 PolygonRNN++自动标注使用CNN提取图像特征
PolygonRNN++自动标注使用CNN提取图像特征
标注图像中的物体掩码是一项非常耗时耗力的工作(人工标注一个物体平均需要20到30秒),但在众多计算机视觉应用中(例如,自动驾驶、医学影像),它又是不可或缺的。而现有的自动标注软件,大多基于像素,因此不够智能,特别是在颜色接近的相邻物体上表现不好。有鉴于此,多伦多大学的研究人员Lluís Castrejón等提出了Polygon-RNN标注系统,获CVPR 2017最佳论文提名。多伦多大学的研究人员David Acuna、Huan Ling、 Amlan Kar等又在CVPR 2018提交了PolygonRNN++,Polygon-RNN的改进版本,并于近日发布了PyTorch实现。
Polygon-RNN++架构
Polygon-RNN整体架构如下图所示:
和之前的Polygon-RNN类似,Polygon-RNN++使用了CNN(卷积神经网络)提取图像特征,然后使用RNN(循环神经网络)解码多边形顶点。为了提高RNN的预测效果,加入了注意力机制(attention),同时使用评估网络(evaluator network)从RNN提议的候选多边形中选出最佳。最后使用门控图神经网络(Gated Graph Neural Network,GGNN)上采样,以提高输出分辨率。
CNN部分,借鉴了ResNet-50的做法,减少步长(stride),引入空洞卷积(dilation),从而在不降低单个神经元感受野(receptive field)的前提下,放大输入特征映射。此外还引入了跳跃连接(skip connection),以便同时捕捉边角等低层细节和高层语义信息。剩下的配置都是比较常规的,包括3x3卷积核、组归一化(batch normalization)、ReLU、最大池化(max-pooling)等。
蓝色张量传给GNN,橙色张量传给RNN
RNN部分,使用了双层ConvLTSM(3x3核,64/16通道,每时步应用组归一化),以保留空间信息、降低参数数量。网络的输出为(D x D) + 1元素的独热编码。前D x D维表示可能的顶点位置(论文的试验中D = 28),而最后一个维度标志多边形的终点。
为了提升RNN部分的表现,加入了注意力机制。具体来说,在时步t,计算加权特征映射:
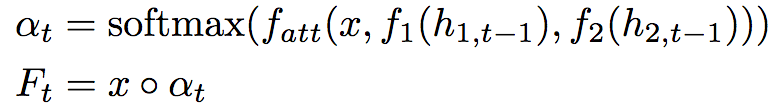
上式中,x为跳跃特征张量,h为隐藏状态张量,f1、f2使用一个全连接层将h1,t、h2,t映射至RDxDx128。fatt累加输入之和,通过一个全连接层将其映射至DxD。◦为哈达玛积(Hadamard product)。直观地说,注意力机制使用之前的RNN隐藏状态控制图像特征映射中的特定位置,使RNN在下一时步仅仅关注相关信息。
另外,第一个顶点需要特别处理。因为,给定多边形之前的顶点和一个隐式的方向,下一个顶点的位置总是确定的,除了第一个顶点。因此,研究人员增加了一个包含两个DxD维网络层的分支,让第一层预测边,第二层预测顶点。测试时,第一个顶点取样自该分支的最后一层。
第一个顶点的选择很关键,特别是在有遮挡的情况下。传统的集束搜索基于对数概率,因此不适用于Polygon-RNN++(在遮挡边界上的点一般在预测时会有很高的对数概率,减少了它被集束搜索移除的机会)。因此,Polygon-RNN++使用了一个由两个3x3卷积层加上一个全连接层组成的评估网络:
该评估网络是单独训练的,通过训练最小化均方误差:
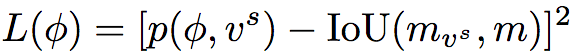
上式中,p为网络的预测IoU,mvs和m分别为预测掩码、实际掩码。
