 基于Featuretools Python库来实现特征工程自动化的实例
基于Featuretools Python库来实现特征工程自动化的实例
【导读】如今机器学习正在从人工设计模型更多地转移到自动优化工作流中,如 H20、TPOT 和 auto-sklearn 等工具已被广泛使用。这些库以及随机搜索等方法都致力于寻找最适合数据集的模型,以此简化模型筛选与调优过程,而不需要任何人工干预。然而,特征工程作为机器学习过程中最有价值的一个环节,却几乎一直由人工来完成。
在本文中,我们通过引用一个数据集作为例子来给大家介绍基础知识,并给大家介绍一个基于 Featuretools Python 库来实现特征工程自动化的实例。
前言
特征工程也可以称作特征构造,是基于现有数据构造新特征来训练机器学习模型的过程。可以说这个环节比我们具体使用什么模型更重要,因为机器学习算法只会基于我们提供给它的数据进行学习,所以构造与目标任务相关的特征是极其重要的(详见论文「A Few Useful Things to Know about Machine Learning」)。
论文链接:
https://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf
一般来说,特征工程是一个漫长的人工过程,依赖于领域知识、直觉及数据操作。这一过程是极其单调的,而且最终的特征结果会受人的主观性和时间所限制。自动特征工程旨在帮助数据科学家基于数据集自动地构造候选特征,并从中挑选出最适合于训练的特征。
特征工程基础知识
特征工程意味着基于现有数据构造额外的特征,这些待分析的数据往往分布在多张相关联的表中。特征工程需要从数据中提取信息,然后将其整合成一张单独的表用来训练机器学习模型。
特征构造是一个非常耗时的过程,因为每个新特征都需要经过几个步骤去构造,特别是那些需要用到多张表信息的特征。我们可以把这些特征构造的操作合起来,分成两个类:“转换(transformation)”和“聚合(aggregation)”。下面我们通过几个例子来理解一下这些概念。
“转换”适用于单张表格,这个环节基于一个或多个现有数据列构造新的特征。例如,现在我们有下面这张客户数据表:
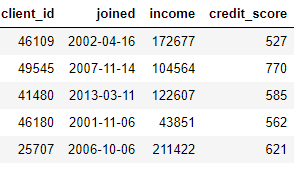
我们可以通过查找 joined 列的月份或对 income 列取自然对数来构造新特征。这些都属于“转换”操作,因为它们都只用了来自一张表的信息。
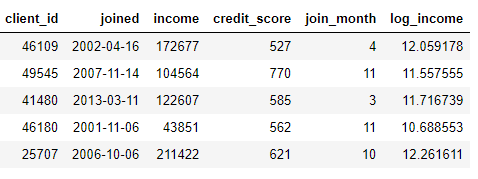
另一方面,“聚合”是需要进行跨表操作的,并且要基于一对多的关系来把观测值分组,然后进行数据统计。例如,如果我们有另一张关于客户贷款信息的表格,其中每位客户可能有多笔贷款,那么我们就可以计算每位客户贷款额的平均值、最大值和最小值等统计量了。
这一过程包括根据不同用户对贷款数据表进行分组,计算聚合后的统计量,然后把结果整合到客户数据中。以下是我们在 Python 中用 Pandas 执行此过程的代码:
importpandasaspd#Grouploansbyclientidandcalculatemean,max,minofloansstats=loans.groupby('client_id')['loan_amount'].agg(['mean','max','min'])stats.columns=['mean_loan_amount','max_loan_amount','min_loan_amount']#Mergewiththeclientsdataframestats=clients.merge(stats,left_on='client_id',right_index=True,how='left')stats.head(10)
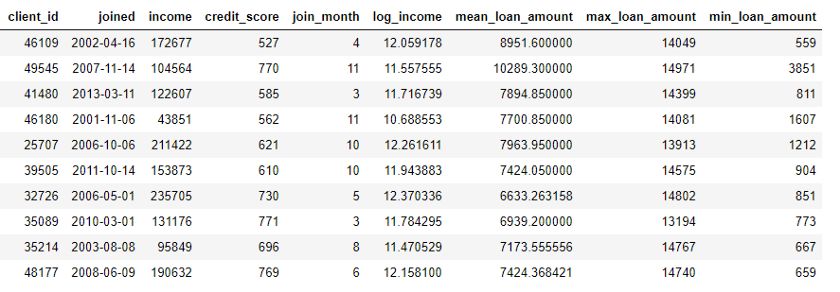
这些操作本身并不难,但如果我们有上百个变量,它们分布在几十张表中,若要手动完成这一过程就比较困难了。理想情况下,我们想找到一个解决方案,可以自动执行多个表的转换和聚合,并将结果数据整合到一张表中。虽然 Pandas 是非常棒的资源,但需要我们手动完成的数据操作工作量仍非常巨大!
