 经典的机器学习算法汇总
经典的机器学习算法汇总
浓缩就是精华。想要把书写厚很容易,想要写薄却非常难。现在已经有这么多经典的机器学习算法,如果能抓住它们的核心本质,无论是对于理解还是对于记忆都有很大的帮助,还能让你更可能通过面试。在本文中,SIGAI将用一句话来总结每种典型的机器学习算法,帮你抓住问题的本质,强化理解和记忆。下面我们就开始了。
贝叶斯分类器
核心:将样本判定为后验概率最大的类
贝叶斯分类器直接用贝叶斯公式解决分类问题。假设样本的特征向量为x,类别标签为y,根据贝叶斯公式,样本属于每个类的条件概率(后验概率)为:
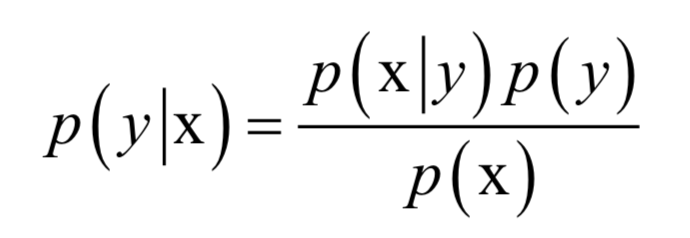
分母p(x)对所有类都是相同的,分类的规则是将样本归到后验概率最大的那个类,不需要计算准确的概率值,只需要知道属于哪个类的概率最大即可,这样可以忽略掉分母。分类器的判别函数为:
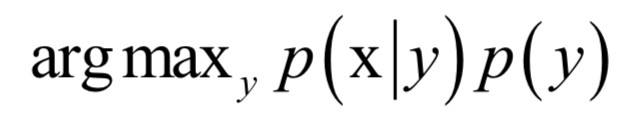
在实现贝叶斯分类器时,需要知道每个类的条件概率分布p(x|y)即先验概率。一般假设样本服从正态分布。训练时确定先验概率分布的参数,一般用最大似然估计,即最大化对数似然函数。
贝叶斯分分类器是一种生成模型,可以处理多分类问题,是一种非线性模型。
决策树
核心:一组嵌套的判定规则
决策树在本质上是一组嵌套的if-else判定规则,从数学上看是分段常数函数,对应于用平行于坐标轴的平面对空间的划分。判定规则是人类处理很多问题时的常用方法,这些规则是我们通过经验总结出来的,而决策树的这些规则是通过训练样本自动学习得到的。下面是一棵简单的决策树以及它对空间的划分结果:
训练时,通过最大化Gini或者其他指标来寻找最佳分裂。决策树可以输特征向量每个分量的重要性。
决策树是一种判别模型,既支持分类问题,也支持回归问题,是一种非线性模型(分段线性函数不是线性的)。它天然的支持多分类问题。
kNN算法
核心:模板匹配,将样本分到离它最相似的样本所属的类
kNN算法本质上使用了模板匹配的思想。要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计这些样本的类别进行投票,票数最多的那个类就是分类结果。下图是kNN算法的示意图:
在上图中有红色和绿色两类样本。对于待分类样本即图中的黑色点,寻找离该样本最近的一部分训练样本,在图中是以这个矩形样本为圆心的某一圆范围内的所有样本。然后统计这些样本所属的类别,在这里红色点有12个,圆形有2个,因此把这个样本判定为红色这一类。
kNN算法是一种判别模型,即支持分类问题,也支持回归问题,是一种非线性模型。它天然的支持多分类问题。kNN算法没有训练过程,是一种基于实例的算法。
PCA
核心:向重构误差最小(方差最大)的方向做线性投影
PCA是一种数据降维和去除相关性的方法,它通过线性变换将向量投影到低维空间。对向量进行投影就是让向量左乘一个矩阵得到结果向量,这是线性代数中讲述的线性变换:
y = Wx
降维要确保的是在低维空间中的投影能很好的近似表达原始向量,即重构误差最小化。下图是主分量投影示意图:
在上图中样本用红色的点表示,倾斜的直线是它们的主要变化方向。将数据投影到这条直线上即完成数据的降维,把数据从2维降为1维。计算最佳投影方向时求解的最优化问题为:
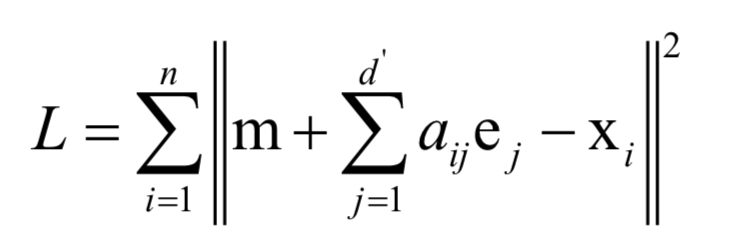
最后归结为求协方差矩阵的特征值和特征向量:
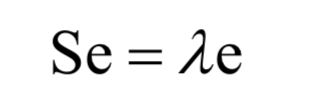
PCA是一种无监督的学习算法,它是线性模型,不能直接用于分类和回归问题。
LDA
核心:向最大化类间差异、最小化类内差异的方向线性投影
线性鉴别分析的基本思想是通过线性投影来最小化同类样本间的差异,最大化不同类样本间的差异。具体做法是寻找一个向低维空间的投影矩阵W,样本的特征向量x经过投影之后得到的新向量:
y = Wx
同一类样投影后的结果向量差异尽可能小,不同类的样本差异尽可能大。直观来看,就是经过这个投影之后同一类的样本进来聚集在一起,不同类的样本尽可能离得远。下图是这种投影的示意图:
上图中特征向量是二维的,我们向一维空间即直线投影,投影后这些点位于直线上。在上面的图中有两类样本,通过向右上方的直线投影,两类样本被有效的分开了。绿色的样本投影之后位于直线的下半部分,红色的样本投影之后位于直线的上半部分。
训练时的优化目标是类间差异与类内差异的比值:
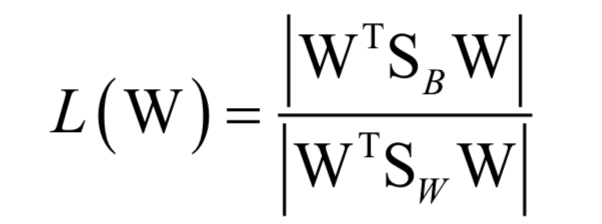
最后归结于求解矩阵的特征值与特征向量:
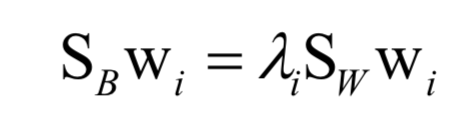
LDA是有监督的机器学习算法,在计算过程中利用了样本标签值。这是一种判别模型,也是线性模型。LDA也不能直接用于分类和回归问题,要对降维后的向量进行分类还需要借助其他算法,如kNN。
LLE(流形学习)
核心:用一个样本点的邻居的线性组合近似重构这个样本,将样本投影到低维空间中后依然保持这种线性组合关系
局部线性嵌入(简称LLE)将高维数据投影到低维空间中,并保持数据点之间的局部线性关系。其核心思想是每个点都可以由与它相近的多个点的线性组合来近似,投影到低维空间之后要保持这种线性重构关系,并且有相同的重构系数。
算法的第一步是求解重构系数,每个样本点xi可以由它的邻居线性表示,即如下最优化问题:
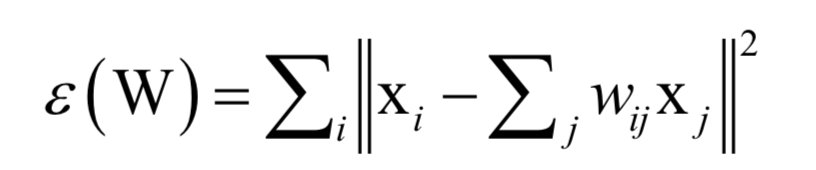
这样可以得到每个样本点与它邻居节点之间的线性组合系数。接下来将这个组合系数当做已知量,求解下面的最优化问题完成向量投影:
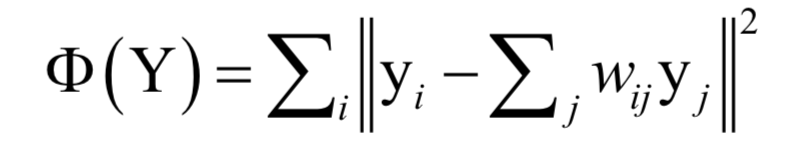
这样可以得到向量y,这就是投影之后的向量。
LLE是一种无监督的机器学习算法,它是一种非线性降维算法,不能直接用于分类或者回归问题。
等距映射(流形学习)
核心:将样本投影到低维空间之后依然保持相对距离关系
等距映射使用了微分几何中测地线的思想,它希望数据在向低维空间映射之后能够保持流形上的测地线距离。所谓测地线,就是在地球表面上两点之间的最短距离对应的那条弧线。直观来看,就是投影到低维空间之后,还要保持相对距离关系,即投影之前距离远的点,投影之后还要远,投影之前相距近的点,投影之后还要近。
我们可以用将地球仪的三维球面地图投影为二维的平面地图来理解:
投影成平面地图后为:
在投影之前的地球仪上,美国距离中国远,泰国距离中国近,投影成平面地图之后,还要保持这种相对远近关系。
等距映射是一种无监督学习算法,是一种非线性降维算法。
人工神经网络
核心:一个多层的复合函数
人工神经网络在本质上是一个多层的复合函数:
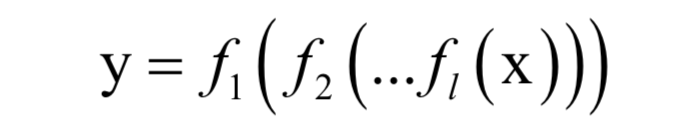
它实现了从向量x到向量y的映射。由于使用了非线性的激活函数f,这个函数是一个非线性函数。
神经网络训练时求解的问题不是凸优化问题。反向传播算法由多元复合函数求导的链式法则导出。
