 解决自动驾驶的三个核心问题
解决自动驾驶的三个核心问题
用4级或5级来定义自动驾驶很难有一个明确的标准,自动驾驶也不应该搞得很复杂。自动驾驶实际包含三个问题:一是我在哪?二是我要去哪?三是如何去?能完整解决这三个问题就是真正的自动驾驶。所以特斯拉升级后的8000美元的Autopilot 2.0只有部分线控功能,不能算真正的自动驾驶。福特、百度和谷歌这些公司做的才是真正的自动驾驶,远在特斯拉之上,两者云泥之差,天壤之别。
第一个问题是定位,自动驾驶需要的是厘米级定位。
第二个问题是路径规划,自动驾驶的路径规划第一层是点到点的非时间相关性拓扑路径规划;第二层是实时的毫秒级避障规划;第三层是将规划分解为纵向(加速度)和横向(角速度)规划。
第三个问题是车辆执行机构执行纵向和横向规划,也就是线控系统。
目前自动驾驶的技术基本上都源自机器人,自动驾驶可以看做是轮式机器人加一个舒适的沙发。机器人系统中定位和路径规划是一个问题,没有定位,就无法规划路径。厘米级实时定位是目前自动驾驶最大的挑战之一。
对机器人系统来说,定位主要靠SLAM与先验地图(Prior Map)的交叉对比。SLAM是Simultaneous Localization and Mapping的缩写,意为“同时定位与建图”。它是指运动物体根据传感器的信息,一边计算自身位置,一边构建环境地图的过程。
目前,SLAM的应用领域主要有机器人、虚拟现实和增强现实。其用途包括传感器自身的定位,以及后续的路径规划、场景理解。
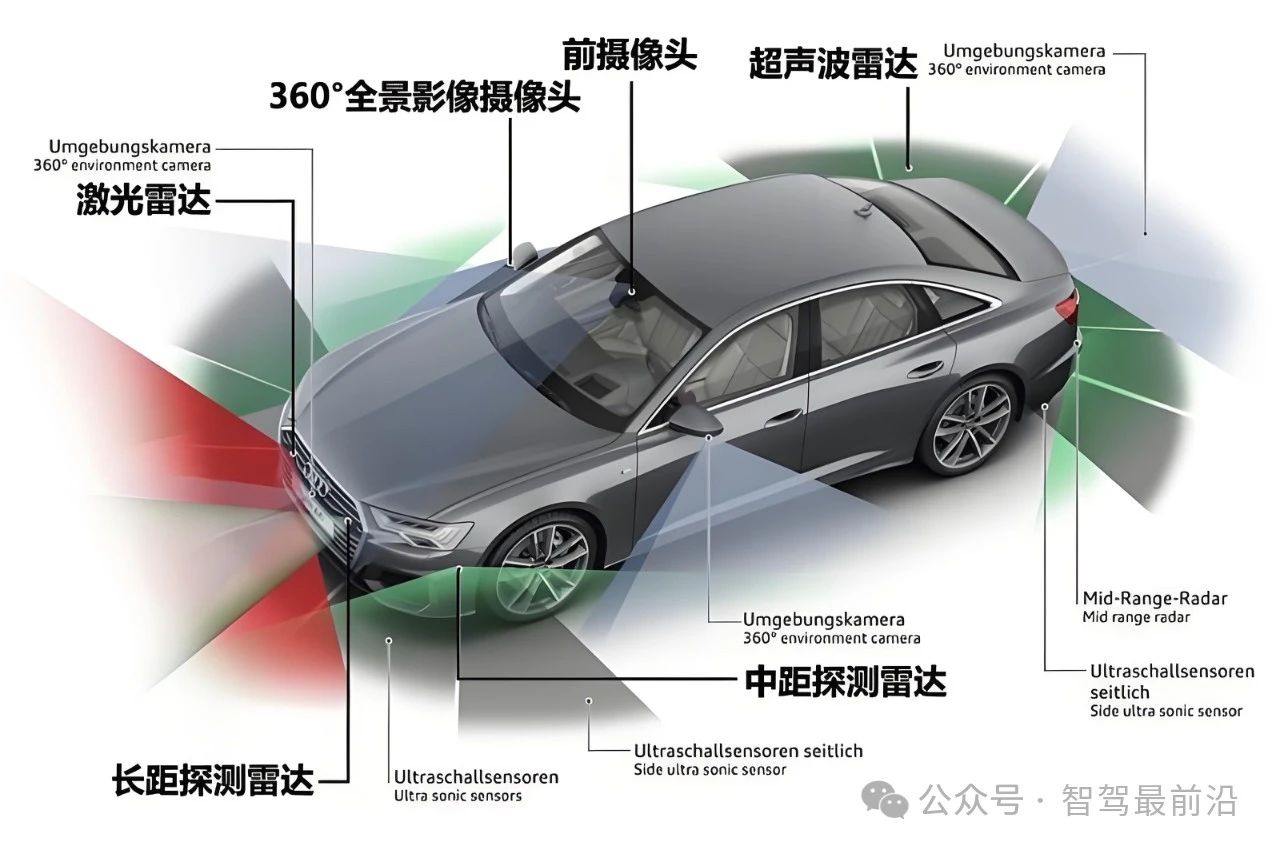
随着传感器种类和安装方式的不同,SLAM的实现方式和难度会有很大差异。按传感器来分,SLAM主要分为激光、视觉两大类。其中,激光SLAM研究较早,理论和工程均比较成熟。视觉方案目前(2016)尚处于实验室研究阶段, 应用于室内且低速的商业化产品都没用出现,更何况远比室内室内复杂的高速运动室外环境。单从这点来说,激光雷达是自动驾驶必备的传感器。
