 一种新颖而高效的增强校准度量方法用于二值前景图的评估
一种新颖而高效的增强校准度量方法用于二值前景图的评估
图像分割是以人眼识别为基础,而人眼识别是从整体到局部的分割方式。本文首次提出了一种模拟人眼判别的新指标,结果远优于现有方法,并证明其与人眼判别结果更加一致。
图像分割往往是以人眼识别为基础的,而人眼识别是从整体到局部的分割方式。本文从整体和局部两个方向出发,提出了一种新颖而高效的增强校准度量方法(E-measure)用于二值前景图的评估, 通过简单地结合局部信息与全局信息得到了非常可靠的评价结果。
对于GT(GroundTruth,真值图)与分割算法预测的FM (ForegroundMap,前景图),图像评价指标的意义即为计算FM与GT的相似度,为介于0-1之间的值(可以看作概率),1表示完全一样,而0则根据不同的算法有不同的结果,认为是完全不一样(或者与GT正好相反)。GT往往是研究人员手工标注的,
一般认为GT代表的是人眼分割的结果。而评价指标算法的目标,就是取得跟人眼进行图像分类一样的结果。而目前广泛使用的IOU是基于局部信息的误差度量(像素级别),而忽略了图像的全局信息,从而导致其评估不准确。
E-measure是基于局部像素信息差别与全局均值信息的评估方法,我们在5个基准数据集上采用5个元度量证明了E-measure远远优于已有的度量方法,并且在我们提出的人眼排序数据集上取得了最好的结果,证明其与和人的主观评价具有高度一致性。
问题引出:管中窥豹,只可见一斑
评价指标的合理与否对一个领域中模型的发展起到决定性的作用,现有的前景图检测中应用最广泛的评价指标为IOU(Intersection-Over-Union,交并集),如图1, IOU的公式可表示为公式1。
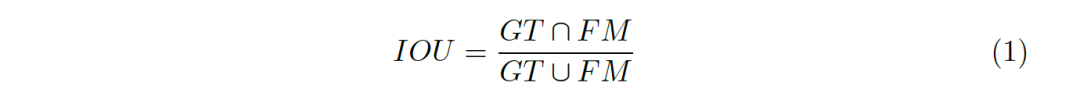
图1:IOU的形象化表示
不难看出IOU是基于局部像素差异的评估方法,缺失了全局信息。如图2所示,(d)中所示不过是噪声图,很明显(c)中的图与(b) 中GT更相似,而(d)实际上可能只与全白或者全黑的前景图结果差不多,而对于全白或全黑图,我们可以认为是不相似的(但是并非相似度值为0,事实上为0一般表示完全相反)。而在通过IOU算法的结果却告诉我们,(d)比(c)更好!这显然是不合理的。
图2:不同类型前景图FM的评价对比
只基于局部像素差异对计算机来说或许是有效的,但是不符合人眼分割图像的机制。我们来实验分析一个简单的例子,如图3,蓝色范围为GT,红色为FM。可以看出,(a)和(b)的FM形状差别很大,但是其与GT的交却完全一样,导致得到完全一样的结果。
图3:IOU简单分析,蓝色范围为GT,红色为检FM,(a)与(b)中交集面积一样
因为IOU只基于局部像素差异进行评估,导致其只能得到一个局部最优结果,而很难得到全面的评估结果。我们需要一个全面的,符合人眼视觉的评价指标。
解决方案:眼观六路,耳听八方
由于当前的评价指标都是考虑单个像素点的误差,缺少全局信息的考量,从而导致评估不准确。为此,我们考虑将局部信息与全局信息结合进行度量。
图4:(b)是原始图像(a)的分割结果,Map1(c)和Map2(d)分别为两个算法分割的结果
我们先来看一个例子,从图4中两个分割算法检测的结果Map1和Map2中,我们判断其结果与GT的相似度会考虑到全局的相似度,如整个鹿的身体部分。通过这一判断,感知两者的相似度差异较小。进而进行局部的细节判断(见图 5})。我们发现与Map1相比,Map2分割结果包含了更多细节(脚),从而,如图 6所示,我们会认为Map2的的分割结果优于Map1。
