 机器学习模型也能分得清菜系吗?
机器学习模型也能分得清菜系吗?

吃饭的时候会见到很多奇怪的菜名,很多店常常会取一些奇怪的名字来吸引眼球,吃饭的时候基本靠猜,或者……通过食材预估一下彩色和口味是否符合自己的要求。其实通过食材预测菜系,用 python 也可以做到!
可以用机器学习的方法搭建、训练和测试模型,并通过评估矩阵来选择最优模型,实现原材料与菜系的映射。为了实现预期的功能,我们需要进行以下三个步骤。
1.加载并分析数据
2.建立模型
3.模型预测
加载并分析数据
以意大利菜系为例,我们准备好以下格式的样例数据。其中“id”代表不同的菜肴种类,“cuisine”则代表菜系名称。
拿到数据后,首先对数据进行提取,其中配方节点如下。其中包含了食谱 id,菜肴类型和成分列表的训练集。
之后将 features 与 target 分别赋值到 train_ingredients 和 train_targets。通过统计分析等操作,可以计算出使用最频繁的前 10 种原料,并将原料名和出现次数赋值到 sum_ingredients 字典中。通过样例数据,还能计算出意大利菜系中使用最频繁的前 10 种原料,并将原料名和出现次数赋值到 italian_ingredients 字典中。
得到的结果可以通过 matplotlib 进行可视化。通过数据分析,可以得出许多有意思的信息,比如,巴西菜用的最多的食材有洋葱、橄榄油、柠檬等。而在中国,柠檬显然不是家常饭的常客。我们用的最多的食材有酱、芝麻油、玉米淀粉等。小编猜测,老干妈一定对中国排名第一的食材有巨大贡献!
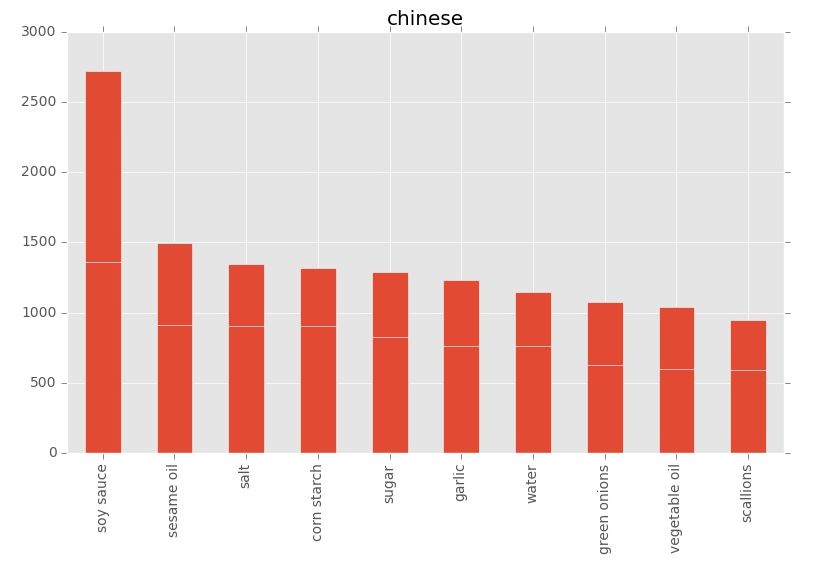
日本比较有特色的清酒和酱油也都榜上有名。而在寒冷的俄罗斯,黄油则成为餐桌上必不可少的食材,成为战斗民族每天所需能量的重要来源。英国更不必多说,如果你热爱黄油、奶油、土豆和牛奶,去英国就是了!
建立模型
建立模型的过程可能稍微有点复杂,主要分以下四步进行:
1、单词清洗
2、特征提取(使用TF_IDF)
3、数据分割与重排
调用 train_test_split 函数将训练集划分为新的训练集和验证集。
4、训练模型
在训练模型的过程中,需要尝试不同的参数,挑选出泛化力最好的模型。通过训练模型,可以计算得出验证集上的得分。得分越高,说明分类准确度(正确分类的菜肴百分比)越高。这样,一个优秀的模型就大功告成啦!
模型预测
在测试文件 test.json 中,配方的格式与 train.json 相同,只删除了美食类型,因为它是我们要预测的目标变量。
总的来说,要实现通过食材预测菜系的过程并不复杂,但是如何完善代码、优化模型,使分类体系和匹配程度更高,才是我们要完成的关键目标。如果不能做到数据的有效清洗和分类,就会出现很多法国菜被误分为意大利菜这样的情况。
至于能不能分清川菜和湘菜……可以自己来试一试!这个项目其实来自优达学城 Udacity 的「机器学习工程师」纳米学位。
优达学城 Udacity由Google 无人车之父Sebastion Thrun创立,与Google、Facebook、亚马逊等名企联合打造了一系列前沿技术课程,旨在让每个人都能用远低于线下教育的成本学习硅谷前沿技术,最终成为有能力通过技术改变世界的抢手人才。2017 年8 月,腾讯宣布将 Udacity 纳米学位项目作为内部员工学习内容。
与国内其他平台相比,Udacity 的一大优势是来自硅谷的独家特色实战项目。项目难度深入浅出,能够让学习者快速将所学运用到实际生活,并直观看到学习成果。下面的部分项目成果示例来自「机器学习工程师」和「深度学习」纳米学位的正式课程:
项目示例 1训练机器人走迷宫
通过实现 Q-learning 算法解决走迷宫问题。同时你有机会将你的算法应用在股市中,让机器学习出高收益策略。
项目示例 2猫狗图像识别
使用深度学习方法识别图片中是猫还是狗。
实战项目示例 3训练四轴飞行器学会飞行
设计一个深度强化学习系统,构建惩罚函数、强化学习模型、深度学习隐藏层帮助四轴飞行器了解每一个动作的优劣。你的四轴飞行器将从一系列动作状态中,选择最优的策略来平稳起飞和降落。
实战项目示例 3风格迁移
深度学习模型可以用来完成「风格迁移」项目。神经网络会学习这些画作采用的技巧,并学会如何自己应用这些绘画技巧。
-
机器学习
+关注
关注
67文章
8564浏览量
137215 -
python
+关注
关注
58文章
4885浏览量
90302
原文标题:机器学习模型,能分清川菜和湘菜吗?
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

什么是机器学习? 机器学习基础入门
指令和伪指令分得清吗?

统计学和机器学习的真正差别。你分得清吗?
微处理器也能实现机器学习?
灯具的种类百科:你分得清哪些是可以调光的吗
SB接头那么多种怎么分得清

激光加工纳秒激光、皮秒激光、飞秒激光,你分得清吗?




评论