SLAM研究自1988年提出以来,已经过了近三十年。早期SLAM研究侧重于使用滤波器理论。21世纪之后,学者们开始借鉴SfM(Structure from Motion)中的方式,以优化理论为基础求解SLAM问题。这种方式取得了一定的成就,并且在视觉SLAM领域中取得了主导地位。 人们有时候会混淆SLAM和视觉里程计的概念。应该说,视觉里程计是视觉SLAM的一个模块,其目的在于增量式地估计相机运动。然而,完整的SLAM还包括添加回环检测和全局优化,以获得精确的、全局一致的地图。
目前开源的视觉传感器SLAM算法主要分三大类,稀疏法,又称特征点法。稠密法,主要是RGB-D。半稠密法,单目和双目用的多,是目前最火热的领域。激光SLAM主要方法有Hector、Gmapping、Tiny。
机器人定位常见三大类,相对定位,绝对定位和组合定位。自动驾驶一般用组合定位,首先本体感受传感器如里程计(Odometry)、陀螺仪(Gyroscopes)等,通过给定初始位姿,来测量相对于机器人初始位姿的距离和方向来确定当前机器人的位姿,也叫做航迹推测。然后用激光雷达或视觉感知环境,用主动或被动标识、地图匹配、GPS、或导航信标进行定位。位置的计算方法包括有三角测量法、三边测量法和模型匹配算法等。从这个角度而言,IMU也是自动驾驶必备的部件。
同时,机器人的自主定位实际上是个概率问题,因此机器人定位算法也出现两大流派,一类是卡尔曼滤波器,一类是贝叶斯推理。卡尔曼滤波器有Extended Kalman Filter(EKF),Kalman Filter (KF),Unscented Kalman Filter (UKF)定位方法。另一类是基于贝叶斯推理的定位方法。运用栅格和粒子来描述机器人位置空间,并递推计算在状态空间上的概率分布,比如Markov Localization (MKV),Monte Carlo Localization (MCL)定位方法。
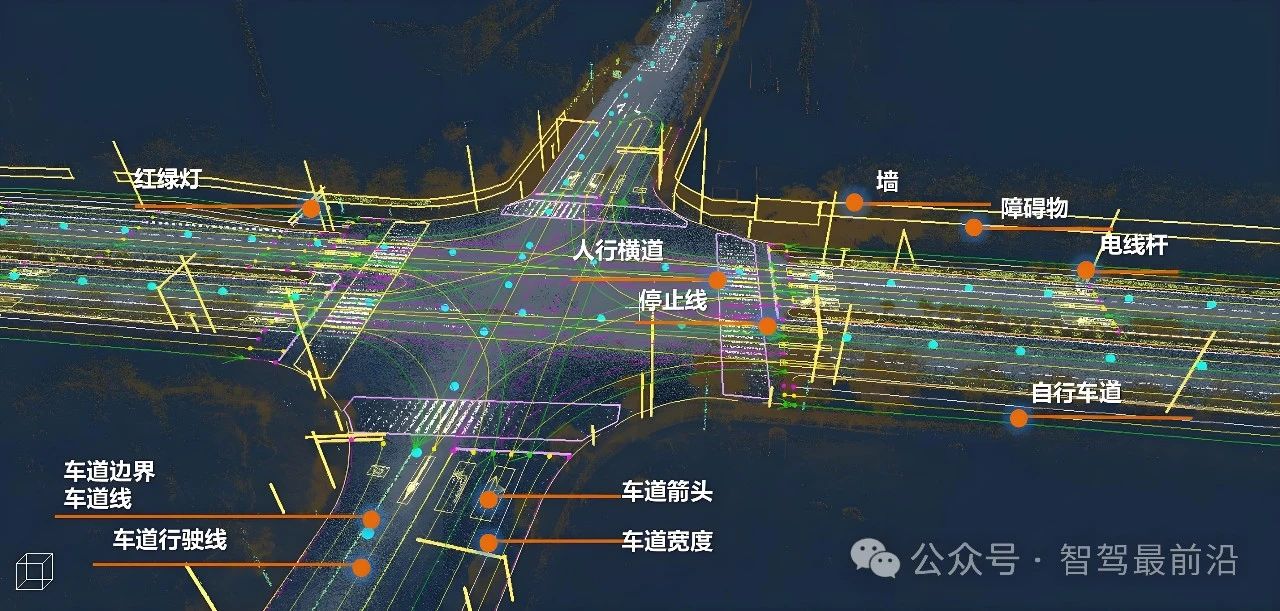
