 以骁龙845为例 比较X86与ARM真正的区别
以骁龙845为例 比较X86与ARM真正的区别
高通马上要推晓龙855,华为也要推出麒麟980处理器了,通过媒体的泛滥宣扬,感觉到现在手机端的处理器真是越来越强大了,有很多人应该都有疑问,如此强大的ARM架构的移动处理器现在到底相当于x86的哪个级别的处理器?
带着疑问,我们找到了几个知乎大神的解答,推送给大家。以晓龙845为例,主要通过理论分析的方法来做出比较。
虽然是以骁龙845来做比较,但我认为要比的应该是CPU,最多再带个GPU的对比,至于845相当于Intel哪个处理器,无非就是要跨平台对比一下,但是问题在于尽管性能可以使用标准C/C++规范编写相应的通用计算项目来计算(比如geekbench,比如SPEC),但是由于他们往往运行在不同的平台,所以对于他们的差异民间一直都有各种说法,通过个人体验,模拟器,游戏画面来衡量的说法层出不穷,但实际上,如果只是理论比较,其实已经没有太大难度。
很多人说很难看到结论,所以我把结论放在前面,A75的845在大的架构设计规模上更接近Nehalem,比如ROB条目128,后端执行单元Intel有大量复用端口的计算单元,执行单元规模相比A75互有高低,但A75复用的程度低,某些情况效率更高,向量计算能力也接近SSE4的Nehalem,也就是一代酷睿i系列,在很多细节上有一定改进,某些方面能接近Sandy bridge,所以理论上能达到同频率的一代酷睿i或者二代酷睿i系列之间的性能,相比同样是三发射的apollolake和Gemini Lake,A75的ROB和后端执行单元也稍有优势,但是某些方面较差,比如APL和Gemini lake都有3个ALU,A75只有2个,所以严格地说A75也是Gemini Lake左右的架构产品。
X86与ARM真的区别很大吗?
如果你问他们的出身,那他们的确有很大区别,很多人会说CISC或者RISC的区别,但事实上X86历经40年,ARM已经30多年了,如果会傻到不吸取对方优秀的特性,那他们早就被淘汰了,如今X86和ARM在架构和执行单元层面已经有大量相似之处,排除内存模型一个还在用TSO-Modle,一个用weak-modle外,ARM和X86已经高度接近,IntelCPU从486开始就已经有了RISC的影子,从奔腾开始一个新的复杂译码逻辑电路开始加入到CPU前端,它会将CISC指令翻译为RISC风格的指令,这被称为μop,之后处理器的前后端就会按一个乱序RISC处理器一样执行,同样ARM处理器也在A9开始拥有了乱序超标量流水线,A8开始有了NEON向量指令集,如今ARM处理器也有了共享式的三级缓存,所以,纠结ARM和X86是精简还是复杂意义不大,归根结底还是架构设计到底多大规模,执行一些使用标准C/C++语句编译出来的benchmark 表现出来的性能说话。