在测试时,基于评分前K的第一个顶点预测通过经典集束搜索(对数概率,束宽为B)生成多边形。对应K个第一个顶点,共有K个多边形,然后让评估网络从中选出最优多边形。在论文的试验中,K = 5. 之所以首先使用集束搜索,而不是完全使用评估网络,是因为后者会导致推理时间过长。在B = K = 1的设定下,结合集束搜索和评估网络的配置,可以达到295ms每物体的速度(Titan XP)。
与人交互时,人工纠正会传回模型,让模型重新预测多边形的剩余顶点。
如前所述,RNN输出的D x D维的多边形,D取28. 之所以不取更大的D,是为了避免超出内存的限制。为了增加最终的输出分辨率,Polygon-RNN++使用了门控图神经网络进行上采样,将顶点视作图的节点,并在相邻节点中间增加节点。
GGNN定义了一个传播模型,将RNN推广至任意图,可以在每个节点上生成输出前有效地传播信息。
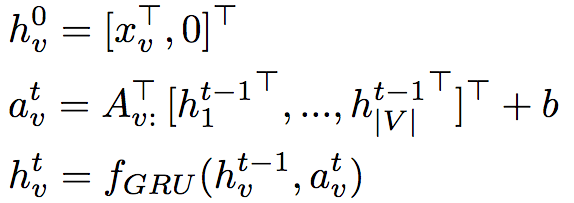
上式中,V为图的节点集,xv为节点v的初始状态,hvt为节点v在时步t的隐藏状态。矩阵A ∈ R|V|x2N|V|决定节点如何互相传递信息,其中N表示边的类型数。在试验中使用了256维GRU,传播步数T = 5。
节点v的输出定义为:
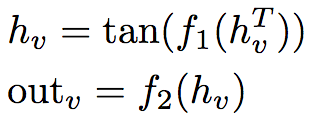
f1和f2为MLP(多层感知器),试验中的大小分别为256 x 256、256 x 15 x 15.
如前所述,CNN部分112 x 112 x 256的特征映射(蓝色张量)传给GGNN。在图中的每个节点v周围(拉伸后),提取一个S x S块,得到向量xv,提供给GGNN。在传播过程之后,预测节点v的输出,即D' x D'空间网格上的位置。该网格以原位置(vx, vy)为参照,因此该预测任务其实是一个相对放置问题,并且可以视作分类问题,并基于交叉熵损失训练。训练的标准答案(ground truth)为RNN部分的输出,如果预测和标准答案中的节点的差异超过阈值(试验中为3格),则视为错误。
在试验中,研究人员令S = 1,D' = 112(研究人员发现更大的D'不能改善结果)。
基于强化学习训练
Polygon-RNN基于交叉熵训练。然而,基于交叉熵训练有两大局限:
MLE过度惩罚了模型。比如,预测的顶点虽然不是实际多边形的顶点,但在实际多边形的边上。
优化的测度和最终评估测度(例如IoU)大不一样。
另外,训练过程中传入下一时步的是实际多边形而不是模型预测,这可能引入偏差,导致训练和测试的不匹配。
为了缓解这些问题,Polygon-RNN++只在初始阶段使用MLE训练,之后通过强化学习训练。因为使用强化学习,IoU不可微不再是问题了。
在强化学习的语境下,Polygon-RNN++的RNN解码器可以视作序列决策智能体。CNN和RNN架构的参数θ定义了选择下一个顶点vt的策略pθ。在序列结束后,我们得到奖励r = IoU(mask(vs, m))。因此,最大化奖励的损失函数为:
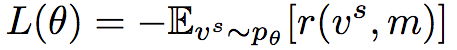
相应地,损失函数的梯度为:
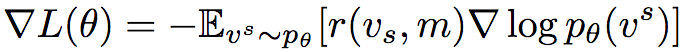
实践中常采用蒙特卡洛采样计算期望梯度。但是这一方法方差很大,而且在未经恰当地基于情境归一化的情况下非常不稳定。因此,Polygon-RNN++采用了自我批判(self-critical)方法,使用模型的测试阶段推理奖励作为基线:
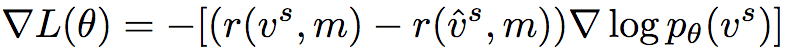
另外,为了控制模型探索的随机性,Polygon-RNN++还在策略softmax中引入了温度参数τ。试验中,τ = 0.6.