在地图匹配上,必须有一幅Prior Map与之对比。这幅地图不一定是厘米级高精度地图。这就需要说说地图了,地图可以分为四大类,分别是Metric、Topologic、Sensor、Semantic。我们最常见的地图是语义级地图,无人驾驶不是导弹,一般输入目的地应该是语义级的,毕竟人类的交通模式还是语义级的,而非地理坐标。这也是机器人和无人驾驶的区别之一,机器人一般不考虑语义级意义,它只需要知道自己在坐标体系中的位置。
GPS提供的则是全球坐标系的Metric。将来的V2X会提供也会提供一幅雷达和视觉探测距离之外(NLOS)的特定物体(移动的行人和车)的地图,或者可以叫V2X地图。目前国内研究阶段的无人车大都是用GPS RTK定位,GPS RTK必须配合厘米级高精度地图才能得到语义信息,所以是不可能真正无人驾驶的。
目前定位的方法主要由五种,一是用激光雷达的SLAM,二是用激光雷达的强度扫描图像,三是用合成图像,四是用高斯混合地图,最后一种是Mobileye提出的REM。
第一种,激光雷达的SLAM,利用车辆自带的GPS和IMU做出大概位置判断,然后用预先准备好的高精度地图(Prior Map)与激光雷达SLAM云点图像与之对比,或者说Registration,放在一个坐标系内做配准。配对(Matching)成功后确认自车位置。这是目前最成熟,准确度最高的方法。
激光雷达的SLAM
第二种,利用激光雷达的强度扫描图像。激光雷达有两种最基本的成像方式,一是3D距离成像,可以近似地理解为点云;二是强度扫描成像,激光经物体反射,根据反射强度值的不同,可以得到一副强度成像图像。强度值是包括在点云里的,光强分离核心技术之一。这种定位方法需要预先制作一个特殊的SLAM系统,称之为位姿图像SLAM(Pose-GraphSLAM),勉强可看作激光雷达制造的高清地图。