A75与Intel哪个架构最接近
A75简单的一个架构流水线框图,前端解码宽度为3,dispatch总计高达9μops(6个标量,3个向量),实际乱序重排窗口(ROB)条目数和A72/73一样,都是128,后端EU 8个,三个向量EU,2个int标量EU和2个内存子系统EU(Load/store)以及一个双倍的分支跳转单元,其中两个NEON FP单元(其实应该是执行计算的单元,不仅仅是浮点)实现1X128 MUL+1X128 ADD,或1X128 FMA。
那Intel这边的架构呢,Intel架构近年演进大致如下
从架构层面来说nehalem/sandy bridge/haswell/Skylake是新架构,这些架构有明显的改变,我们先来看Skylake,目前Intel最先进的架构
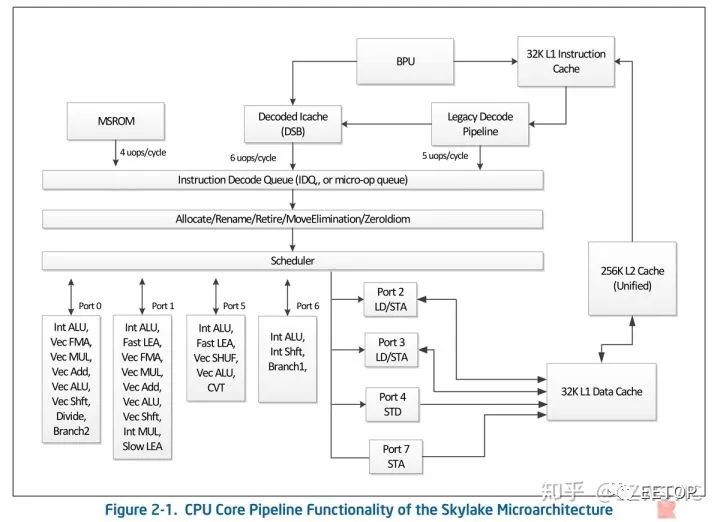
前端解码宽度为5(4简单1复杂),但由于实际执行和分发单元的限制,SKL依旧是4发射处理器,乱序重排缓冲区高达224条目,后端与A75一样,8个EU端口,但是每个端口挂的计算单元就很多了,比如A75分开挂载的NEON向量单元和标量int单元,在Intel这端口0,1,5具备同时有向量和标量单元的特点,同时,Intel SKL的内存子系统端口2.3.4.7,2个可以实现L/S,另外两个分别实现STD(store data)和STA(store address),显示Intel处理器同时会拥有较好的内存性能,同时向量和标量单元大量复用同一个端口,表现Intel认为这样能做到最大化的后端利用率,这一点与之相反的是9810拥有12个后端EU
这样看来,A75是比不过SKL的,实际上,即使是GB4上,单核2.8Ghz的A75也就2400分,而SKL 3.2Ghz就能做到4000分。
那接下来我们再看Haswell,
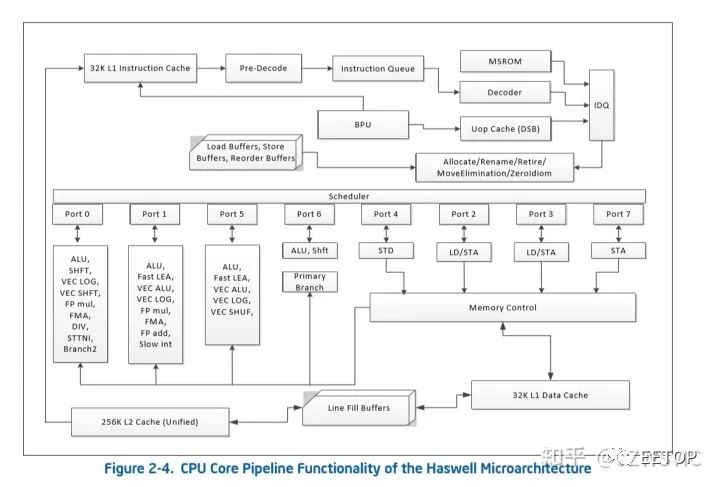
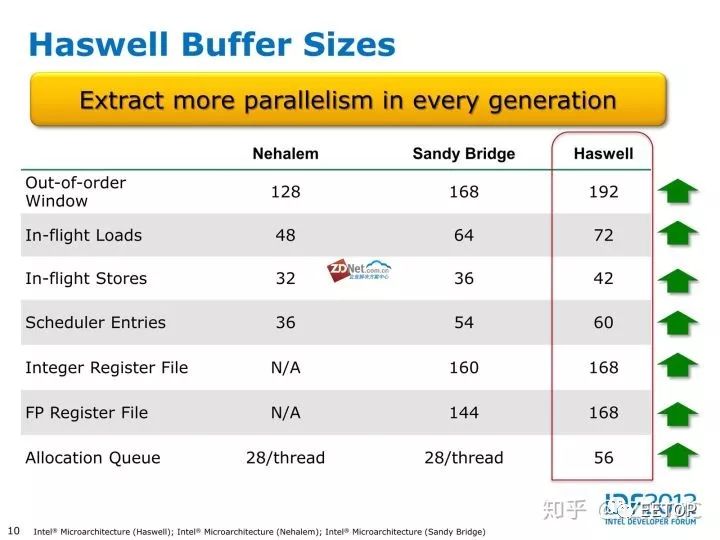
类似SKL那样的架构流水线图我暂时没有那么好的图,但是大致来说,相比SKL,ROB条目数从224降为192,前端解码宽度从5变成4(3简单1复杂),(依旧4发射),寄存器,allocation深度,都有下降,后端EU依旧是8端口,0.1.5三个端口依旧同时挂载向量和标量单元,依旧是2.3.4.7四个端口负责内存子系统,但是值得注意的是,Haswel开始intel主流处理器开始拥有2个FMA 256bit向量单元(端口0.1)但是与SKL不同的是,如果执行向量浮点加法只有端口1才能实现,端口0的FMA单元不能执行向量浮点加法,所以HSW/BDW的向量浮点加法是1X256峰值,乘法是2X256,乘加混合峰值是2X256 FMA,但是SKL则是2个FMA单元所在端口均可执行向量浮点加法