▌特征工具(Featuretools)
幸运的是,特征工具正是我们在找的解决方案。这个开源的 Python 库可以基于一组相关的表自动创建特征。特征工具以“深度特征合成(Deep Feature Synthesis,简称 DFS)”为基础,这个方法听起来比它本身要高级很多(之所以叫“深度特征合成”,不是因为使用了深度学习,而是叠加了多重特征)。
深度特征合成叠加了多重转换和聚合操作,这在特征工具词库中被称作特征基元 (feature primitives),用于通过多张表的数据来构造特征。和机器学习中的大多数方法一样,这是一个以简单概念为基础的复杂方法。通过每次学习一个构造块,我们就可以很好地理解这个强大的方法。
首先,我们来看一下例子中的数据。我们已经看到上面提到的部分数据集,全部的表如下所示:
clients:关于一家信用社客户的基本信息。每位客户只对应表中的一行数据。
loans:客户名下的贷款。每笔贷款只对应表中的一行数据,但每位客户名下可能有多笔贷款。
payments:还贷金额。每笔支付只对应一行数据,但每项贷款可能分多次支付。
如果我们有一个机器学习任务,比如预测某位客户是否会还清未来的一笔贷款,我们需要把有关客户的所有信息都整合到一张表中。这些表通过变量 client_id 和 loan_id 相互关联,我们可以用一系列转换和聚合来手动完成这一过程。然而我们很快就会发现,我们可以使用特征工具来将这个过程自动化。
▌实体与实体集
首先要介绍特征工具的两个概念:实体 (entity) 和实体集 (entityset)。简单来说,一个实体就是一张表(即 Pandas 中的一个 DataFrame)。一个实体集是指多个表的集合以及它们之间的相互关系。我们可以把实体集看作一种 Python 的数据结构,且有其专属的方法和属性。
我们可以在特征工具中创建一个空的实体集,如下所示:
importfeaturetoolsasft#Createnewentitysetes=ft.EntitySet(id='clients')
现在我们要把多个实体进行合并。每个实体必须带有一个索引,即所有元素都唯一的数据列。也就是说,索引列中的每个值在表中只能出现一次。
clients 数据框(dataframe)的索引是 client_id,因为每位客户都只对应表中的一行数据。我们可以通过如下语法把一个带有索引的实体加入一个实体集:
#Createanentityfromtheclientdataframe#Thisdataframealreadyhasanindexandatimeindexes=es.entity_from_dataframe(entity_id='clients',dataframe=clients,index='client_id',time_index='joined')
loans 数据框也有唯一索引 loan_id,将其加入实体集的语法和处理 clients 的语法相同。然而,payments 数据框中没有唯一的索引。若我们想把这个实体加入实体集,则需要让 make_index = True,并指定一个索引名。虽然特征工具可以自动推断实体中每一列的数据类型,但我们也可以通过把数据类型字典传入参数 variable_types 来将其覆盖。
#Createanentityfromthepaymentsdataframe#Thisdoesnotyethaveauniqueindexes=es.entity_from_dataframe(entity_id='payments',dataframe=payments,variable_types={'missed':ft.variable_types.Categorical},make_index=True,index='payment_id',time_index='payment_date')
对于这个数据框,虽然 missed 是整数,但并不是数值变量,因为它只能取两个离散值,所以我们让特征工具将其当作一个类别变量处理。将数据框全部加入实体集后,我们看到:
根据我们指定的修正方案,这些列的类型都被正确识别了。下一步,我们需要指定实体集中各个表之间的关联。
▌表之间的关联