标准的神经网络是一种有监督的学习算法,是一种非线性模型,它既可以用于分类问题,也可以用于回归问题,天然的支持多分类问题。
支持向量机
核心:最大化分类间隔的线性分类器(不考虑核函数)
支持向量机的目标是寻找一个分类超平面,它不仅能正确的分类每一个样本,并且要使得每一类样本中距离超平面最近的样本到超平面的距离尽可能远。
训练时求解的原问题为:
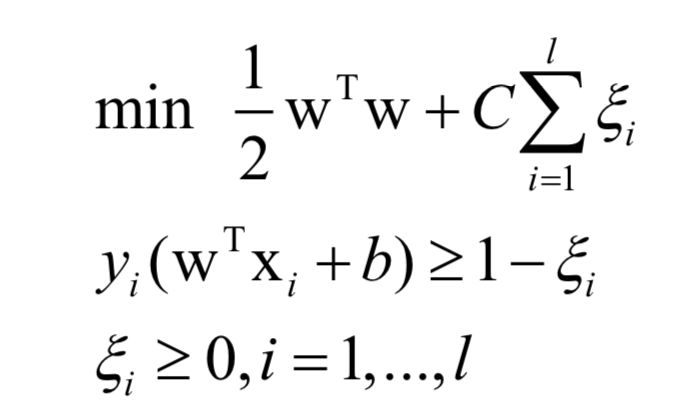
对偶问题为:
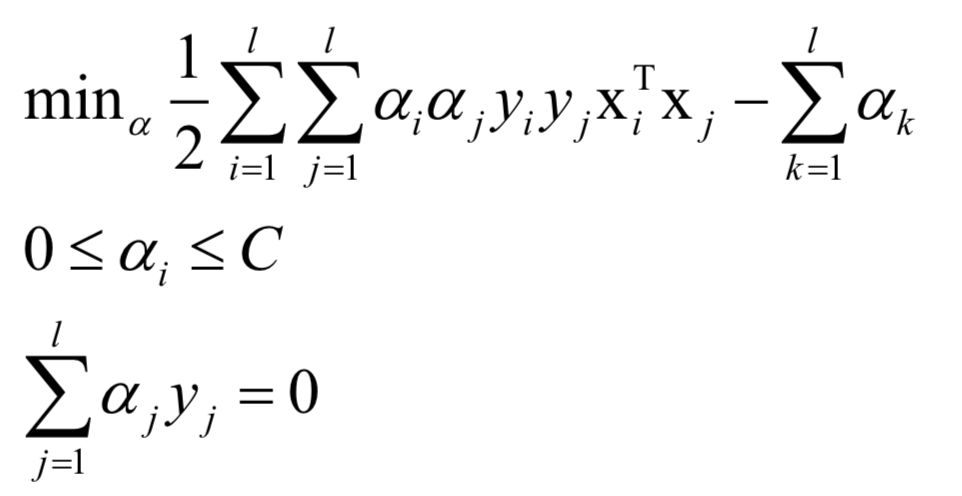
对于分类问题,预测函数为:
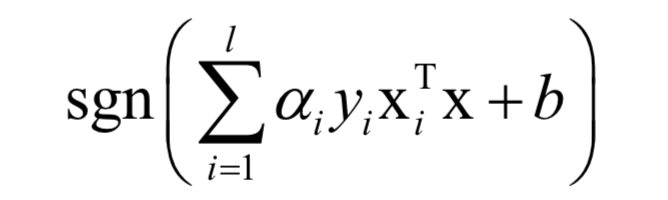
如果不使用非线性核函数,SVM是一个线性模型。使用核函数之后,SVM训练时求解的对偶问题为:
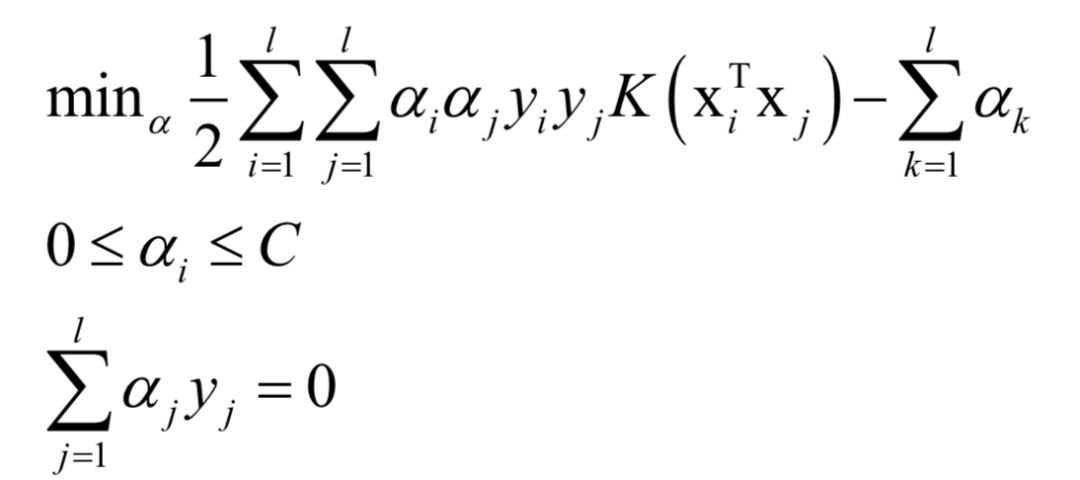
对于分类问题,预测函数为:
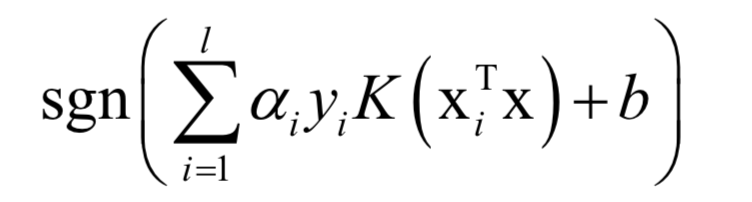
如果使用非线性核,SVM是一个非线性模型。
训练时求解的问题是凸优化问题,求解采用了SMO算法,这是一种分治法,每次挑选出两个变量进行优化,其他变量保持不动。选择优化变量的依据是KKT条件,对这两个变量的优化是一个二次函数极值问题,可以直接得到公式解。
SVM是一种判别模型。它既可以用于分类问题,也可以用于回归问题。标准的SVM只能支持二分类问题,使用多个分类器的组合,可以解决多分类问题。
logistic回归
核心:直接从样本估计出它属于正负样本的概率
通过先将向量进行线性加权,然后计算logistic函数,可以得到[0,1]之间的概率值,它表示样本x属于正样本的概率:
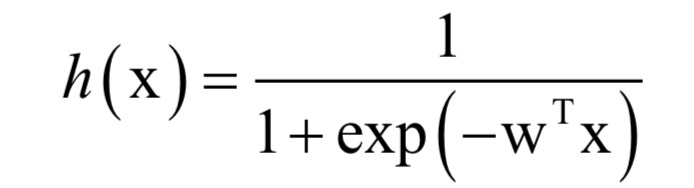
正样本标签值为1,负样本为0。训练时,求解的的是对数似然函数:
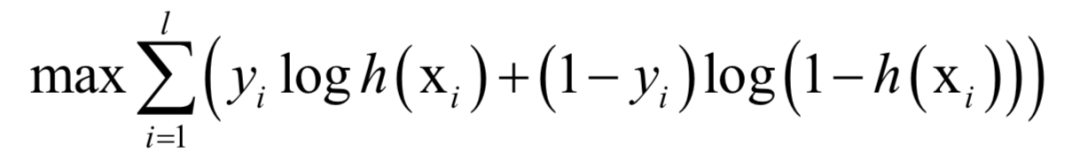
这是一个凸优化问题,求解时可以用梯度下降法,也可以用牛顿法。
logistic回归是一种判别模型,需要注意的是它是一种线性模型,用于二分类问题。
随机森林
核心:用有放回采样的样本训练多棵决策树,训练决策树的每个节点是只用了无放回抽样的部分特征,预测时用这些树的预测结果进行投票
