 强化学习“好奇心”模型:训练无需外部奖励,全靠自己
强化学习“好奇心”模型:训练无需外部奖励,全靠自己
强化学习模型往往依赖对外部奖励机制的精心设计,在模型训练成本控制和可扩展性上都存在局限。OpenAI的研究人员提出一种新的强化学习模型训练方式,以agent的“好奇心”作为内在奖励函数,在训练中无需外部奖励,泛化性好,经过54种环境测试,效果拔群。
强化学习模型在很大程度上依赖于对agent的外在环境奖励的精心设计。然而,用手工设计的密集奖励来对每个环境进行标记的方式是不可扩展的,这就需要开发agent所固有的奖励函数。好奇心就是一种内在的奖励函数,它使用预测误差作为奖励信号。
在本文中,我们首次在54个标准基准测试环境(包括一系列Atari游戏)中进行了纯粹基于好奇心驱动学习的大规模研究,不设置任何外在奖励。得到的结果令人惊喜,而且表明内在的好奇心目标奖励与许多游戏环境中手工设计的外在奖励机制之间存在高度的一致性。
强化学习“好奇心”模型:训练无需外部奖励,全靠自己
我们研究了使用不同的特征空间来计算预测误差的效果,并表明,随机特征对于许多流行的强化学习游戏的基准测试来说已经足够,但是已学习过的特征看起来似乎具备更高的泛化性。(比如可以迁移至《超级马里奥兄弟》的新关卡中)。
我们对agent进行了大规模的实证研究,这些agent纯粹通过各种模拟环境中的内在奖励来驱动,这还是业界首次。特别是,我们选择基于动力学的内在奖励的好奇心模型。因为该模型具有很强的可扩展性和可并行性,因此非常适合大规模实验使用。
图1:本文研究中使用的54种环境的快照截图集合。我们的研究表明,agent能够只凭借好奇心,在没有外部奖励或结束信号的情况下取得进步。
相关视频、结果、代码和模型,见https://pathak22.github.io/large-scale-curiosity
我们的思路是,将内在奖励表示为预测agent在当前状态下的行为后果时出现的错误,即agent学习的前向动态的预测误差。我们彻底调查了54种环境中基于动力学的好奇心:这些场景包括视频游戏、物理引擎模拟和虚拟3D导航任务等,如图1所示。
为了更好地理解好奇心驱动的学习,我们进一步研究了决定其表现的关键因素。对高维原始观察空间(如图像)中的未来状态进行预测是一个极具挑战性的问题,对辅助特征空间中的动态进行学习可以改善结果。
但是,如何选择这样一个嵌入空间是一个关键、未解决的研究问题。通过对系统的简化,我们研究了用不同的方法对agent观察到的信息进行编码的作用,使得agent可以完全靠自身的好奇心机制做出良好的表现。
上图是8种选定的Atari游戏和《超级马里奥兄弟》的特征学习方法的比较。图中的评估曲线显示agent纯粹通过好奇心训练,在没有外部奖励和关卡结束信号的情况下,获得的平均奖励分数(包括标准误差)。
我们看到,纯粹以好奇心驱动的agent能够在这些环境中收集奖励,而无需在训练中使用任何外部奖励。
图3:左:采用不同批规模的RF训练方法的比较,训练没有使用外在奖励。中:Juggling(Roboschool)环境中的球弹跳次数。 右:多人游戏Pong环境下的平均关卡长度
为了确保动态的稳定在线训练,我们认为所需的嵌入空间应该:(1)在维度方面紧凑,(2)能够保存观测到的足够信息,(3)是基于观测信息的固定函数。
图4:《超级马里奥兄弟》游戏环境下的泛化实验。 左图所示为1-1关到1-2关的迁移结果,右图为1-1关到1-3关的迁移结果。下方为源环境到目标环境的映射。 所有agent都的训练过程中都没有外在奖励。
