 流行基线基础问题迟迟没能解决,让模型学会阅读理解究竟需要多少文本
流行基线基础问题迟迟没能解决,让模型学会阅读理解究竟需要多少文本
编者按:今天,卡内基梅隆大学助理教授Zachary C. Lipton推荐了自己的一个有趣研究:让模型学会阅读理解究竟需要多少文本。在之前的ICML 2018研讨会上,他和斯坦福大学研究生Jacob Steinhardt曾撰文痛批学界“歪风”,在学界引起巨大反响。其中提到的一个弊端就是有些学者会对“进步”错误归因,把调参获得的性能改善强加到架构调整上。结合这篇论文,也许他的研究能让我们获得一些见解。
摘要
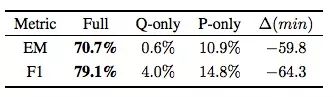
近期,学界发表了不少有关阅读理解的论文,它们使用的样本都是(问题、段落、答案)这样的三元组。对此,一种常规的想法是,如果模型的目标是预测相应答案,它们就必须结合来自问题和段落的信息。这是个很有趣的点,但考虑到现在有数百篇已发表的论文正在争夺排行榜第一的宝座,围绕这些流行基线的基础问题还是迟迟没能得到解决。
在本文中,我们为bAbI、SQuAD、CBT、CNN和Whodid-What数据集构建了合理的基线,发现如果样本中只包含纯问题或纯段落,模型的表现通常会很好。用纯段落样本进行训练后,模型在14个bAbI问题上取得了高于50%的准确率(一共20个),其中部分结果甚至可以媲美正常模型。
另外,我们也发现了一个奇怪的点:在CBT任务中,研究人员通常会用一个问题和一个包含前20个句子的段落预测第21个句子中的缺失词,但实验证实,模型可能只需第21句话就能完成预测。相比之下,CNN和SQuAD这两个数据集似乎构造得很好。
数据集&基线

实验结果
bAbI任务
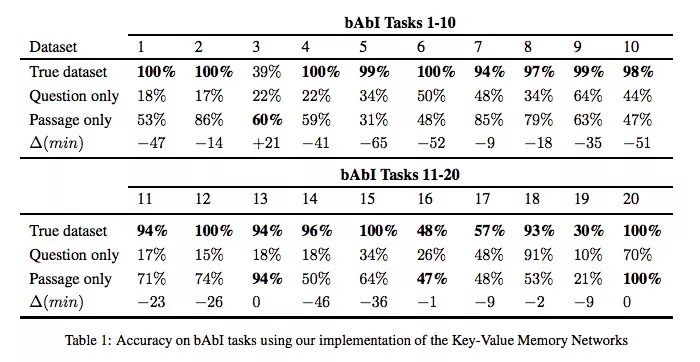
下表是基线KV-MemNet在bAbI数据集上的具体表现,第一行使用的是常规样本,包含问题和段落;第二行只使用问题;第三行只使用段落。可以发现,在第2,7,13,20个问题中,用段落训练的模型性能惊人,准确率在80%以上。在第3,13,16和20个问题中,它的准确率甚至超过了使用常规样本的模型。而在第18个问题中,用问题训练的模型的准确率也达到了91%,和正常的93%非常接近。
这个发现给我们的启示是,bAbI的某些问题可能并没有我们想象中那么复杂。
CBT任务
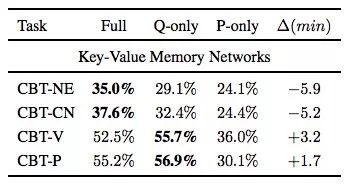
CBT任务的“答案”根据词性可分为命名实体(NE)、公共名词(CN)、动词(V)、介词(P)四类,由于后两种根据上下文就能预测,通常我们在阅读理解问题里会更重视前两种词性。
同样是基线KV-MemNet,如下表所示,这次使用的三类样本成了三列:如果是预测NE和CN,使用完整样本训练的模型准确率更高,但用了问题的模型和它也很接近;如果是预测V和P,只用问题训练效果更佳。
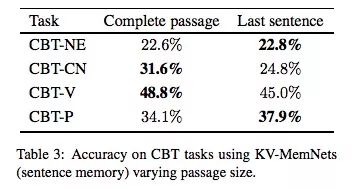
那么如果把“段落”从前20个句子改成第21句呢?下表是只用“段落”的实验结果,可以发现,用最后一句效果更好,也就是说,它和正常模型的性能更接近。
CNN任务
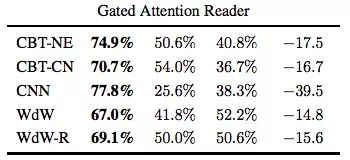
在这里,Gated Attention Reader在CNN任务上的准确率就差距较大了。这种下降可能是因为实体匿名化导致模型无法构建特定于实体的信息。
SQuAD任务
这个结果表明,SQuAD这个数据集针对阅读理解任务做了精心设计,它最具挑战性。
讨论
从实验数据可知,虽然同属阅读理解任务,但这些数据集存在不同的缺陷,也有各种漏洞可以钻。下面是我们为评估新的基线和算法设想的一些指导原则。这不是在指责以前的数据集制作者,相反地,这些纰漏能为未来的研究提供不小的价值。
提供严格的RC基线:已发布的RC数据集应包含表明任务难度的合理基线,尤其是它们所需的“问题”“段落”信息量,如果没有这些标准,我们就无法知道模型进步究竟取决于什么。
测试完整信息的必要性:在需要“问题”信息和“段落”信息的问题中,有时候真正起作用的只是部分信息。就像CBT任务,虽然只有二十几句话,但是我们用最后一句话就能训练媲美正常性能的模型。每个模型究竟需要多少信息量,这是研究人员应该标明的。
使用完型填空式的RC数据集时,保持谨慎:这类数据集通常是由程序批量制造的,很少有人参与。如果用它们训练模型,我们会找不到目前技术的局限,也排查不了。
此外,各类会议在推荐收录论文的数据集时,也应更注重严谨性,而不是只看创新性。
-
模型
+关注
关注
1文章
3406浏览量
49457 -
基线
+关注
关注
0文章
12浏览量
8005
原文标题:基线调研:让模型学会阅读理解需要多少信息?
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【《大语言模型应用指南》阅读体验】+ 俯瞰全书
【《大语言模型应用指南》阅读体验】+ 基础篇
【「大模型启示录」阅读体验】对本书的初印象
基于LabVIEW的文本(txt)阅读器
基于文本摘要和引用关系的可视辅助文献阅读系统
机器阅读理解的含义以及如何工作

剥开机器阅读理解的神秘外衣
如果把中学生的英语阅读理解选择题让AI来做,会做出什么水平?
一种基于多任务联合训练的阅读理解模型

基于LSTM的表示学习-文本分类模型
深度揭秘工字电感究竟需要测量哪些参数的好坏






 工商网监
工商网监
评论