 虚拟到现实的翻译网络如何满足自动驾驶要求?
虚拟到现实的翻译网络如何满足自动驾驶要求?

加州大学伯克利分校的Xinlei Pan等人提出了一种虚拟到现实(Virtual to Real)的翻译网络,可以将虚拟驾驶模拟器中生成的虚拟场景翻译成真实场景,来进行强化学习训练,取得了更好的泛化能力,并可以迁移学习应用到真实世界中的实际车辆,满足真实世界的自动驾驶要求。
1.前言
强化学习(Reinforcement Learning)是机器学习的一个热门研究方向。强化学习较多的研究情景主要在机器人、游戏与棋牌等方面,自动驾驶的强化学习研究中一大问题是很难在现实场景中进行实车训练。因为强化学习模型需要成千上万次的试错来迭代训练,而真实车辆在路面上很难承受如此多的试错。所以目前主流的关于自动驾驶的强化学习研究都集中在使用虚拟驾驶模拟器来进行代理(Agent)的仿真训练,但这种仿真场景和真实场景有一定的差别,训练出来的模型不能很好地泛化到真实场景中,也不能满足实际的驾驶要求。加州大学伯克利分校的Xinlei Pan等人提出了一种虚拟到现实(Virtual to Real)的翻译网络,可以将虚拟驾驶模拟器中生成的虚拟场景翻译成真实场景,来进行强化学习训练,取得了更好的泛化能力,并可以迁移学习应用到真实世界中的实际车辆,满足真实世界的自动驾驶要求。下面为本文的翻译,编者对文章有一定的概括与删改。
2.简介
强化学习被认为是推动策略学习的一个有前途的方向。然而,在实际环境中进行自动驾驶车辆的强化学习训练涉及到难以负担的试错。更可取的做法是先在虚拟环境中训练,然后再迁移到真实环境中。本文提出了一种新颖的现实翻译网络(Realistic Translation Network),使虚拟环境下训练的模型在真实世界中变得切实可行。提出的网络可以将非真实的虚拟图像输入转换到有相似场景结构的真实图像。以现实的框架为输入,通过强化学习训练的驾驶策略能够很好地适应真实世界的驾驶。实验表明,我们提出的虚拟到现实的强化学习效果很好。据我们所知,这是首次通过强化学习训练的驾驶策略可以适应真实世界驾驶数据的成功案例。
图1 自动驾驶虚拟到现实强化学习的框架。由模拟器(环境)渲染的虚拟图像首先被分割成场景解析的表现形式,然后通过提出的图像翻译网络(VISRI)将其翻译为合成的真实图像。代理(Agent)观察合成的真实图像并执行动作。环境会给Agent奖励。由于Agent是使用可见的近似于真实世界的图像来训练,所以它可以很好地适应现实世界的驾驶。
自动驾驶的目标是使车辆感知它的环境和在没有人参与下的行驶。实现这个目标最重要的任务是学习根据观察到的环境自动输出方向盘、油门、刹车等控制信号的驾驶策略。最直接的想法是端到端的有监督学习,训练一个神经网络模型直接映射视觉输入到动作输出,训练数据被标记为图像-动作对。然而,有监督的方法通常需要大量的数据来训练一个可泛化到不同环境的模型。获得如此大量的数据非常耗费时间且需要大量的人工参与。相比之下,强化学习是通过一种反复试错的方式来学习的,不需要人工的明确监督。最近,由于其在动作规划方面的专门技术,强化学习被认为是一种有前途的学习驾驶策略的技术。
然而,强化学习需要代理(Agent)与环境的相互作用,不符规则的驾驶行为将会发生。在现实世界中训练自动驾驶汽车会对车辆和周围环境造成破坏。因此目前的自动驾驶强化学习研究大多集中于仿真,而不是在现实世界中的训练。一个受过强化学习训练的代理在虚拟世界中可以达到近人的驾驶性能,但它可能不适用于现实世界的驾驶环境,这是因为虚拟仿真环境的视觉外观不同于现实世界的驾驶场景。
虽然虚拟驾驶场景与真实驾驶场景相比具有不同的视觉外观,但它们具有相似的场景解析结构。例如虚拟和真实的驾驶场景可能都有道路、树木、建筑物等,尽管纹理可能有很大的不同。因此将虚拟图像翻译成现实图像是合理的,我们可以得到一个在场景解析结构与目标形象两方面都与真实世界非常相似的仿真环境。最近,生成对抗性网络(GAN)在图像生成方面引起了很多关注。[1]等人的工作提出了一种可以用两个域的配对数据将图像从一个域翻译到另一个域的翻译网络的设想。然而,很难找到驾驶方向的虚拟现实世界配对图像。这使得我们很难将这种方法应用到将虚拟驾驶图像翻译成现实图像的案例中。
