 一种利用强化学习来设计mobile CNN模型的自动神经结构搜索方法
一种利用强化学习来设计mobile CNN模型的自动神经结构搜索方法
神经结构自动搜索是最近的研究热点。谷歌大脑团队最新提出在一种在移动端自动设计CNN模型的新方法,用更少的算力,更快、更好地实现了神经网络结构的自动搜索。
为移动设备设计卷积神经网络(CNN)模型是很具挑战性的,因为移动设备的模型需要小,要快,而且仍然要求准确性。尽管在这三个维度上设计和改进模型已经有很多研究,但由于需要考虑如此多的结构可能性,手动去权衡这些维度是很有挑战性的。
在这篇论文中,谷歌大脑AutoML组的研究人员提出一种自动神经结构搜索方法,用于设计资源有限的移动端CNN模型(mobile CNN)。
Jeff Dean在推特推荐了这篇论文:这项工作提出将模型的计算损失合并到神经结构搜索的奖励函数中,以自动找到满足推理速度目标的高准确率的模型。
在以前的工作中,移动延迟(mobile latency)通常是通过另一个代理(例如FLOPS)来考虑的,这些代理经常不准确。与之前的工作不同,在我们的实验中,我们通过在特定平台(如Pixel phone)上执行模型,从而直接测量实际的推理延迟(inference latency)。
为了进一步在灵活性和搜索空间大小之间取得平衡,我们提出了一种新的分解分层搜索空间(factorized hierarchical search space),允许在整个网络中的层存在多样性。
实验结果表明,我们的方法在多个视觉任务中始终优于state-of-the-art的移动端CNN模型。在ImageNet图像分类任务中,我们的模型在Pixel phone上达到74.0%的top-1 精度(延迟为76ms)。达到相同的top-1精度的条件下,我们的模型比MobileNetV2快1.5倍,比NASNet快2.4倍。在COCO对象检测任务中,我们的模型实现了比MobileNets更高的mAP质量和更低的延迟。
Platform-Aware神经结构搜索
具体来说,我们提出一种用于设计移动端的CNN模型的自动神经结构搜索方法,称之为Platform-Aware神经结构搜索。图1是Platform-Aware神经结构搜索方法的总体视图,它与以前的方法的主要区别在于延迟感知多目标奖励(latency aware multi-objective reward)和新的搜索空间。
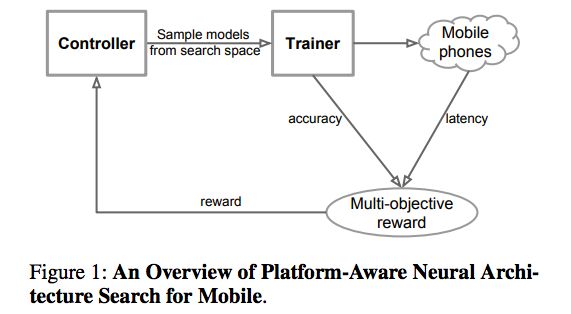
图1:Platform-Aware神经结构搜索的概览
这一方法主要受到两个想法的启发:
首先,我们将设计神经网络的问题表述为一个多目标优化问题,这个问题要考虑CNN模型的准确性和推理延迟。然后,我们使用基于强化学习的结构搜索来找到在准确性和延迟之间实现最佳权衡的模型。
其次,我们观察到先前的自动化结构搜索方法主要是搜索几种类型的cells,然后通过CNN网络反复堆叠相同的cell。这样搜索到的模型没有考虑由于模型的具体形状不同,卷积之类的操作在延迟上有很大差异:例如,2个3x3的卷积具有同样的理论FLOPS,但形状不同的情况下,可能 runtime latency是不同的。
在此基础上,我们提出一个分解的分层搜索空间(factorized hierarchical search space),它由很多分解后的块(factorized blocks)组成,每个block包含由分层子搜索空间定义的层的list,其中包含不同的卷积运算和连接。
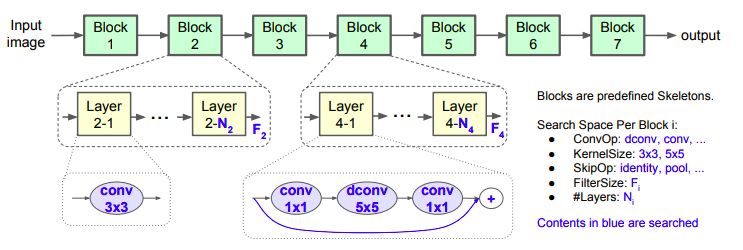
图3:Factorized Hierarchical搜索空间
我们证明了,在一个架构的不同深度应该使用不同的操作,并且可以使用利用已测量的推理延迟作为奖励信号一部分的架构搜索方法来在这个巨大的选择空间中进行搜索。
总结而言,这一研究的主要贡献有:
我们提出一种基于强化学习的多目标神经结构搜索方法,该方法能够在低推理延迟的条件下找到高精度的CNN模型。
我们提出一种新的分解分层搜索空间(factorized hierarchical search space),通过在灵活性和搜索空间大小之间取得适当的平衡,最大限度地提高移动设备上模型的资源效率。
我们在ImageNet图像分类和COCO对象检测两个任务上,证明了我们的模型相对state-of-the-art的mobile CNN模型有显著改进。
MnasNet的结构
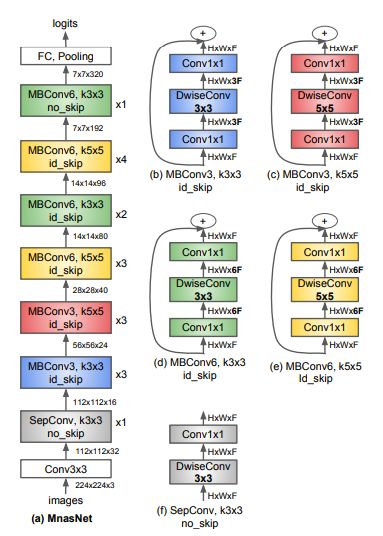
图7:MnasNet的结构
图7的(a)描绘了表1所示的baseline MnasNet的神经网络结构。它由一系列线性连接的blocks组成,每个block由不同类型的layer组成,如图7(b) - (f)所示。此外,我们还观察到一些有趣的发现:
MnasNet有什么特别之处呢?
为了更好地理解MnasNet模型与之前的 mobile CNN模型有何不同,我们注意到这些模型包含的5x5 depthwise的卷积比以前的工作(Zhang et al.1188; Huang et al.1188; Sandler et al.1188)的更多,以前的工作一般只使用3x3 的kernels。实际上,对于depthwise可分离的卷积来说,5×5 kernels 确实比3×3 kernels更具资源效率。
