 利用人工智能定时方案简化高性能计算加速
利用人工智能定时方案简化高性能计算加速
云计算和人工智能(AI)将会是解决一些世界上最大的挑战的关键,如加速科学发现、加快医学研究、能源、医疗保健和其他行业创新步伐。数据科学家现在有能力利用人工智能和高性能计算(HPC)来分析海量数据,比以往更快地了解数据并解决问题。
随着对HPC需求的增加,数据中心正在越来越多地针对高性能计算工作进行优化。这反过来又刺激了对低延迟,高吞吐量数据处理和网络连接性进行优化的专用计算,网络和存储硬件的需求。这种市场趋势同样增加了对高性能定时解决方案的需求,以优化HPC工作负载加速器的运行。
服务器加速
硬件加速器用于加速数据中心应用中的HPC工作负载。虽然图形处理单元(GPU)历来被用于此目的,但现场可编程门阵列(FPGA)正日益成为另一种可行的选择。两种解决方案都能将并行处理、快速I / O和高速存储器接口结合起来,以扩展处理性能,使服务器能够高效地运行神经网络,为搜索引擎、语音识别、自然语言翻译和图像处理提供动力。 GPU和FPGA正在向更高速度的25 Gbps I / O接口转变,以便更轻松地扩展多个IC之间的协同处理。
如图1所示,这些高速I / O接口需要低抖动定时参考,以最大限度地降低误码率并提高整体系统性能。低抖动晶振(XOs)和时钟发生器非常适合GPU / FPGA I / O时钟。 Silicon Labs的Si510 XO和Si5332时钟发生器等高性能定时器件非常适合此应用,因为它们结合了低抖动参考定时,小尺寸和内置电源噪声抑制功能,最大限度地降低了开关电源对高速I / O性能的电源噪声的影响。
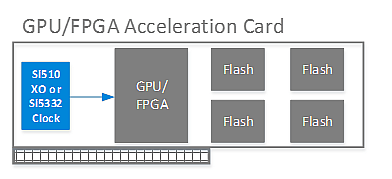
FPGA/GPU加速卡的参考定时
网络接口卡
网络接口卡(NIC)用于连接数据中心网络内的服务器和存储资源。随着对带宽需求的增加,数据中心正在从使用传统10GbE / 40GbE光纤网络转向使用更高速度的25GbE / 50GbE / 100GbE网络。这些网卡不仅需要协调大量数据的传输,还可以使用网卡将特定工作负载和应用程序从软件移动到硬件中,帮助数据中心更高效地运行。网卡将数据从PCIe传输到以太网,并为网络提供高速接口。诸如Silicon Labs的Si53204 PCIe缓冲器等定时器件可用于PCIe时钟分配,Si510 XO可用于为以太网MAC / PHY提供低抖动参考时钟。
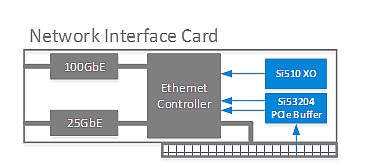
网络接口卡的参考定时
存储
在存储应用中,业界正在迅速从使用基于低速SATA(6 Gbps)和SAS(12 Gbps)CPU /内存互连解决方案的硬盘驱动器转向使用基于NVMExpress®接口规范的固态存储设备。 NVM Express(NVMe)的一个主要优点是可以缩短延迟时间并提高内存访问速度,使其成为闪存数据传输的理想解决方案。 NVMe的另一个好处是它使用流行的PCI Express(PCIe)串行接口将SSD与服务器/ CPU互连,后者已经支持用于高速串行数据传输的嵌入式PCIe接口。
如下图所示,SSD控制器需要一个高性能PCIe时钟发生器来提供参考定时。该时钟必须支持展频时钟生成,以减少EMI并确保符合辐射标准。此外,选择符合最新批准的PCIe Gen 4标准的面向未来的时钟源,并保持与PCIe Gen 1/2/3兼容至关重要。 Si52204缓冲器是展频时钟发生器的一个例子,符合PCIe Gen 1/2/3/4规范,并具有显著的余量。
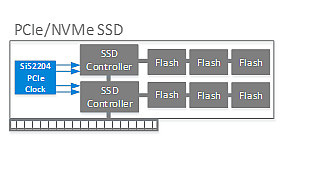