总的来说,HSW作为4发射,192ROB,8EU,双256 FMA,4内存子系统EU的处理器,架构依旧优秀于A75,根据Intel数据,SKL比HSW IPC平均高14-15%,所以按这样去换算GB4成绩,HSW依旧IPC高于A75。
HSW之前的便是SNB架构
SNB的情况很明显了,之前上面的图也有写SNB和HSW的对比,相比之下,寄存器,分发队列深度,ROB进一步下降,ROB数目为168(就这样还比A75多),前端依旧为四指令解码,但是这里可以看出,SNB的后端端口只有6了,这样在后端执行效率上A75有了一定机会追赶,同时内存子系统下降为3,2个L/STA,1个STD,这样来看内存性能并不会比A75高太多,同时Intel一直将branch,JMP,shuffle之类的单元与计算单元挂在同一个端口,虽然大幅提高了后端端口利用率,但是这样也在某些情况成为瓶颈,根据Intel数据,HSW又比SNB高了14-15%的IPC
同时SNB的向量单元下降为1X256 FP ADD/1X256 FP MUL/2X256 MUL+ADD(无FMA),向量int则为128bit(AVX2开始整数SIMD才升级为256)
从intel公布的IPC来看,SKL要比SNB IPC高30%以上,如果按GB4 4000分/3.2Ghz换算,假设完全符合Intel的数据,且频率对性能影响呈线性,SNB 2.8Ghz的GB4成绩大约为2600-2700分,这样算是很接近A75了,我查了一下,2410M(单核2.9Ghz)就是2700分左右,说明还是很准的。
最后便是NHM,
NHM的ROB终于减到128,前端解码宽度依旧为4,(3简单1复杂),总的μops为7(A75 9),同时NHM也没有了AVX,SSE SIMD向量宽度和NEON一样是128bit,执行1X128 FADD/1X128 FMUL,无FMA,同时6个后端执行端口,总体来说A75的架构指标和NHM接近,包括向量单元,根据Intel数据,SNB比NHM IPC高11%,这样依旧按GB4来推,2600/2700减去11%,大概的确和A75的GB4成绩很接近,而这从架构层面也是大致说得通的。
相比之下现今的Apollo Lake的Goldmont(包括Gemini Lake的Goldmont+,两者略有不同)更接近A75,比如前端三解码宽度,后端retired宽度增加到4,48-scheduler entries(介于NHM与SNB之间),后端来看Goldmont+也是8EU,4ALU,2FP ALU,1个L/S和一个AGU,Intel提到ROB会更大,但是并没有说明实际数值。
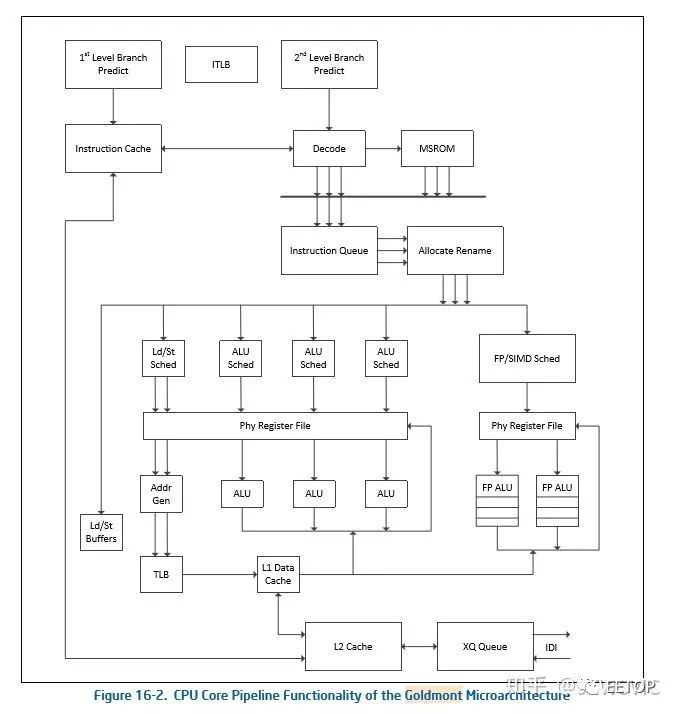
Goldmont
Goldmont+
GB4可靠吗?
