 实现海量数据分析及可视化的简便方法
实现海量数据分析及可视化的简便方法
【新智元导读】近期,Kaggle发布了新的数据分析及可视化工具——Kaggle Kerneler bot,用户只需上传数据集,便可用Python为用户自动获取相关的深度数据分析结果。本文将带领读者体验一下这款便捷而又高效的工具。
Kaggle Kerneler bot是一个自动生成的kernel,其中包含了演示如何读取数据以及分析工作的starter代码。用户可以进入任意一个已经发布的项目,点击顶部的“Fork Notebook”来编辑自己的副本。接下来,小编将以最热门的两个项目作为例子,带领读者了解该如何使用这款便捷的工具。
好的开始是成功的一半!
要开始这个探索性分析(exploratory analysis),首先需要导入一些库并定义使用matplotlib绘制数据的函数。但要注意的是,并不是所有的数据分析结果图像都能够呈现出来,这很大程度上取决于数据本身(Kaggle Kerneler bot只是一个工具,不可能做到Jeff Dean或者Kaggle比赛选手们那么完美的结果)。
In [1]:
frommpl_toolkits.mplot3dimportAxes3Dfromsklearn.decompositionimportPCAfromsklearn.preprocessingimportStandardScalerimportmatplotlib.pyplotasplt#plottingimportnumpyasnp#linearalgebraimportos#accessingdirectorystructureimportpandasaspd#dataprocessing,CSVfileI/O(e.g.pd.read_csv)
在本例中,一共输入了12个数据集。
In [2]:
print(os.listdir('../input'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/007_nagato_yuki'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/046_alice_margatroid'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/065_sanzenin_nagi'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/080_koizumi_itsuki'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/096_golden_darkness'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/116_pastel_ink'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/140_seto_san'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/144_kotegawa_yui'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/164_shindou_chihiro'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/165_rollo_lamperouge'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/199_kusugawa_sasara'))print(os.listdir('../input/moeimouto-faces/moeimouto-faces/997_ana_coppola'))
接下里,用户在编辑界面中会看到四个已经编好的代码块,它们定义了绘制数据的函数。而在发布后的页面,这些代码块会被隐藏,如下图所示,只需单击已发布界面中的“code”按钮就可以显示隐藏的代码。
准备就绪!读取数据!
首先,让我们先看一下输入中的第一个数据集:
In [7]:
nRowsRead = 100 # specify ‘None’ if want to read whole file# color.csv may have more rows in reality, but we are only loading/previewing the first 100 rowsdf1 = pd.read_csv(‘。。/input/moeimouto-faces/moeimouto-faces/080_koizumi_itsuki/color.csv’, delimiter=‘,’, nrows = nRowsRead)df1.dataframeName = ‘color.csv’nRow, nCol = df1.shapeprint(f‘There are {nRow} rows and {nCol} columns’)
那么数据长什么样子呢?
In [8]:
df1.head(5)
Out [8]:
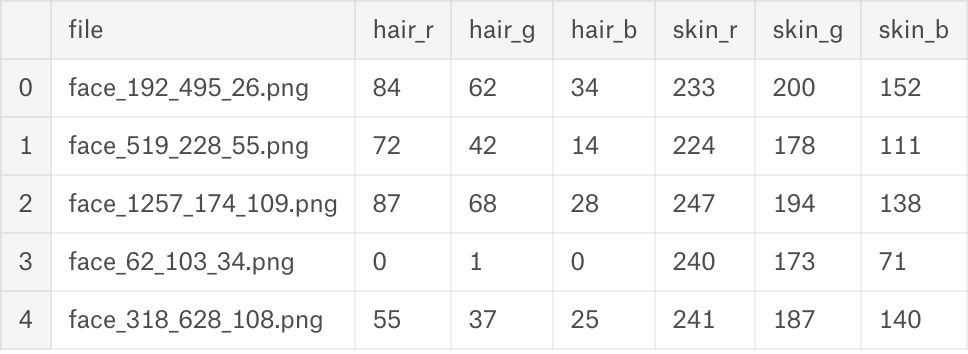
数据可视化:仅需简单几行!
