 DMA控制器硬件结构与DMA通道使用的地址
DMA控制器硬件结构与DMA通道使用的地址
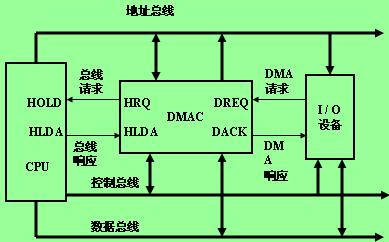
DMA是一种无需CPU的参与就可以让外设和系统内存之间进行双向数据传输的硬件机制。使用DMA可以使系统CPU从实际的I/O数据传输过程中摆脱出来,从而大大提高系统的吞吐率。DMA经常与硬件体系结构特别是外设的总线技术密切相关。
一、DMA控制器硬件结构
DMA允许外围设备和主内存之间直接传输 I/O 数据, DMA 依赖于系统。每一种体系结构DMA传输不同,编程接口也不同。
数据传输可以以两种方式触发:一种软件请求数据,另一种由硬件异步传输。
a --软件请求数据
调用的步骤可以概括如下(以read为例):
(1)在进程调用 read 时,驱动程序的方法分配一个 DMA 缓冲区,随后指示硬件传送它的数据。进程进入睡眠。(2)硬件将数据写入 DMA 缓冲区并在完成时产生一个中断。
(3)中断处理程序获得输入数据,应答中断,最后唤醒进程,该进程现在可以读取数据了。
b --由硬件异步传输
在 DMA 被异步使用时发生的。以数据采集设备为例:
(1)硬件发出中断来通知新的数据已经到达。(2)中断处理程序分配一个DMA缓冲区。(3)外围设备将数据写入缓冲区,然后在完成时发出另一个中断。(4)处理程序利用DMA分发新的数据,唤醒任何相关进程。
网卡传输也是如此,网卡有一个循环缓冲区(通常叫做 DMA 环形缓冲区)建立在与处理器共享的内存中。每一个输入数据包被放置在环形缓冲区中下一个可用缓冲区,并且发出中断。然后驱动程序将网络数据包传给内核的其它部分处理,并在环形缓冲区中放置一个新的 DMA 缓冲区。
驱动程序在初始化时分配DMA缓冲区,并使用它们直到停止运行。
二、DMA通道使用的地址
DMA通道用dma_chan结构数组表示,这个结构在kernel/dma.c中,列出如下:
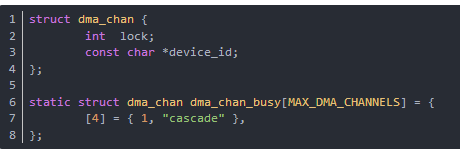
如果dma_chan_busy[n].lock != 0表示忙,DMA0保留为DRAM更新用,DMA4用作级联。DMA 缓冲区的主要问题是,当它大于一页时,它必须占据物理内存中的连续页。
由于DMA需要连续的内存,因而在引导时分配内存或者为缓冲区保留物理 RAM 的顶部。在引导时给内核传递一个"mem="参数可以保留 RAM 的顶部。例如,如果系统有 32MB 内存,参数"mem=31M"阻止内核使用最顶部的一兆字节。稍后,模块可以使用下面的代码来访问这些保留的内存:
dmabuf = ioremap( 0x1F00000 /* 31M */, 0x100000 /* 1M */);
分配 DMA 空间的方法,代码调用kmalloc(GFP_ATOMIC)直到失败为止,然后它等待内核释放若干页面,接下来再一次进行分配。最终会发现由连续页面组成的DMA 缓冲区的出现。
一个使用 DMA 的设备驱动程序通常会与连接到接口总线上的硬件通讯,这些硬件使用物理地址,而程序代码使用虚拟地址。基于 DMA 的硬件使用总线地址而不是物理地址,有时,接口总线是通过将 I/O 地址映射到不同物理地址的桥接电路连接的。甚至某些系统有一个页面映射方案,能够使任意页面在外围总线上表现为连续的。
当驱动程序需要向一个 I/O 设备(例如扩展板或者DMA控制器)发送地址信息时,必须使用 virt_to_bus 转换,在接受到来自连接到总线上硬件的地址信息时,必须使用 bus_to_virt 了。
三、DMA操作函数
写一个DMA驱动的主要工作包括:DMA通道申请、DMA中断申请、控制寄存器设置、挂入DMA等待队列、清除DMA中断、释放DMA通道
因为 DMA 控制器是一个系统级的资源,所以内核协助处理这一资源。内核使用DMA 注册表为 DMA 通道提供了请求/释放机制,并且提供了一组函数在 DMA 控制器中配置通道信息。
以下具体分析关键函数(linux/arch/arm/mach-s3c2410/dma.c)

四、DMA映射
一个DMA映射就是分配一个 DMA 缓冲区并为该缓冲区生成一个能够被设备访问的地址的组合操作。一般情况下,简单地调用函数virt_to_bus 就设备总线上的地址,但有些硬件映射寄存器也被设置在总线硬件中。映射寄存器(mapping register)是一个类似于外围设备的虚拟内存等价物。在使用这些寄存器的系统上,外围设备有一个相对较小的、专用的地址区段,可以在此区段执行 DMA。通过映射寄存器,这些地址被重映射到系统 RAM。映射寄存器具有一些好的特性,包括使分散的页面在设备地址空间看起来是连续的。但不是所有的体系结构都有映射寄存器,特别地,PC 平台没有映射寄存器。
在某些情况下,为设备设置有用的地址也意味着需要构造一个反弹(bounce)缓冲区。例如,当驱动程序试图在一个不能被外围设备访问的地址(一个高端内存地址)上执行 DMA 时,反弹缓冲区被创建。然后,按照需要,数据被复制到反弹缓冲区,或者从反弹缓冲区复制。
根据 DMA 缓冲区期望保留的时间长短,PCI 代码区分两种类型的 DMA 映射:
a -- 一致 DMA 映射