有三个约束因素(Constraints),一是扫描匹配约束(Z),二是里程计约束(Odometry Constraints,U),GPS先验约束(PriorConstraints)。激光雷达的3D云点地图抽出强度值和真实地面(Ground Plane),转化为2D的地面强度扫描图像。与位姿图像SLAM配对后即可定位。
第三种也有称之为图像增强型定位,通常是将Lidar和视觉系统结合进行定位,用单目即可。这种方法需要预先准备一幅激光雷达制造的3D地图,用Ground-Plane Sufficient得到一个2D的纯地面模型地图,用OpenGL将单目视觉图像与这个2D的纯地面模型地图经过坐标变换, 用归一化互信息(normalized mutual information)配准。然后用扩展卡尔曼滤波器(EKF)来实现定位。
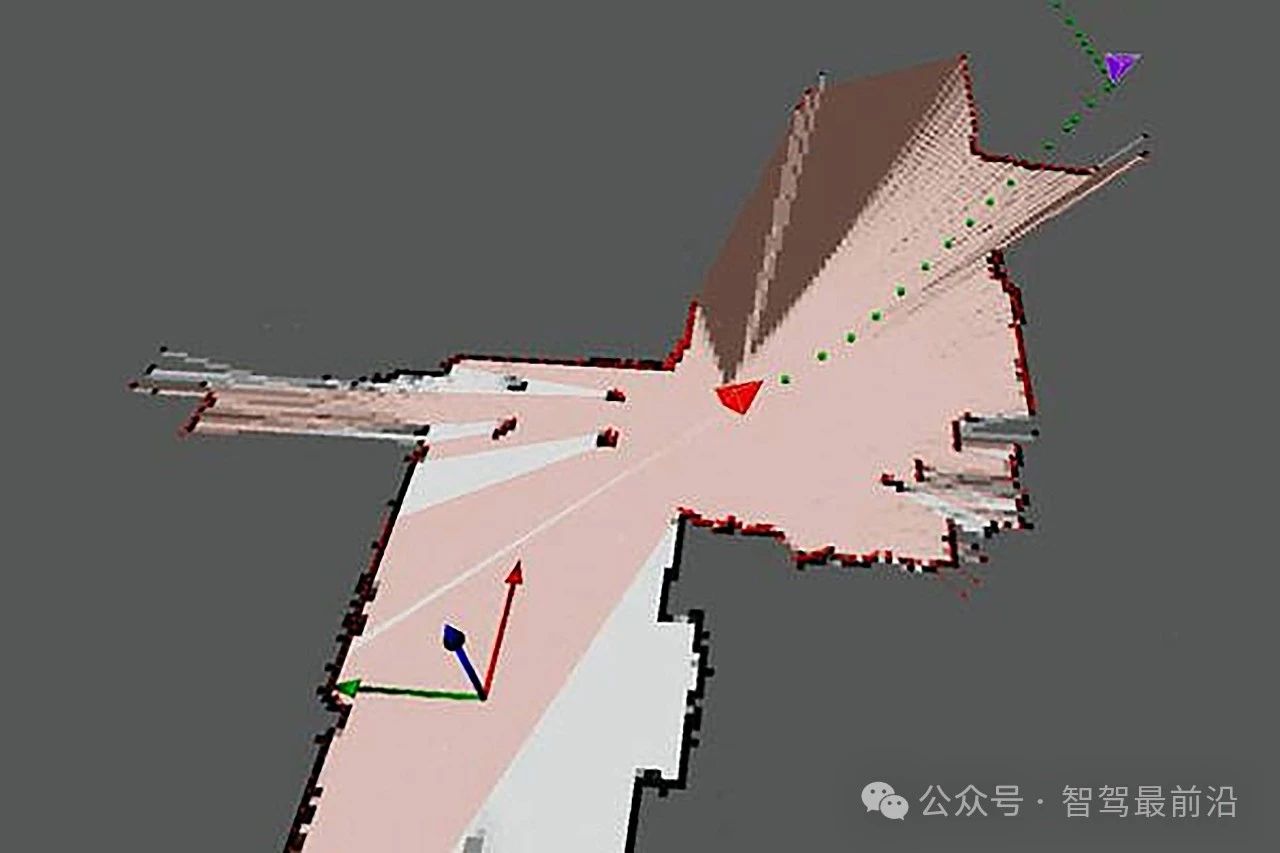
第四种是高斯混合模型,这实际还是第二种方法的补充,在遇到恶劣环境,比如很厚的积雪,雪后还有残雪的泥泞的道路,缺乏纹理的老旧的被破坏的道路,用高斯混合模型来做定位,提高激光雷达定位的鲁棒性。
高斯混合模型
前面四种都离不开激光雷达,成本颇高,但是室内VSLAM又未达到实用地步,更不要说室外定位了。因此Mobileye提出一种无需SLAM的定位方法。这就是REM。虽然REM不用视觉SLAM,但显然只是视觉SLAM的变种而已,Mobileye 通过采集包括交通信号、方向指示牌、长方形指示牌、路灯及反光标等「地标」,得到一个简单的 3D 坐标数据;再通过识别车道线信息,路沿,隔离带等获取丰富的 1D 数据。把简单的 3D 数据和丰富的 1D 的数据加起来,大小也不过是 10Kb/km,摄像头的图像与这种REM地图中匹配即可定位。Mobileye这种设计毫无疑问是成本最低的,但前提是至少有上千万辆车配备REM系统,能够自动搜集数据并上传到云端,有些路段或者说非道路地区,没有装载REM系统的车走过,就无法定位。在全球范围内让装载REM系统的车走遍每一寸土地是不可能的。