研究两表之间关系的最好方法是与父子关系进行类比。这是一种一对多的关系:每位父亲可能有多个孩子。从表的角度来看,父表中的每一行对应一位父亲,但子表可能有多行数据,就像同一位父亲的多个孩子。
例如,在我们的数据集中,clients 是 loans 的父表。每位客户只对应 clients 表中的一行数据,但可能对应 loans 表中的多行数据。同样,loans 是 payments 的父表,因为每笔贷款可能包含多笔支付。父表通过共有的变量与子表相连接。当执行聚合操作时,我们根据父表的变量对子表进行归类,并计算每个子表的统计量。
若要标明特征工具中的关联,我们只需指定连接两张表的变量。表 clients 和表 loans 是通过变量 client_id 相关联的,表 loans 和表 payments 通过 loan_id 相关联。可通过如下语法创建关联并将其加入实体集:
#Relationshipbetweenclientsandpreviousloansr_client_previous=ft.Relationship(es['clients']['client_id'],es['loans']['client_id'])#Addtherelationshiptotheentitysetes=es.add_relationship(r_client_previous)#Relationshipbetweenpreviousloansandpreviouspaymentsr_payments=ft.Relationship(es['loans']['loan_id'],es['payments']['loan_id'])#Addtherelationshiptotheentitysetes=es.add_relationship(r_payments)es
该实体集现在包括三个实体以及连接这些实体之间的关系。加入实体并标明关联后,我们的实体集就完整了,并做好了构造新特征的准备。
▌特征基元
在正式进行深度特征合成之前,我们需要理解特征基元这个概念。我们已经知道了特征基元是什么,但也只是了解用什么名字来称呼它们。下面是我们构造新特征时的基本操作:
聚合:基于父表与子表的关联(一对多)完成的系列操作,即根据父表对子表进行分组并计算其统计量。例如,根据 client_id 对 loan 表进行分组,并找到每位客户最大的贷款数额。
转换:对一张表中一列或多列进行的操作。例如,计算一张表中两列的差值或计算一列的绝对值。
在特征工具中,我们可以通过单个基元或者叠加多个基元来构造新特征。下面是特征工具中一些特征基元的列表(我们也可以自定义基元):
▌特征基元
这些基元可以拿来单独使用或者结合起来构造新的特征。根据特定的基元,我们可以使用 ft.dfs 函数(即深度特征合成)来构造特征。我们将所选的 trans_primitives(转换)和 agg_primitives(聚合)传入 entityset(实体集)和 target_entity(目标实体),即我们想要添加特征的表:
#Createnewfeaturesusingspecifiedprimitivesfeatures,feature_names=ft.dfs(entityset=es,target_entity='clients',agg_primitives=['mean','max','percent_true','last'],trans_primitives=['years','month','subtract','divide'])
得到的结果是一个含有新特征的客户数据框(因为我们把用户当作了 target_entity)。例如,若我们知道每位用户加入的月份,这可以作为一个转换特征基元:
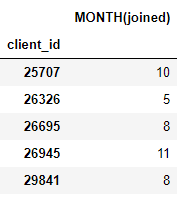
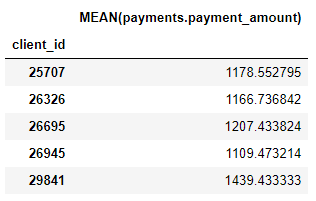
我们也有许多聚合基元,如每位客户的平均支付额:
虽然我们只列举了一部分特征基元,但实际上特征工具通过结合与叠加这些基元构造了许多新的特征。
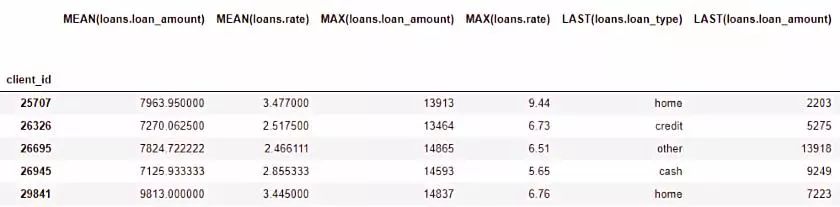
完整的数据框包含了793个新特征!