我认为GB4的测试项目不是什么大问题,因为他有FFT和GEMM项目,这些项目支持到了AVX-512指令集,这足以让一堆古董测试软件汗颜,如果X86派喜欢安慰自己,看看GEMM和FFT成绩足以满足你的需要,当然ARM也可以堆SIMD单元,苹果的SIMD成绩依旧不差,从他的编译角度来说,Windows使用VS2015编译为windows运行程序(没用X86最快ICC)苹果用Xcode,测试内容从PDF,HTML,到ray-trace/FFT/GEMM,我认为这些项目是没什么大问题的,相对来说,Geekbench的问题是很多项目测试时间太短,以致于性能超强的处理器重载时间极短甚至没来得及重载就结束了,但是项目我认为不是什么问题,很多成绩其实也可以解释的通
14核7940X只比8核7820X多了这么一点点
Intel官方的IPC变化数据(见右图),SKL相比BDW高10%(见最上面的SKL架构流水线图)
所以从架构角度来说,A75的845和NHM/SNB架构比较接近,相当于4核NHM-SNB(当然还要看A75四大核全开的频率)而且因为设计的时代A75更晚,高通可以规避很多当初设计的一些问题,某些方面效率更高),但是也不代表ARM就没有猛男,苹果A11的架构(严格的说A7就是了)和9810的架构就是一个很多方面超过SKL的规模的胖核心,而很多人说那为什么835跑win10那么差,这里要提到一个往事,
Transmeta公司曾经对x86指令集的Emulation(Emulation这个词很难翻译)。简单地说,Emulation就是把x86指令集看成一个虚拟机的指令集,然后用类似JIT编译器的技术
如今最广为人知的Emulator是Qemu,x86、MIPS、PowerPC、Sparc、MC68000它都可以支持。一般而言,Emulation会导致性能下降一个甚至若干个数量级,根本不足为虑。
1995年,Transmeta公司成立,经过艰苦的秘密研发,于2000年推出了Crusoe处理器,用Emulation的方式,在一款VLIW(超长指令字)风格的CPU上执行x86的程序,这样就规避了没有x86指令集授权的问题。Transmeta的牛X在于,虽然是Emulation,但实现了相对接近Intel处理器的性能,同时功耗低很多。2000年年底Transmeta的IPO大获成功,其风光程度,直到后来谷歌IPO的时候才被超过。
Transmeta最后还是失败了,Intel在渠道上打压它是次要原因,性能不足是主要原因。虽然VLIW在90年代中后期被广为推崇,但事实证明,它的性能比起乱序执行的超标量架构,还是差一截。
而微软也是用了这么一个技术,实现了直接的骁龙835运行原本编译为X86指令集的程序,但是这样不可避免性能要下降,而且未经许可翻译别人的ISA做CPU是有违反专利可能的,为此,Intel在去年发表博客 Intel's X86: Approaching 40 and Still Going Strong。
细数X86扩展的同时也强调专利问题,暗指某些公司试图仿真X86 ISA(try to emulate Intel’s proprietary x86 ISA without Intel’s authorization),不过实践证明,这样的仿真并没有真正构成侵犯专利,高通和微软这样做造成的性能损失已经比直接使用虚拟机好很多,但是内存模型导致的差异,Emulation造成的性能损失不可避免。
作者:AiHaibara
由于搭载骁龙845的Windows设备还没出现,可以用骁龙835做一个推测。
