 Dropout如何成为SDR的特殊情况
Dropout如何成为SDR的特殊情况
编者按:多层神经网络在多种基准任务上都有了显著成果,例如文本、语音和图像处理。尽管如此,这些深层神经网络会导致高维非线性的参数空间,让搜索难以进行,并且还会导致过度拟合和较差的泛化。早期由于数据不足、无法恢复梯度损失以及不良局部最小值而引起的高捕捉概率,让使用反向传播的神经网络很容易失败。
2006年,Hinton的深度学习提出了一些创新的方法以减少这些过度拟合和过度参数化的问题,包括减少连续梯度损失的ReLU和Dropout等。在这篇文章中,美国罗格斯大学的两位研究者将关注深层网络的过度参数化问题,尽管现在各项分类任务都有大量可用的数据。本文已提交到NIPS 2018,以下是论智对原文的大致编译,如有错误请批评指正。
Dropout是用来减轻过度参数化、深度学习的过拟合以及避免偶然出现的不良局部最小值。具体说来,Dropout在每次更新时会添加一个带有概率p的Bernoulli随机变量、删除隐藏的单元以及网络中的连接,从而创造一个稀疏的网络架构。学习结束后,深度学习网络会通过计算每个权重的期望值进行重组。大多数案例证明,深度学习的Dropout能将常见基准的错误减少50%以上。
在这篇论文中,我们将介绍一种通用的Dropout类型,它可以在权重层面操作,在每次更新中插入梯度相关的噪音,称为随机Delta规则(SDR)。SDR是在每个权重上执行一个随机变量,并对随机变量中的每个参数提供更新之后的规则。虽然SDR在任意随机变量下都能工作,但是我们将展示,Dropout在拥有二项式随机变量中的固定参数下是非常特别的。最终我们在含有高斯SDR的标准基准下测试DenseNet,结果证明二项式Dropout有着非常大的优势。
随机delta规则(SDR)
众所周知,神经传输会包含噪声。如果皮质分离的神经元受到周期性、相同的刺激,将会产生不同的反应。SDR的部分motivation是基于生命系统中信号在神经元之间传播的随机性。显然,平滑的神经速率函数是基于很多刺激实验得来的平均值,这使得我们认为两个神经元之间的突触可以用一个具有固定参数的分布建模。
图1显示了我们用一个高斯随机变量和平均µwij以及σwij实施的SDR算法。每个权重都会从高斯随机变量中进行采样。实际上,和Dropout一样,很多网络都是在训练时的更新中进行采样。这里和Dropout的不同之处在于,SDR在更新时,会根据错误的梯度调整权重和隐藏单元。
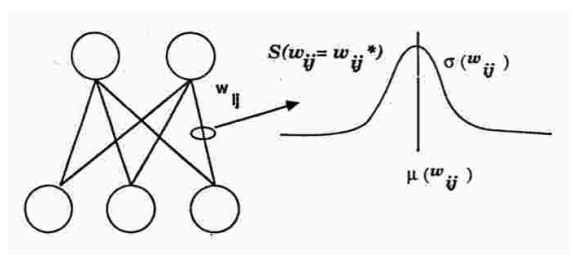
图1
因此,每个权重梯度就是基于隐藏单元的随机变量,基于此,系统可以:
给定相同的样本/奖励,生成多个回复假设
保持历史预测,而不像Dropout一样只有局部的隐藏单元权重
有可能会返回到不良局部最小值而造成贪婪搜索,但同时越来越远离更好的局部最小值
最后一个优点是,如Hinton所说,局部噪声的插入可能会导致收敛到更好的局部最小值的速度更快、更稳定。
实施SDR有三个更新规则,以下是权重分布中的权重值的更新规则:
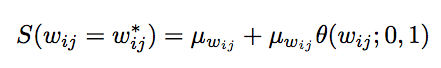
第一个更新规则用于计算权重分布的平均数:
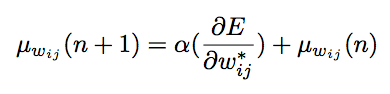
第二个用于权重分布的标准偏差:
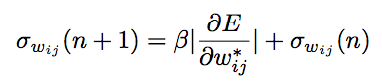
第三种是将标准偏差收敛到0,让平均权重值达到一个固定点,将所有样本都聚集起来:
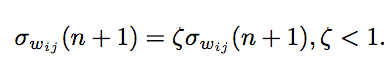
接下来,我们将讲述Dropout如何成为SDR的特殊情况。最明显的方法是首先将随机搜索看作一种特殊的采样分布。
将Dropout看作SDR的二项式固定参数
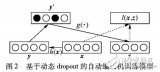
如之前所说,Dropout需要将每层的隐藏单元在Bernoulli过程中删除。如果我们在同样的网络中,将Dropout和SDR进行对比,可以发现二者的不同在于随机处理是否影响了权重或隐藏单元。图2我们描述了Dropout在隐藏单元采样时的收敛。可以看到明显的不同是,SDR在适应性地更新随机变量参数,而Dropout是用固定参数进和Binomial随机变量进行采样。另一个重要区别在于,SDR在隐藏层中的共享权重比Dropout的更“局部”。
图2
那么,SDR所表现出的参数的增加,是否使得搜索更加有效、更加稳定?下一步我们将开展实验。
测试及结果
这里我们采用了在TensorFlow上搭建的经过改进的DenseNet。模型用DenseNet-40、DenseNet-100和DenseNet-BC 100网络,它们经过了CIFAR-10和CIFAR-100的训练,初始DenseNet参数相同。
最终的结果显示,将SDR换成Dropout后的DenseNet测试中,错误率下降了50%以上。
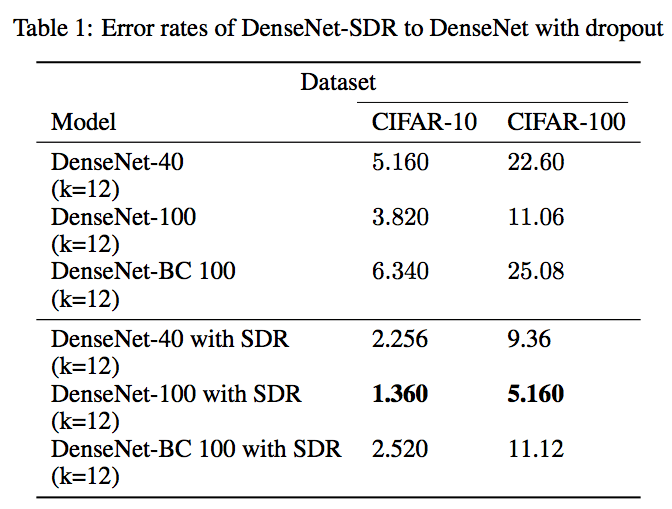
同时在错误率分别为15、10和5的情况下,训练所需次数也比单独DenseNet减少:
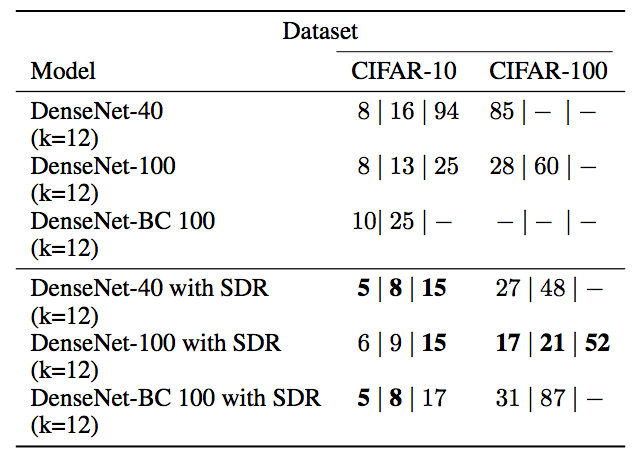