它们存在于驱动程序的生命周期内。一个被一致映射的缓冲区必须同时可被 CPU 和外围设备访问,这个缓冲区被处理器写时,可立即被设备读取而没有cache效应,反之亦然,使用函数pci_alloc_consistent建立一致映射。
b -- 流式 DMA映射
流式DMA映射是为单个操作进行的设置。它映射处理器虚拟空间的一块地址,以致它能被设备访问。应尽可能使用流式映射,而不是一致映射。这是因为在支持一致映射的系统上,每个 DMA 映射会使用总线上一个或多个映射寄存器。具有较长生命周期的一致映射,会独占这些寄存器很长时间――即使它们没有被使用。使用函数dma_map_single建立流式映射。
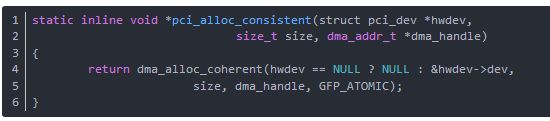
1、建立一致 DMA 映射
函数pci_alloc_consistent处理缓冲区的分配和映射,函数分析如下(在include/asm-generic/pci-dma-compat.h中):
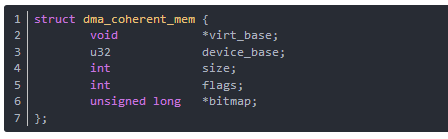
结构dma_coherent_mem定义了DMA一致性映射的内存的地址、大小和标识等。结构dma_coherent_mem列出如下(在arch/i386/kernel/pci-dma.c中):
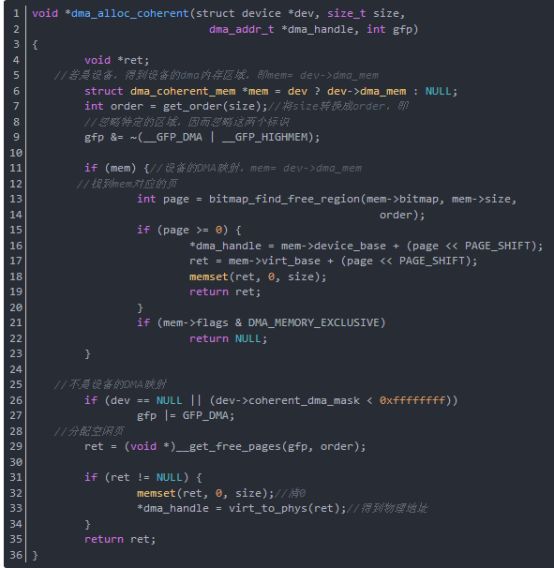
函数dma_alloc_coherent分配size字节的区域的一致内存,得到的dma_handle是指向分配的区域的地址指针,这个地址作为区域的物理基地址。dma_handle是与总线一样的位宽的无符号整数。 函数dma_alloc_coherent分析如下(在arch/i386/kernel/pci-dma.c中):
当不再需要缓冲区时(通常在模块卸载时),应该调用函数 pci_free_consitent 将它返还给系统。
2、建立流式 DMA 映射
在流式 DMA 映射的操作中,缓冲区传送方向应匹配于映射时给定的方向值。缓冲区被映射后,它就属于设备而不再属于处理器了。在缓冲区调用函数pci_unmap_single撤销映射之前,驱动程序不应该触及其内容。
在缓冲区为 DMA 映射时,内核必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新。在刷新之后,由处理器写入缓冲区的数据对设备来说也许是不可见的。
如果欲映射的缓冲区位于设备不能访问的内存区段时,某些体系结构仅仅会操作失败,而其它的体系结构会创建一个反弹缓冲区。反弹缓冲区是被设备访问的独立内存区域,反弹缓冲区复制原始缓冲区的内容。