图5:在使用终端外部奖励+好奇心奖励进行组合训练时,Unity环境下的平均外在奖励。 注意,只通过外部奖励进行训练的曲线值始终为零(表现为图中最底部的直线)
我们的研究表明,通过随机网络对观察结果进行编码是一种简单有效的技术,可以用于在许多流行的强化学习基准测试中建立好奇心模型。这可能表明,许多流行的强化学习视频游戏测试并不像通常认为的那样,在视觉上有那么高的复杂度。
有趣的是,虽然随机特征对于许多流行的强化学习游戏的基准测试来说已经足够了,但是已学习过的特征看起来似乎具备更高的可推广性(比如推广至《超级马里奥兄弟》的新关卡中)。
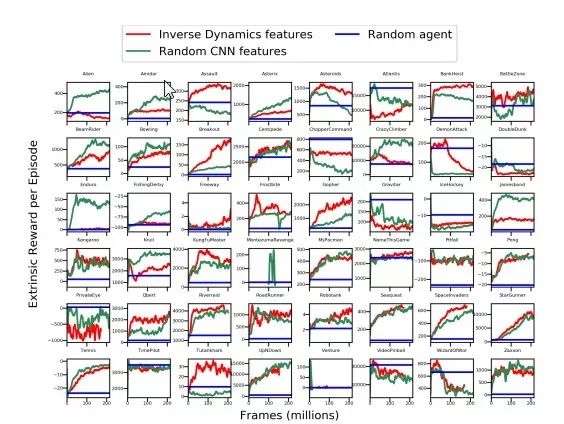
上图给出了所有Atari游戏环境下的表现结果。我们发现,用像素训练的好奇心模型在任何环境中都表现不好,并且VAE特征的表现也不比随机特征及逆动力学特征更好,甚至有时还更差。
此外,在55%的Atari游戏中,逆动态训练特征比随机特征的表现更好。分析表明,对好奇心进行建模的随机特征是一个简单而强大的基线标准,并且可能在一半的Atari游戏场景中表现良好。
小结
(1)我们对各种环境下的好奇心驱动模型进行了大规模的研究,这些场景包括:Atari游戏集、《超级马里奥兄弟》游戏、Unity中的虚拟3D导航、Roboschool 环境等。
(2)我们广泛研究了用于学习基于动力学的好奇心的不同特征空间,包括随机特征,像素,反向动力学和变分自动编码器,并评估这些空间在不可视环境下的可推广性。
(3)局限性:我们观察到,如果agent本身就是环境中随机性的来源,它可以在未取得任何实际进展的情况下进行自我奖励。我们在3D导航任务中凭经验证明了这一局限性,在这类任务中,agent能够控制环境的各个不同部分。
未来方向
我们提出了一种简单且可扩展的方法,可以在不同的环境中学习非平凡的行为,而无需任何奖励函数或结束信号。本文的一个令人惊讶的发现是随机特征表现不错,但已学习的特征似乎在可泛化性上更胜一筹。我们认为一旦环境足够复杂,对特征的学习将变得更加重要,不过我们决定将这个问题留给未来。
我们更高的目标是,能够利用许多未标记的(即没有事先设计的奖励函数)环境来改善面向感兴趣的任务的性能。有鉴于此,在具备通用奖励函数的环境中展示出很好的表现只是我们研究的第一步,未来的成果可能包括实现从未标记环境到标记环境的迁移。
-
Agent
+关注
关注
0文章
111浏览量
26850 -
强化学习
+关注
关注
4文章
268浏览量
11323
原文标题:强化学习下一步:OpenAI伯克利让AI纯凭“好奇心”学习!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Microchip Technology的好奇心板的新设计
深度强化学习实战
深度强化学习是什么?有什么优点?
机器人拥有好奇心会让机器人变得更加聪明
机器学习中的无模型强化学习算法及研究综述


强化学习的基础知识和6种基本算法解释
彻底改变算法交易:强化学习的力量
ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2

强化学习的基础知识和6种基本算法解释

石墨烯之父——安德烈·海姆,好奇心驱使下的幽默大师和创新者

Victor Labián Carro:以好奇心成就 RISC-V 职业成功之路






 工商网监
工商网监
评论