这可能牵涉到隐私问题,也牵涉到数据版权问题,这些数据的版权究竟归谁,是车主还是车企还是云端的服务商,还是Mobileye?这问题很难说清。同时REM的数据要及时更新,几乎要做到准实时状态,同时光线对数据影响明显,REM要滤除那些不合适的数据,所以维持这份地图的有效性需要非常庞大的数据量和运算量,谁来维护这个庞大的运算体系?还有最致命的一点,REM是基于视觉的,只能在天气晴好,光线变化幅度小的情况下使用,这大大限制了其实用范围,而激光雷达可满足95%的路况。
厘米级定位是无人驾驶的难点之一,不光是车辆本身的语义级定位,还有一个绝对坐标定位,目前GPS定位,城区的最高精度大约10米,郊区大约5米。GPS RTK只能在小范围应用,覆盖面有限,系统带宽更有限,跑几辆车凑合,上百辆系统可能就崩溃了。北斗地基系统主要做军用,系统带宽和刷新频率有限,无法做大规模商用和车用。日本的准天顶卫星只能覆盖中国东部少数地区,并且也不是长久之计。
当然,将来无人车的定位很难摆脱厘米级地图,但是这只是车辆启动前的第一次定位,车辆启动后,利用车载激光雷达的SLAM和障碍物识别完全可以取代高精度地图做自主导航。所以未来,高精度地图的主要作用是定位而非导航,也无需车载,放在云端即可。
-
谷歌
+关注
关注
27文章
6210浏览量
106237 -
百度
+关注
关注
9文章
2302浏览量
90899 -
自动驾驶
+关注
关注
785文章
13966浏览量
167343
原文标题:自动驾驶的核心技术是什么?
文章出处:【微信号:Imgtec,微信公众号:Imagination Tech】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
从《自动驾驶地图数据规范》聊高精地图在自动驾驶中的重要性
自动驾驶中常提的鲁棒性是个啥?
自动驾驶中常提的SLAM到底是个啥?
MEMS技术在自动驾驶汽车中的应用
自动驾驶汽车安全吗?

智能驾驶与自动驾驶的关系









 工商网监
工商网监
评论