 迪尼斯:可以对用户全身进行3D的AR替换方案
迪尼斯:可以对用户全身进行3D的AR替换方案
今年年初,我们曾提到过Facebook的一个可以进行全身识别的技术(Facebook为未来全身AR打下基础),这项技术可以用于对全身的AR替换,但当时只能做2D的识别,因此Facebook还在做进一步的研究优化。有趣的是,最近迪斯尼研究人员发表了一篇论文,可以对用户全身进行3D的AR替换。
迪斯尼提出的这项技术被称为AR Poser,从这个名字也看得出它的用途,即用于让米老鼠、达斯维达、钢铁侠等IP人物模仿用户的动作摆出姿势,然后让用户拍照。
简单来说,AR Poser的原理可以分为三个部分。第一步和我们之前提过的诸多动捕系统类似,是将移动设备的摄像头拍摄到的图像传输至处理器,然后通过卷积神经网络等手段识别出目标的轮廓,这一技术我们在之前的动捕技术中已经讲过多次,就不赘述了。
第二步也很简单,就是从用户的轮廓中估计出骨骼姿势,这同样是最近几个动捕方案中采用了的技术,只是AR Poser的骨骼估计更加粗略,手部等位置都被忽略掉了。
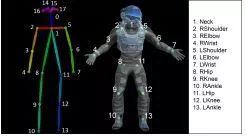
第三步是比较新颖的部分,和一般的动捕方案一样,AR Poser也需要根据骨骼姿势重新渲染3D图像,区别在于,为了减少数据处理的强度,AR Poser在数据集中预设了一些姿势,在得出骨骼姿势后,AR Poser会将骨骼姿势与数据集中预设的姿势对比,选出最接近的一个,然后直接由此渲染最终图像。这种做法的好处是计算量少,另外动捕方案捕捉精度不足的脚踝等部位也更加精确,缺点就是姿势的数量多寡直接影响用户体验。
现在,AR Poser的数据集中一共包含了12个相关的姿势,这12个姿势是从AR Poser的体验者的姿势中总结的,当然数量的确还是太少。另外,据论文中的数据,从移动设备拍摄到图像,到2D骨架估计,再到在移动设备上执行3D的姿势匹配,整个过程大约需要2秒钟。
将AR Poser与Facebook的方案对比,AR Poser得到的是3D图像,但二者需要的计算量基本相当(AR Poser只多出一个对比的过程),但AR Poser显然无意于实时的动捕,因此捕捉的速度相对更慢一些。
最后说一句,AR Poser有几个比较明显的缺陷,第一,就是数据集中可匹配的姿势数量太少。第二呢,目前AR Poser只解决了身体关节的姿势估计,但不包括脸的表情和手指姿势的估计,因此,AR Poser的识别无法区分手部动作不同的身体姿势,在将来的优化中,迪斯尼会考虑用全身匹配+手部姿势匹配两步来完成;最后,当用户变化姿势时,AR影像会直接重新渲染,因此,由于两次对用户身材识别的误差,渲染结果也可能会出现大小不同的情况,造成视觉上的不适,在将来的优化中,将会通过调整肩膀和脚的比例大小来解决这个问题。
考虑到迪斯尼对AR的应用一贯偏向于宣传和IP方面,ARPoser可能将会应用于电影宣传,例如将它应用到电影海报中,让观众和更真实的AR形象合影等等,可能在不久的将来,就可以看到电影海报和主题公园景点中AR Poser的应用。
-
3D
+关注
关注
9文章
2921浏览量
108130 -
Ar
+关注
关注
24文章
5116浏览量
170335
原文标题:迪斯尼的AR化身方案
文章出处:【微信号:ARchan_TT,微信公众号:AR酱】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TechWiz LCD 3D应用:局部液晶配向

腾讯混元3D AI创作引擎正式发布
腾讯混元3D AI创作引擎正式上线
自带尺寸标注的3D预览为制造商组件提供更强劲的客户体验
TechWiz LCD 3D应用:局部液晶配向
3D打印技术,推动手板打样从概念到成品的高效转化
发掘3D文件格式的无限潜力:打造沉浸式虚拟世界






 工商网监
工商网监
评论