▌深度特征合成
现在我们已经做好理解深度特征合成的全部准备了。实际上,我们在之前执行函数时已经使用过深度特征合成了!深度特征是指通过叠加多个基元得到的特征,深度特征合成是指构造这些特征的过程。一个深度特征的深度是为构造这个特征所使用的基元数目。
例如,MEAN(payments.payment_amount)列是一个深度为 1 的深度特征,因为它在构造过程中只使用了一个聚合基元。LAST(loans(MEAN(payments.payment_amount)) 是一个深度为 2 的特征,它由两个聚合基元叠加构成:将 LAST 叠加在了 MEAN 上。这个特征代表客户最近一笔支付额的平均值。
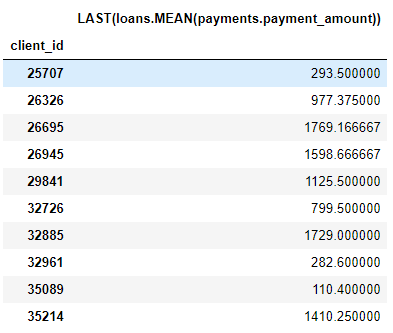
我们可以叠加特征到任何想达到的深度,但事实上,我从来没有用过深度超过 2 的特征。关于这一点很难解释清楚,但我鼓励感兴趣的人尝试更进一步的探索。
我们无需手动指定特征基元,特征工具可以帮助我们自动选择特征。为此,我们同样使用 ft.dfs 函数来调用但无需传入任何特征基元:
#Performdeepfeaturesynthesiswithoutspecifyingprimitivesfeatures,feature_names=ft.dfs(entityset=es,target_entity='clients',max_depth=2)features.head()
特征工具构造了许多供我们使用的新特征。虽然这一过程可以自动构造新特征,但它不会取代数据科学家的位置,因为我们还要清楚如何使用这些特征。例如,如果我们的目标是预测某位客户是否会偿还贷款,那么我们要找出与指定结果相关度最高的特征。此外,如果我们有领域知识,则可以利用领域知识来选出特定的特征基元,或通过深度特征合成从候选特征中得到种子特征。
▌下一步
自动特征工程解决了一个问题,但也制造了另一个问题:特征过多。虽然在拟合模型前我们很难说哪些特征是重要的,但肯定不是所有特征都与目标任务相关。而且,特征过多可能会导致模型性能很差,因为不那么重要的特征会影响到那些更重要的特征。
由特征过多导致的问题又被公认为“维度的诅咒”。对于模型来说,特征数量上升了(即数据维度增加了),学习特征和目标之间的映射规则也会变得更加困难。实际上,使模型有良好表现所需的数据量与特征数目呈指数关系。
“维度的诅咒”可以通过特征降维(也被称为特征选择)来减轻:这是一个剔除不相关特征的过程。我们可以通过多种途径实现:主成分分析 (PCA)、SelectKBest、使用模型的特征重要性或使用深度神经网络来自动编码。和今天要探讨的内容相比,特征降维应该另起一篇文章来单独讨论更合适。到现在为止,我们已经知道如何使用特征工具,从诸多数据表中轻松构造大量的特征了!
总结
同机器学习中的许多主题一样,基于特征工具的自动特征工程是一个以简单概念为基础的复杂方法。基于实体集、实体和关联等概念,特征工具可以通过深度特征合成来构造新的特征。深度特征合成将包含了表间一对多关联的“聚合”特征基元依次叠加,“转换”函数被用于单张表中的一列或多列数据,以此来从多张表中构造新的特征。
在之后的文章中,AI科技大本营也会介绍在实际应用(如 Kaggle 竞赛)中如何使用这项技术。模型的好坏取决于我们为它提供的数据,而自动特征工程有助于使特征构造过程的效率更高。希望本文介绍的自动特征工程可以帮到大家。
关于特征工具的更多信息,包括更高级的应用方法,可以查看在线文档。
-
自动化
+关注
关注
29文章
5564浏览量
79246 -
机器学习
+关注
关注
66文章
8408浏览量
132576 -
python
+关注
关注
56文章
4793浏览量
84634
原文标题:基于Python的自动特征工程——教你如何自动创建机器学习特征
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
招聘自动化、电气自动化、自动化控制工程师
【上海】猎头推荐职位-自动化测试工程师(java/python)
python自动化控制设备 精选资料分享
电子设计自动化(EDA)是什么
Python成为软件工程师的最爱
自动化立体库结构是如何组成的
分享10个实用的Python自动化脚本
使用Python脚本实现自动化运维任务
使用Python实现功能测试自动化

Python 模拟键盘鼠标的方式实现自动化





 工商网监
工商网监
评论