PCIe/NVMe SSD的定时
快速到达市场时间
数据中心硬件通常每两到三年更新一次。 HPC加速器和基于NVMe的SSD的主要优势在于,它们可以快速部署,以帮助数据中心运营商应对市场需求转变以及更快地推出新应用程序和Web服务。另一个好处是可扩展性。附加卡使用PCIe连接器插入标准服务器主板,立即为现有服务器提供扩展功能。附加卡的设计时间可以短至六个月,使数据中心操作员能够快速添加新功能并部署新的Web服务,而无需在数据中心内更换设备。
上市时间也是用于HPC加速器和基于NVMe的SSD的时钟器件的关键考虑因素。硬件设计人员应该考虑可编程定时解决方案,这些解决方案可以单独定制和优化以满足其特定的性能,功耗和空间要求。
高性能计算加速的未来
在过去几年中,定制硬件解决方案的重要性不断增加,以解决HPC和工作负载处理问题。随着新型GPU,FPGA和ASIC产品面市,这种趋势预计会加速,这些产品支持更低的延迟,更高的IO速度,更高容量的存储器接口以及更快的CPU,内存和加速器卡之间的数据传输。
最近,PCI-SIG工作组批准了PCIe Gen 4标准,该标准支持16 Gbps速率的CPU存储器I / O加速器互连。符合第四代标准的解决方案目前正在开发中,预计将于2019年开始大规模部署。此外,PCI-SIG刚刚启动了PCIe Gen 5的工作,这将支持32 Gbps速率的CPU内存I / O加速器互连。
不是静止不动,已经定义了三个竞争标准来为PCIe提供备用解决方案。这些新的总线/互连标准之一是CCIX(用于加速器的高速缓存一致互连)。 CCIX利用PCIe物理层,但将数据速率扩展到25 Gbps。它还指定处理器和加速器之间的高速缓存一致性。另一个竞争标准是OpenCAPI(相干加速器处理器接口)。
该扩展总线标准基于IBM Power9 BlueLink 25 Gbps I / O进行互连,并支持Nvidia的NVLink 2.0协议,以实现处理器之间的连贯存储器共享。第三个标准是Gen-Z,这是一种内存结构,使任何设备都能够与其他设备进行通信,就好像它正在与自己的本地内存进行通信一样,从而使应用程序能够直接访问任何类型的DRAM和NVM。
虽然很难预测哪些标准将在未来的CPU-内存-I / O互连中占上风,但一个趋势是明确的。未来的加速器互连技术将越来越依赖于高性能定时解决方案来优化高速I / O性能。未来的定时解决方案必须具有出色的抖动性能,以最大限度地降低系统级误码率。与标准兼容性和与FPGA / GPU供应商的经过验证的互操作性也将至关重要,从而可简化多种标准和设备之间的互操作性。由于不断增加的空间和功耗限制,未来的定时解决方案也必须高度集成,使单个组件能够提供所有board-level的定时。
-
FPGA
+关注
关注
1625文章
21664浏览量
601693 -
cpu
+关注
关注
68文章
10824浏览量
211105 -
云计算
+关注
关注
39文章
7730浏览量
137183 -
人工智能
+关注
关注
1791文章
46838浏览量
237485
原文标题:【技术干货】创新的定时方案简化高性能计算加速
文章出处:【微信号:SiliconLabs,微信公众号:Silicon Labs】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得
Samtec AI 应用详述 | 人工智能加速器所需的连接器

risc-v在人工智能图像处理应用前景分析
人工智能ai4s试读申请
报名开启!深圳(国际)通用人工智能大会将启幕,国内外大咖齐聚话AI
利用人工智能改变 PCB 设计







 工商网监
工商网监
评论