目前骁龙835已经被用在了笔记本上,跑Windows系统后,跑分大幅下降。这是现在市面上两款搭载骁龙835的笔记本,华硕NovaGo和惠普Envy X2,跑分差不多单核850,多核3000上下。
华硕NovaGo跑分
▲惠普Envy X2跑分
我们都知道安卓系统下,骁龙835跑分是单核1900左右,多核6500左右,而骁龙845是单核2400左右,多核8500左右。单核和多核分别差不多有25%和30%的提升,按照这个提升幅度,推测骁龙845跑Windows系统大概是单核1100左右,多核4000左右。Windows系统下符合这个分数的英特尔处理器大概是奔腾N4200,赛扬J3455这种低频U的水平。主频过2GHz的奔腾或赛扬单核分数就很高了。
像超低压版的i5-4300Y,骁龙845也就凭借多出四倍的核心数和两倍的线程在多核分数持平,单核完全被按在地上摩擦。
总之骁龙845虽然放手机里很强,但是和电脑处理器还是没法比,不是一个级别的东西。 以上均为个人的推测观点。
作者:张杀猪
定调:845综合性能肯定是远远不如高端桌面平台的,目测大概是CM水平。量化方式基本就是整数浮点内存带宽IO速度,GPGPU通用计算纹理顶点等等。
这个答案给我最大的启示就是,不要和“本不打算讲道理的人”讲道理。建议蜜汁尬杠的人先想一想什么是性能,什么决定了性能,只有在达成这一共识之后,接下来的讨论才有意义。
本题是讨论845相当于桌面的哪个档次,不是讨论手机电脑谁强,更不是讨论简单/复杂指令集的问题。从定位上来看,845最多算民用旗舰级,因为手机芯片本身定位的划定就没有桌面端复杂,和服务器端的E5并不是对应的,桌面端在定位上类似的最多就是民用i7,如果硬要讨论手机端和电脑端整体性能差距,那就对比845是i7 8700k的几分之一就行了,在市场占有率上这两者是比较普及的。如果硬要抬杠,arm端也不是没有服务器设备,非得说cisc或者risc什么的,建议抬出神威太湖之光(alpha是简单指令集的)。
另外提一下,这么多人张口闭口就说简单指令集什么的,我敢说至少有百分之八十的人除了几个词以外一无所知,根本不知道指令集是什么。
该问题以下,大量的反智答案和评论,很难想象科学如此普及的今天,玄学主义还如此盛行。
pps:和智商不够的人辩论本身就是我的失误,我强烈建议和我抬杠这种问题的人先把本科的数电模电过了,再学学简单的COMS相关,有条件读两年安卓开发,否则我说的术语连看都看不懂,直接瞎掰真绝了,说atom秒arm旗舰的被打脸之后,开始扯a11和至尊i7甚至i9强弱问题了,并且开始积极的百度出部分服务器处理器型号。在此奉劝一下,这是一个关于骁龙845性能的问题,我的答案也从来没那么极端的说秒这个那个的,从一开始我也就说845cpu性能基本六七代CM,初代i3到i5水平,抬杠的自行滚蛋,没时间和民科浪费,强烈建议卸载知乎,去今日头条淘宝头条秀优越。
ps:每一次受邀请回答问题,都是抱着一个和平交流的心态,然而总是有人试图无脑喷,那么我在此郑重重复一下,对于只用生殖器交流的人,我就只能尽力把对方生殖器赛进对方本人的呼吸道。
有些人确实很可恶,就好比连初中数学题都搞不定,非要去解本科难度的高阶偏微分线性方程,虽然自己完全不会算,但是却毫无根据的指责其他算出来的人不正确,并且完全不讲逻辑,上来就一句钦定不对。那么我很不友善的提醒一句,就您这两把刷子,just pee as the mirror(恶搞英语,不要当真)。
我水平不高,但是我不装逼啊,我不骂人啊,我不懂的我不说行吧。
对楼上某些答案。为什么你们愿意相信一个专门为x86架构设计的系统,能够完整发挥arm的性能?