函数pci_map_single映射单个用于传送的缓冲区,返回值是可以传递给设备的总线地址,如果出错的话就为 NULL。一旦传送完成,应该使用函数pci_unmap_single 删除映射。其中,参数direction为传输的方向,取值如下:
PCI_DMA_TODEVICE 数据被发送到设备。PCI_DMA_FROMDEVICE如果数据将发送到 CPU。PCI_DMA_BIDIRECTIONAL数据进行两个方向的移动。PCI_DMA_NONE 这个符号只是为帮助调试而提供。
函数pci_map_single分析如下(在arch/i386/kernel/pci-dma.c中)
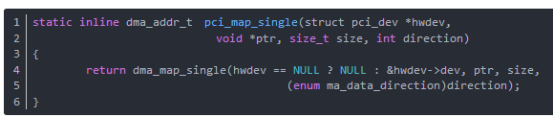
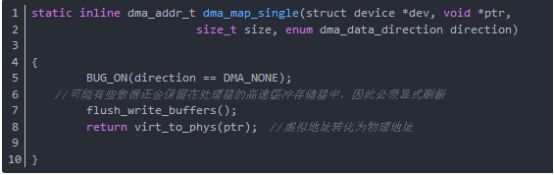
函数dma_map_single映射一块处理器虚拟内存,这块虚拟内存能被设备访问,返回内存的物理地址,函数dma_map_single分析如下(在include/asm-i386/dma-mapping.h中):
3、分散/集中映射
分散/集中映射是流式 DMA 映射的一个特例。它将几个缓冲区集中到一起进行一次映射,并在一个 DMA 操作中传送所有数据。这些分散的缓冲区由分散表结构scatterlist来描述,多个分散的缓冲区的分散表结构组成缓冲区的struct scatterlist数组。
分散表结构列出如下(在include/asm-i386/scatterlist.h):
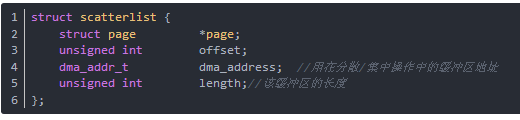
每一个缓冲区的地址和长度会被存储在 struct scatterlist 项中,但在不同的体系结构中它们在结构中的位置是不同的。下面的两个宏定义来解决平台移植性问题,这些宏定义应该在一个pci_map_sg被调用后使用:
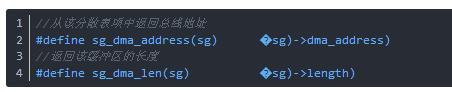
函数pci_map_sg完成分散/集中映射,其返回值是要传送的 DMA 缓冲区数;它可能会小于 nents(也就是传入的分散表项的数量),因为可能有的缓冲区地址上是相邻的。一旦传输完成,分散/集中映射通过调用函数pci_unmap_sg 来撤销映射。 函数pci_map_sg分析如下(在include/asm-generic/pci-dma-compat.h中):
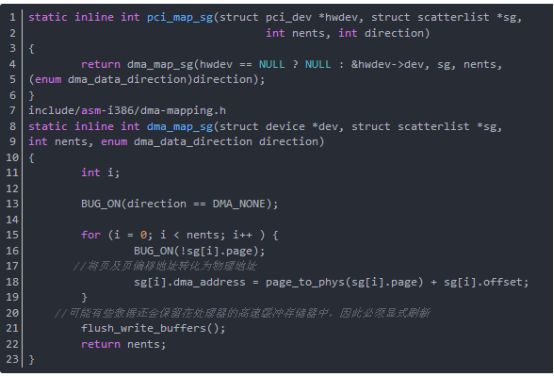
五、DMA池
