机视觉简介

基于计算机视觉领域中的特征检测和匹配研究





 工商网监
工商网监
评论