样本的柱状图:
In [9]:
plotHistogram(df1, 10, 5)
二维和三维的PCA图:
In [10]:
plotPCA(df1, 2) # 2D PCAplotPCA(df1, 3) # 3D PCA
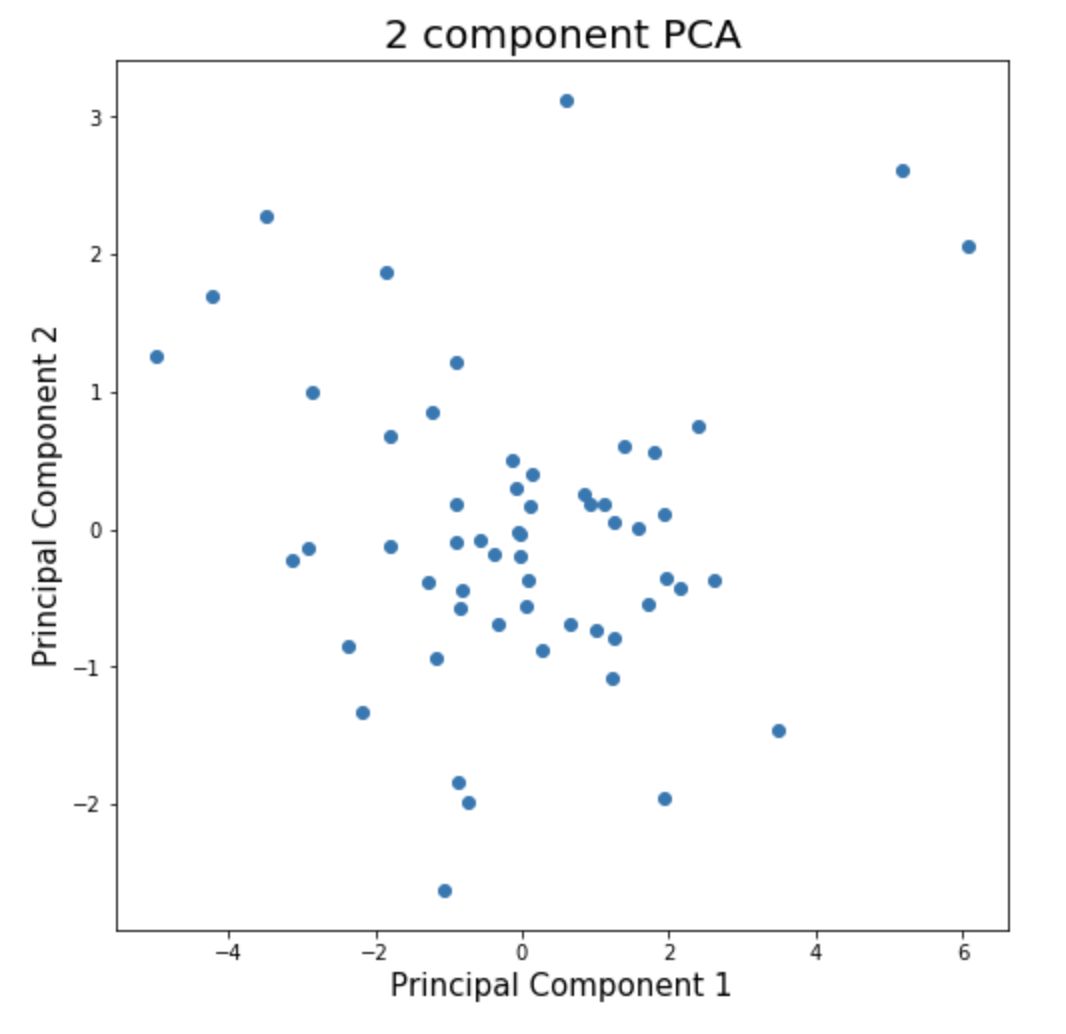
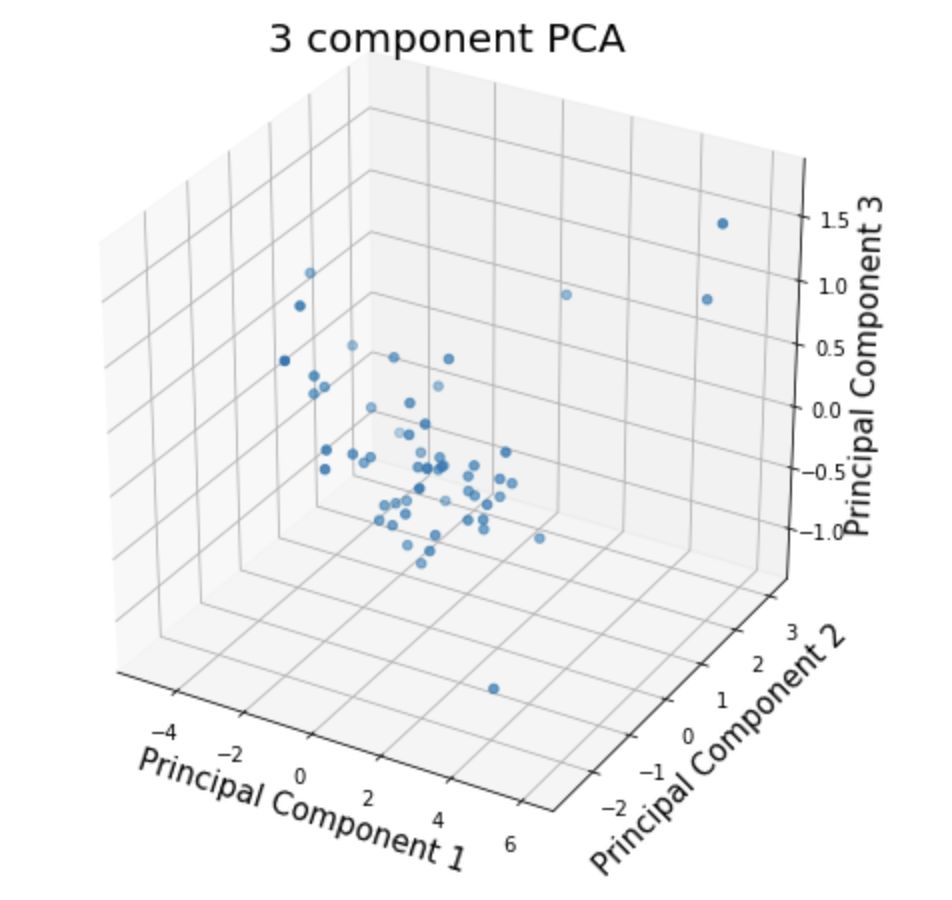
同理,更换数据集文件的路径,也可以得到其它数据对应的结果。
当然,除了上述几种可视化的结果外,根据输入数据以及需求的不同,也可以得到其它数据分析可视化结果,例如:
相关矩阵:
In [11]:
plotCorrelationMatrix(df1, 8)
散射和密度图:
In [12]:
plotScatterMatrix(df1, 20, 10)
针对数据分析、数据可视化工作,Kaggle kerneler bot应当说是相当的便捷和高效了。那么你是否也想尝试一下呢?
-
可视化
+关注
关注
1文章
1203浏览量
21081 -
数据分析
+关注
关注
2文章
1462浏览量
34207
原文标题:Kaggle放大招:简单几步实现海量数据分析及可视化
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论