许多驱动程序需要又多又小的一致映射内存区域给DMA描述子或I/O缓存buffer,这使用DMA池比用dma_alloc_coherent分配的一页或多页内存区域好,DMA池用函数dma_pool_create创建,用函数dma_pool_alloc从DMA池中分配一块一致内存,用函数dmp_pool_free放内存回到DMA池中,使用函数dma_pool_destory释放DMA池的资源。
结构dma_pool是DMA池描述结构,列出如下:
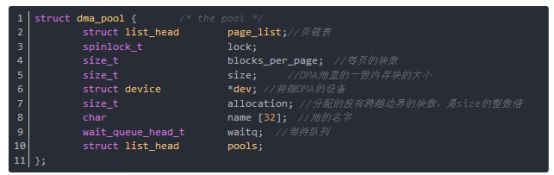
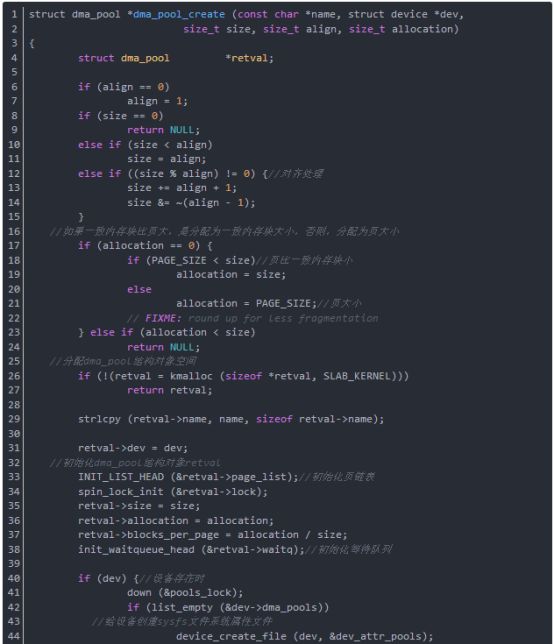
函数dma_pool_create给DMA创建一个一致内存块池,其参数name是DMA池的名字,用于诊断用,参数dev是将做DMA的设备,参数size是DMA池里的块的大小,参数align是块的对齐要求,是2的幂,参数allocation返回没有跨越边界的块数(或0)。
函数dma_pool_create返回创建的带有要求字符串的DMA池,若创建失败返回null。对被给的DMA池,函数dma_pool_alloc被用来分配内存,这些内存都是一致DMA映射,可被设备访问,且没有使用缓存刷新机制,因为对齐原因,分配的块的实际尺寸比请求的大。如果分配非0的内存,从函数dma_pool_alloc返回的对象将不跨越size边界(如不跨越4K字节边界)。这对在个体的DMA传输上有地址限制的设备来说是有利的。
函数dma_pool_create分析如下(在drivers/base/dmapool.c中):
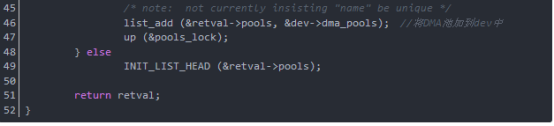
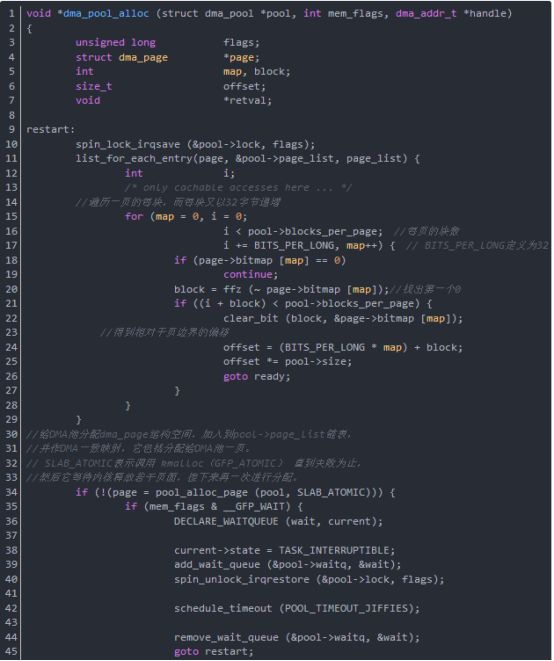
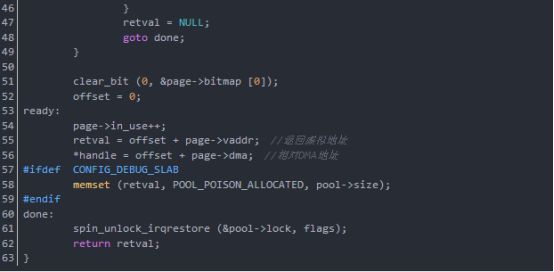
函数dma_pool_alloc从DMA池中分配一块一致内存,其参数pool是将产生块的DMA池,参数mem_flags是GFP_*位掩码,参数handle是指向块的DMA地址,函数dma_pool_alloc返回当前没用的块的内核虚拟地址,并通过handle给出它的DMA地址,如果内存块不能被分配,返回null。
函数dma_pool_alloc包裹了dma_alloc_coherent页分配器,这样小块更容易被总线的主控制器使用。这可能共享slab分配器的内容。
函数dma_pool_alloc分析如下(在drivers/base/dmapool.c中):