随机森林是一种集成学习算法,它由多棵决策树组成。这些决策树用对训练样本集随机抽样构造出样本集训练得到。随机森林不仅对训练样本进行抽样,还对特征向量的分量随机抽样,在训练决策树时,每次分裂时只使用一部分抽样的特征分量作为候选特征进行分裂。
对于分类问题,一个测试样本会送到每一棵决策树中进行预测,然后投票,得票最多的类为最终分类结果。对于回归问题随机森林的预测输出是所有决策树输出的均值。
假设有n个训练样本。训练每一棵树时,从样本集中有放回的抽取n个样本,每个样本可能会被抽中多次,也可能一次都没抽中。用这个抽样的样本集训练一棵决策树,训练时,每次寻找最佳分裂时,还要对特征向量的分量采样,即只考虑部分特征分量。
随机森林是一种判别模型,既支持分类问题,也支持回归问题,并且支持多分类问题。这是一种非线性模型。
AdaBoost算法
核心:用多个分类器的线性组合来预测,训练时重点关注错分的样本,准确率高的弱分类器权重大
AdaBoost算法的全称是自适应boosting(Adaptive Boosting),是一种用于二分类问题的算法,它用弱分类器的线性组合来构造强分类器。弱分类器的性能不用太好,仅比随机猜测强,依靠它们可以构造出一个非常准确的强分类器。强分类器的计算公式为:
其中x是输入向量,F(x)是强分类器,ft(x)是弱分类器,at是弱分类器的权重,T为弱分类器的数量,弱分类器的输出值为+1或-1,分别对应正样本和负样本。分类时的判定规则为:
sgn(F(x))
强分类器的输出值也为+1或-1,同样对应于正样本和负样本。
训练时,依次训练每一个若分类器,并得到它们的权重值。在这里,训练样本带有权重值,初始时所有样本的权重相等,在训练过程中,被前面的弱分类器错分的样本会加大权重,反之会减小权重,这样接下来的弱分类器会更加关注这些难分的样本。弱分类器的权重值根据它的准确率构造,精度越高的弱分类器权重越大。
AdaBoost算法从广义加法模型导出,训练时求解的是指数损失函数的极小值:
L(y, F(x)) = exp(-yF(x))
求解时采用了分阶段优化,先得到弱分类器,然后确定弱分类器的权重值。
标准的AdaBoost算法是一种判别模型,只能支持二分类问题。它的改进型可以处理多分类问题。
卷积神经网络