layer的多样性重要吗?
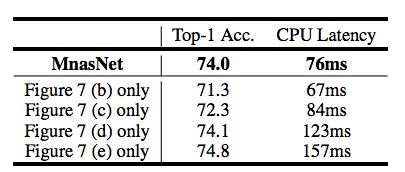
表3
我们将MnasNet与它的在整个网络中重复单一类型的层的变体进行了比较。如表3所示,MnasNet比这些变体在精度和延迟之间的权衡表现更好,这表明在资源有限的CNN模型中,layer的多样性相当重要。
实验结果
ImageNet分类性能
我们将所提出的方法应用于ImageNet图像分类和COCO对象检测任务。
表1展示了本模型在ImageNet上的性能。
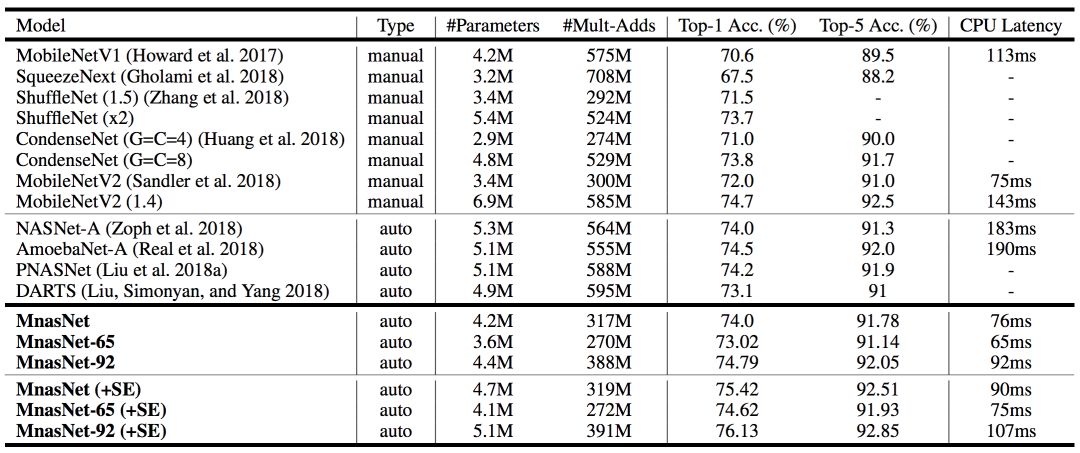
表1:在ImageNet上进行分类的性能结果
本文将MnasNet模型与手动设计的移动模型以及其它自动化方法做了比较,其中MnasNet是基准模型。MnasNet-65和MnasNet-92是同一体系结构搜索实验中不同延迟的两种模型(用于比较)。其中,“+SE”表示附加的squeeze-and-excitation优化;“#Parameters”表示可训练参数的数量;“#Mult-Adds”表示每张图片multiply-add操作的数量;“Top-1/5 Acc.”表示在ImageNet验证集上排名第一或前五的精度;“CPU延迟”表示在Pixel1手机上批量大小为1的推断延迟。
如表1所示,与当前最优的MobileNetV2相比,我们的MnasNet模型在Pixel phone平台上,在同样的延迟下,将ImageNet top-1的准确率提高了2%。
此外,限制目标top-1准确率的条件下,我们的方法得到同样精度的速度比MobileNetV2快1.5倍,比NASNet快2.4倍。
结构搜索方法
多目标搜索方法通过在方程2中对α和β设置不同的值来设置硬性或软性延迟约束。下图展示了在典型α和β下多目标搜索的结果:
多目标搜索结果
其中,目标延迟(target latency)为T=80ms。上方图片展示了对1000个样本模型(绿色点)的柏拉图曲线(蓝色线);下方图片展示了模型延迟的直方图。
模型扩展的灵敏度
现实世界中,各式各样的应用程序有着许多不同的需求,并且移动设备也不是统一的,所以开发人员通常会做一些扩展性方面的工作。下图便展示了不同模型扩展技术的结果:
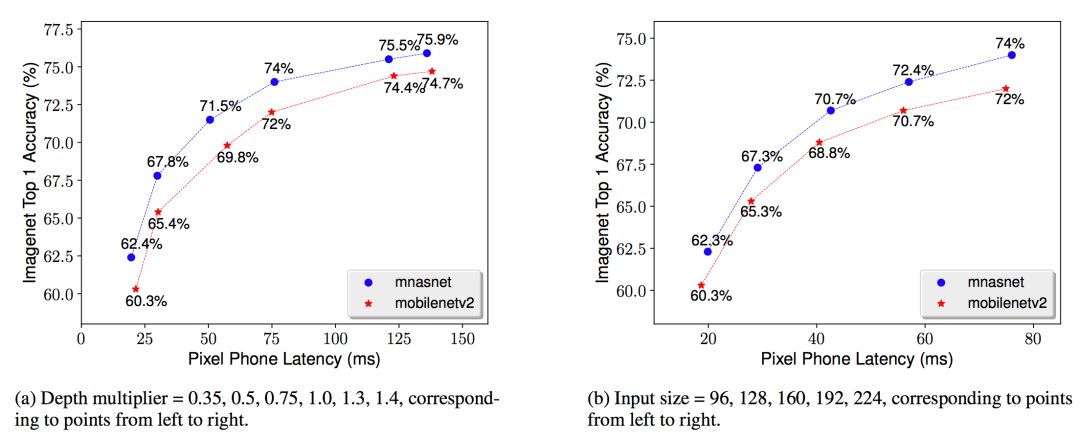
不同模型扩展技术的性能比较
MnasNet表1中的基准模型。将该基准模型与MobileNet V2的深度倍增器(depth multiplier)和输入保持一致。