本文提出了一个现实翻译网络,帮助在虚拟世界中训练自动驾驶车辆使其完全适应现实世界的驾驶环境。我们提出的框架(如图1所示)将模拟器渲染的虚拟图像转换为真实图像,并用合成的真实图像训练强化学习代理。虽然虚拟和现实的图像有不同的视觉外观,但它们有一个共同的场景解析表现方式(道路、车辆等的分割图)。因此我们可以用将场景解析的表达作为过渡方法将虚拟图像转化为现实图像。这种见解类似于自然语言翻译,语义是不同语言之间的过渡。具体来说,我们的现实翻译网络包括两个模块:第一个是虚拟解析或虚拟分割模块,产生一个对输入虚拟的图像进行场景解析的表示方式。第二个是将场景解析表达方式翻译为真实图像的解析到真实网络。通过现实翻译网络,在真实驾驶数据上学习得到的强化学习模型可以很好地适用于现实世界驾驶。
为了证明我们方法的有效性,我们通过使用现实翻译网络将虚拟图像转化成合成的真实图像并将这些真实图像作为状态输入来训练我们的强化学习模型。我们进一步比较了利用领域随机化(Domain Randomization)的有监督学习和其他强化学习方法。实验结果表明,用翻译的真实图像训练的强化学习模型比只用虚拟输入和使用领域随机化的强化学习模型效果都要更好。
3.自然环境下的强化学习
我们的目标是成功地将一个完全在虚拟环境中训练的驾驶模型应用于真实世界的驾驶挑战。其中一个主要的空白是,代理所观察到的是由模拟器渲染的帧,它们在外观上与真实世界帧不同。因此提出了一种将虚拟帧转换为现实帧的现实翻译网络。受图像-图像翻译网络工作的启发,我们的网络包括两个模块:即虚拟-解析和解析-现实网络。第一个模块将虚拟帧映射到场景解析图像。第二个模块将场景解析转换为与输入虚拟帧具有相似的场景结构的真实帧。这两个模块可以产生保持输入虚拟帧场景解析结构的真实帧。最后我们在通过现实翻译网络获得的真实帧上,运用强化学习的方法,训练了一个自动驾驶代理。我们所采用了[2]等人提出的方法,使用异步的actor-critic强化学习算法在赛车模拟器TORCS[3]中训练了一辆自动驾驶汽车。在这部分,我们首先展现了现实翻译网络,然后讨论了如何在强化学习框架下对驾驶代理进行训练。
图2:虚拟世界图像(左1和左2)和真实世界图像(右1和右2)的图像分割实例
3.1 现实翻译网络:
由于没有配对过的虚拟和真实世界图像,使用[1]的直接映射虚拟世界图像到真实世界图像将是尴尬的。然而由于这两种类型的图像都表达了驾驶场景,我们可以通过场景分析来翻译它们。受[1]的启发,我们的现实翻译网络由两个图像翻译网络组成,第一个图像翻译网络将虚拟图像转化为图像的分割。第二个图像翻译网络将分割后图像转化为现实世界中的对应图像。
由[1]等人提出的图像至图像的翻译网络基本上是一个有条件的生成对抗网络(GAN)。传统的GAN网络和有条件的GAN网络的区别在于,传统GAN网络是学习一种从随机噪声矢量z到输出图像s的映射:G:z → s,而有条件的GAN网络是同时吸收了图像x和噪声向量z,生成另一个图像s:G:{x, z} → s,且s通常与x属于不同的领域(例如将图像翻译成其分割)。
有条件的GAN网络的任务目标可以表达为:
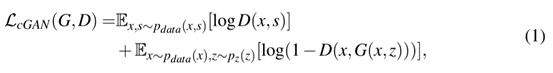
G是试图最小化目标的生成器,D是与G相违背的试图最大化目标的对抗判别器。换句话说,=argmima(G,D),为了抑制模糊,添加了L1的损失正则化,可以表达为
:
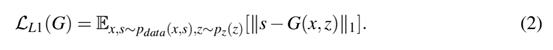
因此,图像-图像翻译网络的总体目标是:
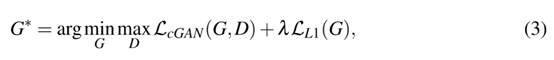
λ是正则化的权重。