说我连uwp都不知道,神tm逻辑,莫不是活在十年前,uwp用过吗你,这次835平板是虚拟机上的win10,可以运行32bit .exe应用的,win10uwp和win10都分不清,硬件软件常识都不知道就想来我答案下拉屎,还出来挂我,给你留点面子本来不想说太多,自己出来找丢人。果断拉黑。
科普一下:UWP即Windows 10中的Universal Windows Platform简称。即Windows通用应用平台,在Win 10 Mobile/Surface(Windows平板电脑)/PC/Xbox/HoloLens等平台上运行,uwp不同于传统pc上的exe应用,也跟只适用于手机端的app有本质区别。它并不是为某一个终端而设计,而是可以在所有windows10设备上运行。
对于挂我的那位,诺基亚lumia1520上那个才是uwp,不懂装懂别丢人了,uwp上跑分你见过吗,骁龙800GPU就吊打BT,cpu整数差不多,整个bt只有atom z3740以上才算凑合,845比800综合提升六倍不止,cpu提升不少于三倍,还提赛扬?起码来说845相当于core m档次,赛扬除了CPU多核跑分以外也没别的了。
我估计很多人非常难以接受,n多年前大几千配的电脑,还不如现在两千多块钱的手机。况且前者的功耗是后者的几十倍。
在目前的CMOS技术中,刨除英特尔,其他工艺基本上高频性能功耗比都不怎么地,比方说三星本代旗舰Exynos9810的 M3核心,采用三星10nmLPP工艺。在同样3w功耗下,单核心能跑到2.7GHz,双核心2.4,四核心则是1.8GHz,也就是说当频率到一个高度之后,再提高一点可能都要巨大的功耗代价。所以不要想当然的认为功耗高就性能强。
回到x86和ARM这样老生常谈的问题,我有一个答案愿意抛砖引玉,不太专业,但是可以作为一个科普的参考。
原文:用845带模拟器跑分,然后用赛扬跑原生win10,亏你们想的出来。还不如反过来跑安兔兔,被动散热的845手机能27万分,主动散热i5 6300h+950m开模拟器也就30万。用以上的逻辑就能认为i5 6300h等于845等于n3450了?i5 4210m等于835等于atom z8500?用赛扬以及核显开个模拟器打个崩坏3,刺激战场啥的让我见识一下。我五百块买的寨板赚大了。要怀疑最多也就是从跑分软件入手,这么双标真无解。
这就是传说中的arm版win10,Win10把x86转成arm让835跑,不知道有没有硬件编译层,本人英语一般,就不翻译了,大家自己看这效率和native比如何。目测还不如x86模拟器跑安卓。
-
ARM
+关注
关注
134文章
9083浏览量
367364 -
X86
+关注
关注
5文章
294浏览量
43443 -
骁龙845
+关注
关注
4文章
536浏览量
57026
原文标题:高通骁龙845到底相当于哪一个级别的英特尔PC端处理器?
文章出处:【微信号:eetop-1,微信公众号:EETOP】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
X86与ARM,江湖厮杀鹿死谁手?
Powerpc架构与X86架构的区别
ARM版和x86版Windows 8的区别
骁龙820支持Win10运行x86程序 性能可媲美i3!
骁龙835相当于酷睿几代_骁龙835相当于intel的哪个级别
什么叫arm架构_X86架构与ARM架构有什么区别
一文看懂arm架构和x86架构有什么区别
医疗设备逐渐从X86转到ARM平台主要原因是什么
X86主板与ARM硬件平台之间的区别是什么
ARM架构和X86架构二者之间的区别是什么
X86架构与Arm架构的区别





 工商网监
工商网监
评论