除了模型扩展之外,本文提出的方法还能为任何新的资源约束搜索新的结构。例如,一些视频应用程序可能需要低至25ms的模型延迟。为了满足这些约束,可以使用更小的输入规模和深度倍增器来扩展一个基准模型,也可以搜索更适合这个新延迟约束的模型。图6就展示了上述两个方法的性能比较。
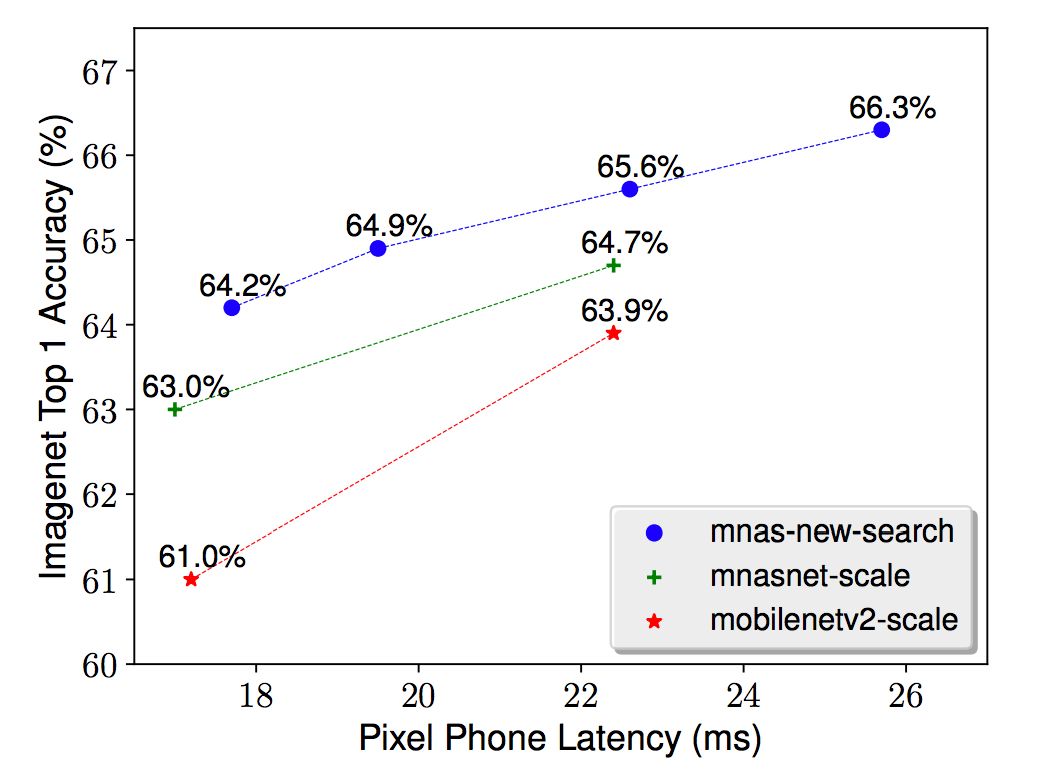
模型扩展 vs. 模型搜索
COCO目标检测性能
对于COCO目标检测,选择与表1相同的MnasNet模型作为SSDLite的特征提取器。根据其他研究人员的建议,只用本文提出的模型与其他SSD或YOLO探测器进行比较。表2展示了在COCO上MnasNet模型的性能。
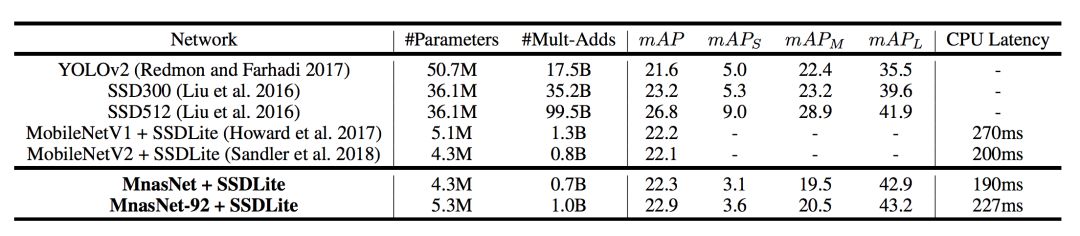
表2:在COCO上进行目标检测的性能结果
其中,“#Parameters”表示可训练参数的数量;“#Mult-Adds”表示每张图片multiply-add操作的数量;mAP表示在test-dev2017上的标准MAP值;mAPS、mAPM、mAPL表示在小型、中等、大型目标中的MAP值;“CPU延迟”表示在Pixel1手机上批量大小为1的推断延迟。
如表2所示,将我们的模型作为特征提取器插入SSD对象检测框架,在COCO数据集上我们的模型在推理延迟和mAP质量上都比MobileNetV1和MobileNetV2有提升,并且达到与 SSD300差不多的mAP质量时(22.9 vs 23.2)计算成本降低了35倍。
结论
本文提出了一种利用强化学习来设计mobile CNN模型的自动神经结构搜索方法。这种方法背后的关键想法是将platform-aware的真实的延迟信息集成到搜索过程中,并利用新的分解分层搜索空间来搜索移动模型,在准确性和延迟之间进行最佳的权衡。我们证明了这一方法可以比现有方法更好地自动地找到移动模型,并在典型的移动推理延迟约束下,在ImageNet图像分类和COCO对象检测任务上获得新的最优结果。由此产生的MnasNet架构还提供了一些有趣的发现,将指导我们设计下一代的mobile CNN模型。
-
神经网络
+关注
关注
42文章
4785浏览量
101280 -
数据集
+关注
关注
4文章
1210浏览量
24865 -
强化学习
+关注
关注
4文章
268浏览量
11312
发布评论请先 登录
相关推荐
深度强化学习实战
使用加权密集连接卷积网络的深度强化学习方法说明

机器学习中的无模型强化学习算法及研究综述

模型化深度强化学习应用研究综述






 工商网监
工商网监
评论