我们的网络由两个图像-图像的转换网络组成,这两个网络使用公式(3)作为相同的损失函数。第一个网络将虚拟图像x翻译成它们的分割 s:G1:{x,} → S,第二个网络将分割的图像s转换成它们的现实对应的y: G2:{ s,} → y,,是噪声,以避免确定性的输出。对于GAN神经网络的结构,我们使用的是与[1]相同的生成器和判别器结构。
3.2 训练自主驾驶汽车的强化学习:
我们使用传统的强化学习解决方案异步优势Actor-Arbitor(A3C)来训练自动驾驶汽车,这种方法在多种机器学习任务中表现的很出色。A3C算法是将几种经典的强化学习算法与异步并行线程思想相结合的一种基本的行动Actor-Critic。多个线程与环境的无关副本同时运行,生成它们自己的训练样本序列。这些Actor-learners继续运行,好像他们正在探索未知空间的不同部分。对于一个线程,参数在学习迭代之前同步,完成后更新。A3C算法实现的细节见[2]。为了鼓励代理更快地驾驶和避免碰撞,我们定义了奖励函数为:
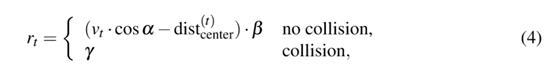
Vt是在第t步时代理的速度(m/s),α是代理的速度方向与轨迹切线之间的轮廓(红色部分),是代理中心和轨迹中点之间的距离,β、γ是常数并在训练的一开始就被定义。我们在训练时设置β=0.006,γ=-0.025。
我们做了两组实验来比较我们的方法和其他强化学习方法以及有监督学习方法的性能。第一组实验涉及真实世界驾驶数据的虚拟到现实的强化学习,第二组实验涉及不同虚拟驾驶环境下的迁移学习。我们实验中使用的虚拟模拟器是TORCS。
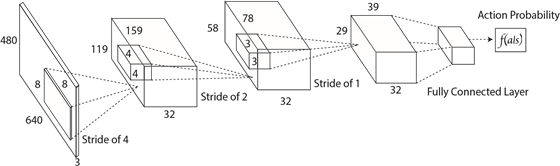
图3:强化学习网络结构。该网络是一个端到端的将状态表示映射到动作概率输出的网络
图4:虚拟到真实图像翻译的例子。奇数列是从TORCS截取的虚拟图像。偶数列是根据左边的虚拟图像相对应合成的真实世界图像。
3.3 真实世界驾驶数据下的虚拟到现实强化学习:
在本实验中,我们用现实翻译网络训练了我们所提出的强化学习模型。我们首先训练虚拟到真实的图像翻译网络然后利用受过训练的网络对模拟器中的虚拟图像进行滤波。这些真实的图像随后被输入A3C算法,以训练驾驶策略。最后经过训练的策略在真实世界驾驶数据上进行了测试,以评估其转向角度预测精度。
为便于比较,我们还训练了一个有监督学习模型来预测每个驾驶测试视频框架的转向角度。该模型是一种具有我们的强化学习模型中相同的策略网络设计结构的深度神经网络(DNN)。网络输入是四个连续框架的序列,网络输出的是动作概率向量,向量中的元素表示直行、左转、右转的概率。有监督学习模型的训练数据不同于用于评价模型性能的测试数据。另外,另一个基线强化学习模型(B-RL))也被训练。B-RL和我们的方法的唯一区别是虚拟世界图像是由代理直接作为状态输入的。B-RL模型也在相同的真实世界驾驶数据上被测试。
数据集:真实世界驾驶视频数据来自[4],这是一个在晴天收集的每一帧都有详细的转角标注的数据集。这个数据集大概有45000张图片,其中15000张被用作训练有监督学习,另外15000张被选出来进行测试。为了训练我们的现实翻译网络,我们从TORCS中的Aalborg环境收集了虚拟图像以及他们的分割。共收集了1673张涵盖了整个Aalborg环境的驾驶照片。
图5:不同环境间的迁移学习。Orcle曾在CGTrac2中接受过训练和测试,所以它的性能是最好的。我们的模型比领域随机化RL方法更有效。领域随机化方法需要在多个虚拟环境中进行培训,这就需要大量的人工的工程工作。
场景分割:我们使用了[5]中的图像语义分割网络设计及其在CityScape图像分割数据集[6]上经过训练的分割网络,从[5]中分割45000张真实世界的驾驶图像。该网络在11个类别的CityScape数据集上训练并迭代了30000次。