试验结果
下图展示了Polygon-RNN++在Cityscapes数据集上的结果。Cityscapes包含2975/500/1525张训练/验证/测试图像,共计8个语义分类。
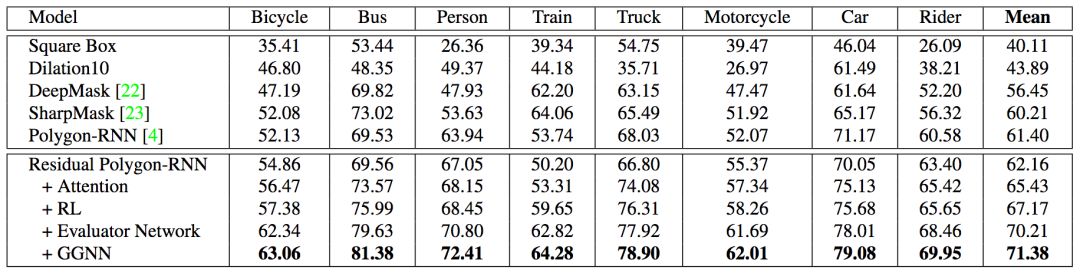
可以看到,在各个分类上,Polygon-RNN++都超越了其他模型,并且高于其中表现最好的模型差不多10%的IoU。事实上,在汽车(cars)分类上,Polygon-RNN++(79.08)战胜了人类(78.60)。而消融测试的结果也令人满意。
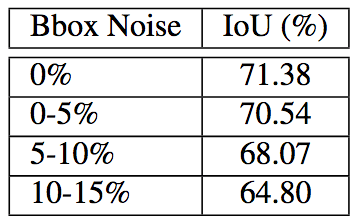
另外,Polygon-RNN++对噪声的鲁棒性良好:
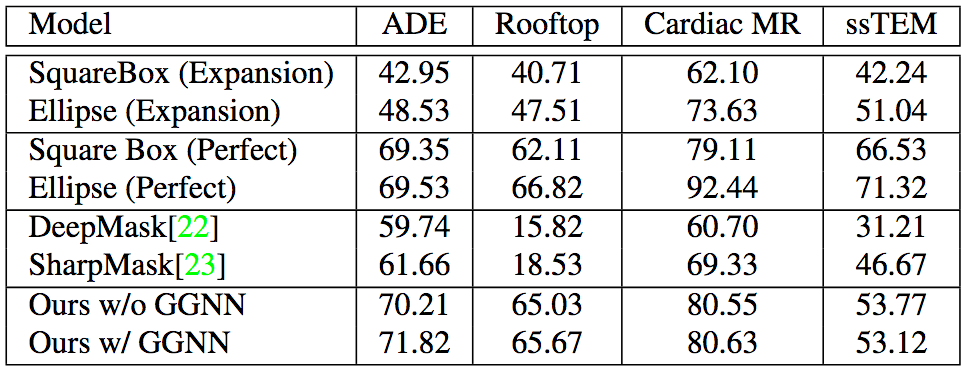
Polygon-RNN++在跨领域的数据集上表现同样出色,这说明Polygon-RNN++的概括性很好。
-
cnn
+关注
关注
3文章
351浏览量
22168 -
pytorch
+关注
关注
2文章
803浏览量
13142
原文标题:Polygon-RNN++图像分割数据集自动标注
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
蠕虫病毒特征码自动提取原理与设计

井壁图像上平面地质特征的自动提取
基于隐马尔科夫模型和卷积神经网络的图像标注方法
基于特征交换的卷积神经网络图像分类算法






 工商网监
工商网监
评论