核心:一个共享权重的多层复合函数
卷积神经网络在本质上也是一个多层复合函数,但和普通神经网络不同的是它的某些权重参数是共享的,另外一个特点是它使用了池化层。训练时依然采用了反向传播算法,求解的问题不是凸优化问题。
和全连接神经网络一样,卷积神经网络是一个判别模型,它既可以用于分类问题,也可以用用于回归问题,并且支持多分类问题。
循环神经网络
核心:综合了复合函数和递推数列的一个函数
和普通神经网络最大的不同在于,循环神经网络是一个递推的数列,因此具有了记忆功能。回忆我们高中时所学的等差数列:
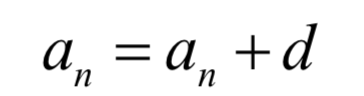
一旦数列的首项a0以及公差d已经确定,则后面的各项也确定了,这样后面各项完全没有机会改变自己的命运。循环神经网络也是这样一个递推数列,后一项由前一项的值决定,但除此之外还接受了一个次的输入值,这样本次的输出值既和之前的数列值有关,由于当前时刻的输入值有关,有机会通过当前输入值改变自己的命运:
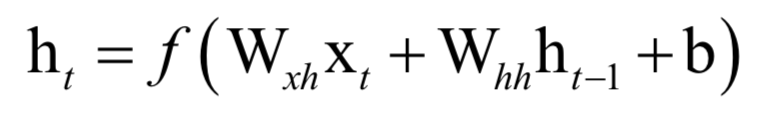
和其他类型的神经网络一样,循环神经网络是一个判别模型,既支持分类问题,也支持回归问题,并且支持多分类问题。
K均值算法
核心:把样本分配到离它最近的类中心所属的类,类中心由属于这个类的所有样本确定
k均值算法是一种无监督的聚类算法。算法将每个样本分配到离它最近的那个类中心所代表的类,而类中心的确定又依赖于样本的分配方案。这是一个先有鸡还是先有蛋的问题。
在实现时,先随机初始化每个类的类中心,然后计算样本与每个类的中心的距离,将其分配到最近的那个类,然后根据这种分配方案重新计算每个类的中心。这也是一种分阶段优化的策略。
k均值算法要求解的问题是一个NPC问题,只能近似求解,有陷入局部极小值的风险。
-
算法
+关注
关注
23文章
4629浏览量
93261 -
机器学习
+关注
关注
66文章
8438浏览量
132998 -
决策树
+关注
关注
3文章
96浏览量
13582 -
贝叶斯分类器
+关注
关注
0文章
6浏览量
2313
原文标题:一文总结常用的机器学习算法
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐








 工商网监
工商网监
评论