图5:(b)是原始图像(a)的分割结果,Map1(c)和Map2(d)分别为两个算法分割的结果
图6:(b)是原始图像(a)的分割结果,Map1(c)和Map2(d)分别为两个算法分割的结果
1、结合全局信息与局部信息
我们考虑将图像级的统计信息纳入考量范围,选择全局的像素均值μ作为图像级的统计信息,因为全局均值能代表图像全局的信息而且计算简单。如图7中(c)(d)所示,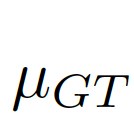
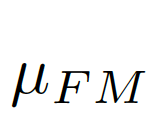
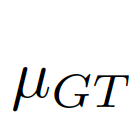 ,
,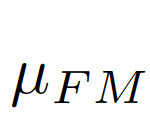 之差作为结合全局信息的偏差矩阵
之差作为结合全局信息的偏差矩阵
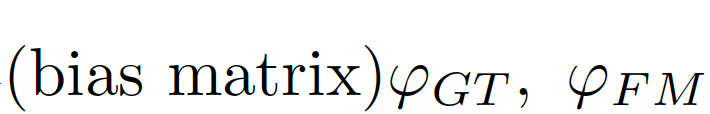
。
2、误差估计
计算偏差矩阵(bias matrix)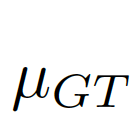
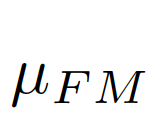
偏差矩阵为[0-1]之间的连续值,我们使用对齐矩阵(alignment matrix)ξ来评价偏差矩阵间的误差:
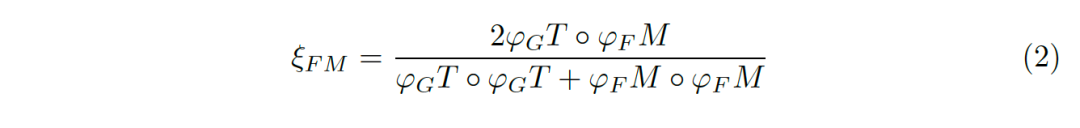
图片7:结合全局信息与局部信息。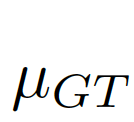
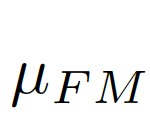
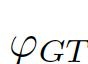 ,
,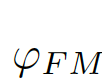 为结合全局信息与局部信息的偏差矩阵(bias matrix)
为结合全局信息与局部信息的偏差矩阵(bias matrix)
其中 为哈达玛乘,分子
为哈达玛乘,分子
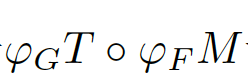
价误差,而
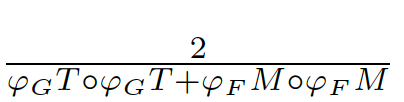
将评估结果缩放到[-1,1]之间,其中-1表示完全相反,而1表示完全相同。即对于每个包含全局信息的局部值误差,我们可以计算出一个[-1,1]之间的误差估计。
3、非线性变换
我们需要一个[0,1]之间的评价指标,因此需要将[-1,1]的值域缩放到[0,1]之间。对于一个随机分类器输出的二分类结果,即随机生成的FM,其与GT的误差应该是均匀的,即其误差应该均匀地分布在[-1.1] 之间,这样我们可以直接使用线性的变换将其值域缩放到[0,1](例如采用
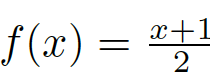
)。
但是事实上,所有的分类器应该都要比随机分类器要好得多,也就是说许多方法的输出FM都是与GT相似而极少相反,即评价得分绝大部分集中于[0,1]之间而只有极少部分出现在[-1,0],在此情况下继续采用线性函数进行值域缩放就不再合适,因为这会导致绝大部分的结果集中到0.5以上的结果而导致缺乏区分度。其次,人眼评估的结果是评估FM与GT的相似度的,而非不相似度(或者负相似度),这也说明再使用线性缩放是不合适的。而简单地将所有[-1,0]之间的值置为0(如神经网络中非常著名的relu激活函数)会丢失一些评估结果,因此不可取。