图像翻译网络训练:我们使用收集的虚拟-分割图像对和分割-真实图像对训练了虚拟-解析和解析-真实两个网络。如图1所示,翻译网络采用编码-解码器的方式。在图像翻译网络中,我们使用了可以从编码器到解码器跳跃连接两个独立分开层的U-Net体系结构,具有相同的输出特征图形状。生成器的输入尺寸是256×256。每个卷积层有4×4大小的卷积核,步长为2。每一卷积层后都有一个slope为0.2 的LeakyReLU层,每一个反卷积层后都应用一个Relu层。此外,在每一个卷积层与反卷积层后,都应用一个BatchNormalization层。编码器的最终输出与输出尺寸为3×256×256并接着tanh激活函数的卷积层连接。我们用了全部的1673个虚拟-分割图像对来训练一个虚拟-分割网络。因为45000张真实图像有所冗余,我们从45000张图像中选择了1762张图像和它们的分割来训练解析-真实的图像翻译网络。为了训练这个图像翻译模型,我们使用了Adam优化器,初始学习率为0.0002,冲量设为0.5,batchsize设为16,训练了200次迭代直到收敛。
强化训练:我们训练中使用的RL网络结构类似于[2]中的actor网络,是有4个层并且每层间使用Relu激活函数的卷积神经网络(如图3所示)。该网络将4个连续RGB帧作为状态输入并输出9个离散动作,这些动作对应于“直线加速”,“加速向左”、“加速向右”、“直走和刹车”、“向左和刹车”、“向右和刹车”、“向左走”和“向右走”。我们用0.01个异步线程和RMSPop优化器对强化学习代理进行了训练,初始学习率为0.01,γ=0.9,ε=0.1。
评估:真实的驾驶数据集提供了每帧的转向角度注释。然而,在TORCS虚拟环境中执行的动作只包含“左转”,“向右走”,“直走”或它们与“加速”“刹车”的组合。因此我们定义了一个标签映射策略,将转向角度标签翻译成虚拟模拟器中的动作标签。我们把(-10,10)中的转向角度与“直走”的动作联系起来。(由于小转向角度不能在短时间内导致明显的转弯),转向角度小于-10度映射到动作“向左”,转向角度超过10度映射到动作“向右”。通过将我们的方法产生的输出动作与地面真实情况相比较,我们可以获得驾驶动作预测的准确率。
虚拟驾驶环境下的迁移学习:我们进一步进行了另一组实验,并获得了不同虚拟驾驶环境之间的迁移学习的结果。在这个实验中,我们训练了三名强化学习代理。第一个代理在TORCS中的Cg-Track2环境中接受了标准的A3C算法训练,并频繁地在相同的环境中评估其性能。我们有理由认为这种代理的性能是最好,所以我们称之为“Oracle”。第二个代理用我们提出现实翻译网络的强化学习方法来训练。但是,它在TORCS的E-track1环境中接受训练,然后在Cg-track2中进行评估。需要注意的是,E-track1的视觉外观不同于Cg-Track2。第三个代理是用类似于[22]的领域随机化方法训练的,在Cg-track2中,该代理接受了10种不同的虚拟环境的训练,并进行了评估。为了使用我们的方法训练,我们得到了15000张分割图像给E-track1和Cg-track2去训练虚拟-解析和解析-真实的图像翻译网络。图像翻译训练的细节和强化学习的细节与第3.1部分相同。
3.4 结果
图像分割结果:我们使用在Cityscape数据集上训练的图像分割模型来分割虚拟和真实的图像。例子如图2所示。图中表示,尽管原始的虚拟图像和真实的图像看起来很不一样,但它们的场景解析结果非常相似。因此将场景解析作为连接虚拟图像和真实图像的过渡过程是合理的。
现实翻译网络的定性结果:图4显示了我们的图像翻译网络的一些有代表性的结果。奇数列是TORCS中的虚拟图像,偶数列则被翻译成真实的图像。虚拟环境中的图像似乎比被翻译的图像更暗,因为训练翻译网络的真实图像是在晴天截取的。因此我们的模型成功地合成了与原始地面真实图像相类似的真实图像。
强化训练结果:在真实世界驾驶数据上学习到的虚拟-现实的强化学习结果见表1。结果表明,我们提出的方法总体性能优于基线(B-RL)方法,强化学习代理在虚拟环境中接受训练,看不到任何现实的数据。有监督学习方法的整体性能最好。然而,需要用大量的有监督标记数据训练。
表1 三种方法的动作预测准确率