训练精确度(DenseNet-100橙色,有SDR的DenseNet-100,蓝色)
结语
这篇文章展示了一个基础的深度学习算法(Dropout)是如何实施随机搜索并帮助解决过度拟合的。未来我们将展示SDR是如何超越Dropout在深度学习分类中的表现的。
数据科学家、fast.ai创始人Jeremy Howard点评:“如果该论文结果真的这么好,那绝对值得关注。”
但是谷歌机器学习专家David Ha有不同意见:“结果看上去很可疑(我觉得他们搞错了)。CIFAR-10的准确率能到98.64%,CIFAR-100真的能到94.84%吗?”
-
神经元
+关注
关注
1文章
368浏览量
18562 -
Dropout
+关注
关注
0文章
13浏览量
10092 -
深度学习
+关注
关注
73文章
5527浏览量
121893
原文标题:争议 | 错误减少50%!这难道是更快更准确的深度学习?
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
SDR_SDR是什么意思

介绍SDR的技术原理 以SDR LTE系统为例进一步解析SDR系统的工作流程
ref sdr sdram verilog代码
SDR SDRAM Controller (White Pa
ref sdr sdram vhdl代码
dropout正则化技术介绍
SDR的技术原理介绍及案例分析
基于动态dropout的改进堆叠自动编码机方法
执行节点分析时的特殊情况介绍






 工商网监
工商网监
评论