六、一个简单的使用DMA 例子
示例:下面是一个简单的使用DMA进行传输的驱动程序,它是一个假想的设备,只列出DMA相关的部分来说明驱动程序中如何使用DMA的。
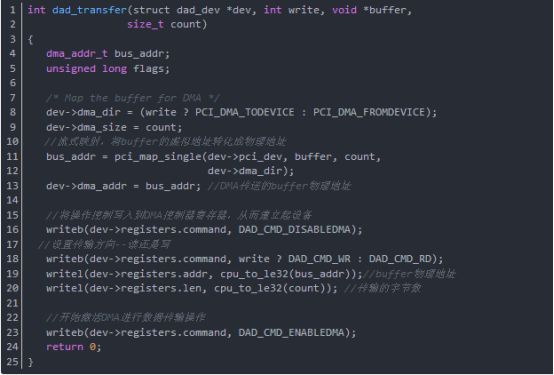
函数dad_transfer是设置DMA对内存buffer的传输操作函数,它使用流式映射将buffer的虚拟地址转换到物理地址,设置好DMA控制器,然后开始传输数据。
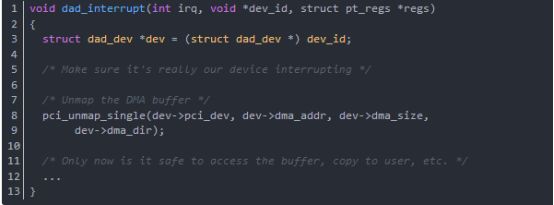
函数dad_interrupt是中断处理函数,当DMA传输完时,调用这个中断函数来取消buffer上的DMA映射,从而让内核程序可以访问这个buffer。
函数dad_open打开设备,此时应申请中断号及DMA通道
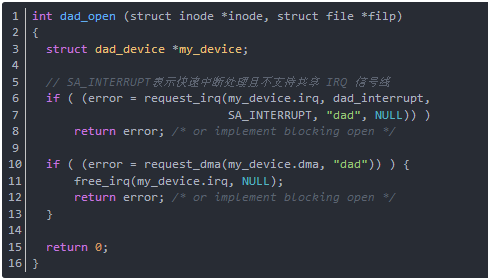
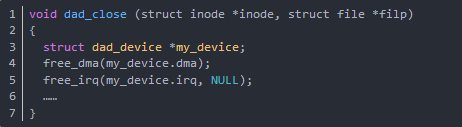
在与open 相对应的 close 函数中应该释放DMA及中断号。
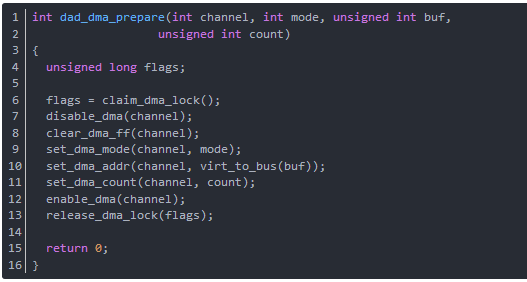
函数dad_dma_prepare初始化DMA控制器,设置DMA控制器的寄存器的值,为 DMA 传输作准备。
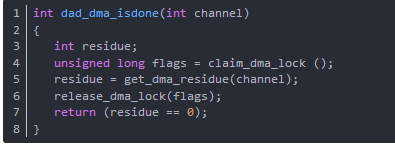
函数dad_dma_isdone用来检查 DMA 传输是否成功结束。
-
控制器
+关注
关注
113文章
16580浏览量
180464 -
寄存器
+关注
关注
31文章
5392浏览量
121930 -
dma
+关注
关注
3文章
568浏览量
101497
原文标题:关于嵌入式Linux下的DMA技术,你需要知道的都在这里了
文章出处:【微信号:gh_c472c2199c88,微信公众号:嵌入式微处理器】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
ZYNQ开发案例之DMA控制器系统设计
DMA与DMA控制器
基于DMA控制器的UART串行通信设计

LED显示系统DMA控制器的设计
实时图像处理系统的DMA控制器设计
dma控制器芯片8257资料介绍
dma控制器由什么组成
基于SystemC的可配置多通道DMA控制器的设计
dma控制器的组成
MCU学习笔记_DMA原理

基于STM32F407的DMA解析-ADC单通道DMA读取数据

Xilinx高性能PCIe DMA控制器IP,8个DMA通道





 工商网监
工商网监
评论