不同虚拟环境下的迁移学习结果见图5。显然,标准A3C(Oracle)在同一环境中训练和测试的性能最好。然而,我们的模型比需要在多个环境中进行训练才能进行泛化的域随机化方法更好。如[7]所述,领域随机化需要大量的工程工作来使其泛化。我们的模型成功地观察了从E-track1到Cg-Track2的翻译图像,这意味着,该模型已经在一个看起来与测试环境非常相似的环境中进行了训练,从而性能有所提高。
4总结
我们通过实验证明,利用合成图像作为强化学习的训练数据,代理在真实环境中的泛化能力比单纯的虚拟数据训练或领域随机化训练更好。下一步将是设计一个更好的图像-图像翻译网络和一个更好的强化学习框架,以超越有监督学习的表现。
由于场景解析的桥梁,虚拟图像可以在保持图像结构的同时被翻译为真实的图像。在现实框架上学习的强化学习模型可以很容易地应用于现实环境中。我们同时注意到分割图的翻译结果不是唯一的。例如,分割图指示一辆汽车,但它不指定该汽车的颜色。因此,我们未来的工作之一是让解析-真实网络的输出呈现多种可能的外观(比如颜色,质地等)。这样,强化学习训练中的偏差会大幅度减少。
我们第一个提供了例子,通过与我们提出的图像-分割-图像框架合成的真实环境交互,训练驾驶汽车强化学习算法。通过使用强化学习训练方法,我们可以得到一辆能置身于现实世界中的自动驾驶车辆。
5.参考文献
[1]Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-imagetranslation with conditional adversarial networks. CoRR, abs/1611.07004, 2016.URL http://arxiv.org/abs/1611.07004.
[2]Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, AlexGraves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu.Asynchronous methods for deep reinforcement learning. CoRR, abs/1602.01783,2016. URL http: //arxiv.org/abs/1602.01783.
[3]Bernhard Wymann, Eric Espié, Christophe Guionneau, ChristosDimitrakakis, Rémi Coulom,and Andrew Sumner. Torcs, the open racing car simulator.Software available at http://torcs. sourceforge. net, 2000.
[4]Sully Chen. Autopilot-tensorflow,2016. URL https://github.com/ SullyChen/Autopilot-TensorFlow.
[5] VijayBadrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutionalencoder-decoder architecture for image segmentation. arXiv preprintarXiv:1511.00561, 2015.
[6]MariusCordts,Mohamed Omran,Sebastian Ramos,Timo Rehfeld,Markus Enzweiler, RodrigoBenenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes datasetfor semantic urban scene understanding. CoRR, abs/1604.01685, 2016. URL http://arxiv.org/abs/1604.01685.
[7]Fereshteh Sadeghi and Sergey Levine. (cad)$ˆ2$rl: Real single-image flightwithout a single real image. CoRR,abs/1611.04201, 2016. URL http://arxiv.org/abs/1611.04201.
-
自动驾驶
+关注
关注
794文章
14979浏览量
181395 -
强化学习
+关注
关注
4文章
273浏览量
11996
原文标题:自动驾驶中虚拟到现实的强化学习
文章出处:【微信号:IV_Technology,微信公众号:智车科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
大模型时代自动驾驶标注有什么特殊要求?

自动驾驶中常提的占用网络检测存在哪些问题?
自动驾驶端到端为什么会出现黑盒现象?

端到端与模块化自动驾驶的数据标注要求有何不同?
L3级自动驾驶在技术上有什么不一样的要求?
自动驾驶仿真测试有什么具体要求?

自动驾驶端到端大模型为什么会有不确定性?
端到端自动驾驶相较传统自动驾驶到底有何提升?
自动驾驶测试有哪些要求规范?

低速自动驾驶与乘用车自动驾驶在技术要求上有何不同?

为什么自动驾驶端到端大模型有黑盒特性?

卡车、矿车的自动驾驶和乘用车的自动驾驶在技术要求上有何不同?
新能源车软件单元测试深度解析:自动驾驶系统视角




评论