基于上述分析,我们提出非线性的变换函数:
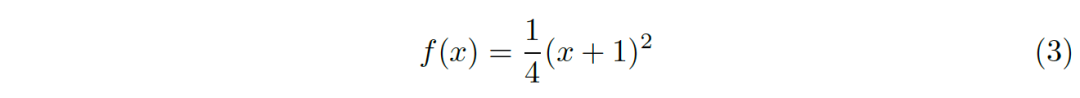
该函数其实只是对上述函数
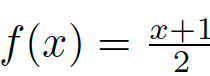
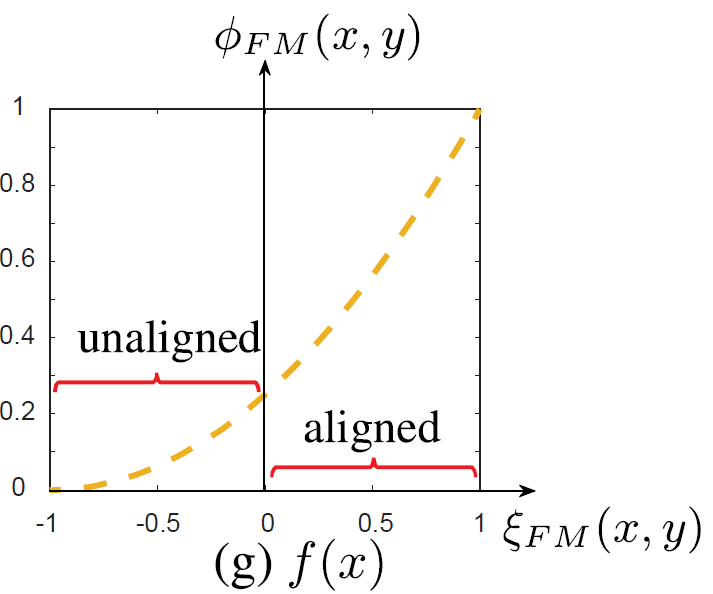
图8:非线性变换函数,其将[-1,0]之间的值缩放到一个较小的范围,而将[0,1]之间的值缩放到较大的范围
4、综合估计
我们将所有的误差缩放到[0,1]之间,便得到符合范围的误差结果(4):
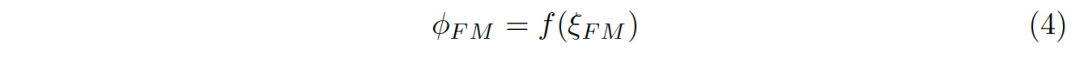
E-measure定义为所有位置误差结果的综合:
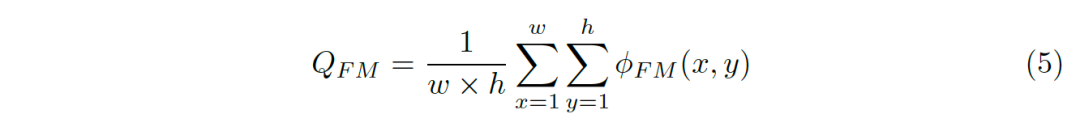
元度量实验证明有效性
为了证明指标的有效性和可靠性,研究人员采用元度量的方法来进行实验。通过提出一系列合理的假设,然后验证指标符合这些假设的程度就可以得到指标的性能。简而言之,元度量就是一种评测指标的指标。实验采用了5个元度量:
元度量1:应用排序
推动模型发展的一个重要原因就是应用需求,因此一个指标的排序结果应该和应用的排序结果具有高度的一致性。即,将一系列前景图输入到应用程序中,由应用程序得到其标准前景图的排序结果,一个优秀的评价指标得到的评价结果应该与其应用程序标准前景图的排序结果具有高度一致性。如下图9所示。
图9
元度量2:最新水平 vs.通用结果
一个指标的评价原则应该倾向于选择那些采用最先进算法得到的检测结果而不是那些没有考虑图像内容的通用结果(例如中心高斯图)。如下图10所示。
图10
元度量3:最新水平 vs.随机结果
一个指标的评价原则应该倾向于选择那些采用最先进算法得到的检测结果而不是那些没有考虑图像内容的随机结果(例如高斯噪声图)。如图2所示。
元度量4:人工排序
人作为高级灵长类动物,擅长捕捉对象的结构,因此前景图检测的评价指标的排序结果,应该和人的主观排序具有高度一致性。我们通过从所有数据集中按比例,通过人随机选择符合人眼排序的前景图组,组成人工排序数据集FMDatabase。如下图11所示。
图11
元度量5:参考GT随机替换
原来指标认定为检测结果较好的模型,在参考的Ground-truth替换为错误的Ground-truth时,分数应该降低。如图12所示。
图12
实验结果
本文在5个具有不同特点的、具有挑战性数据集上进行了广泛的测试,以验证指标的稳定性、鲁棒性。

图13
实验结果表明:我们的指标分别在PASCAL, ECSSD, SOD 和HKU-IS数据集上具有更强的鲁棒性和稳定性。同时在FMDatabase(MM4)上,我们的指标也具有最好的结果。
-
图像分割
+关注
关注
4文章
182浏览量
18078 -
数据集
+关注
关注
4文章
1212浏览量
24964
原文标题:【图像分割里程碑】南开提出首个人眼模拟分割指标,性能当前最优
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
实例分析:分享一种新颖实用的异常信号捕获方法
基于助听器开发的一种高效的语音增强神经网络
一种基于高效采样算法的时序图神经网络系统介绍
一种基于图聚类的安全态势评估方法
一种新颖的精密陀螺电源

一种新颖、高效且易于计算的结构性度量来评估非二进制前景图







 工商网监
工商网监
评论