 几种常见的用于回归问题的机器学习算法
几种常见的用于回归问题的机器学习算法

当我们要解决任意一种机器学习问题时,都需要选择合适的算法。在机器学习中存在一种“没有免费的午餐”定律,即没有一款机器学习模型可以解决所有问题。不同的机器学习算法表现取决于数据的大小和结构。所以,除非用传统的试错法实验,否则我们没有明确的方法证明某种选择是对的。
但是,每种机器学习算法都有各自的有缺点,这也能让我们在选择时有所参考。虽然一种算法不能通用,但每个算法都有一些特征,能让人快速选择并调整参数。接下来,我们大致浏览几种常见的用于回归问题的机器学习算法,并根据它们的优点和缺点总结出在什么情况下可以使用。
线性和多项式回归
首先是简单的情况,单一变量的线性回归是用于表示单一输入自变量和因变量之间的关系的模型。多变量线性回归更常见,其中模型是表示多个输入自变量和输出因变量之间的关系。模型保持线性是因为输出是输入变量的线性结合。
第三种行间情况称为多项式回归,这里的模型是特征向量的非线性结合,即向量是指数变量,sin、cos等等。这种情况需要考虑数据和输出之间的关系,回归模型可以用随机梯度下降训练。
优点:
建模速度快,在模型结构不复杂并且数据较少的情况下很有用。
线性回归易于理解,在商业决策时很有价值。
缺点:
对非线性数据来说,多项式回归在设计时有难度,因为在这种情况下必须了解数据结构和特征变量之间的关系。
综上,遇到复杂数据时,这些模型的表现就不理想了。
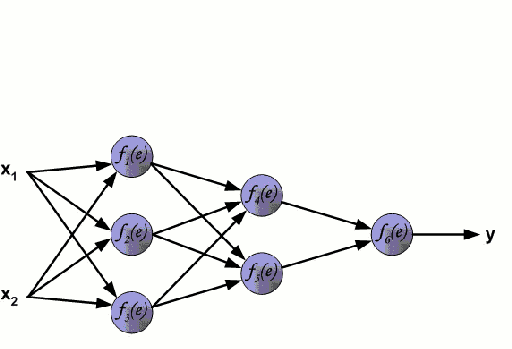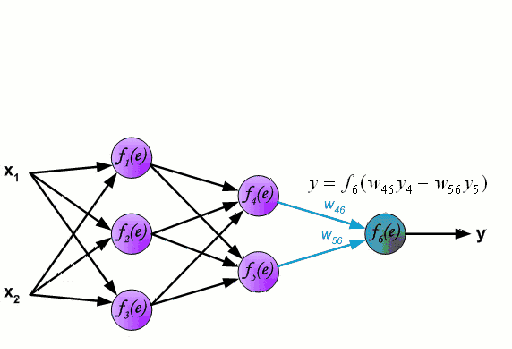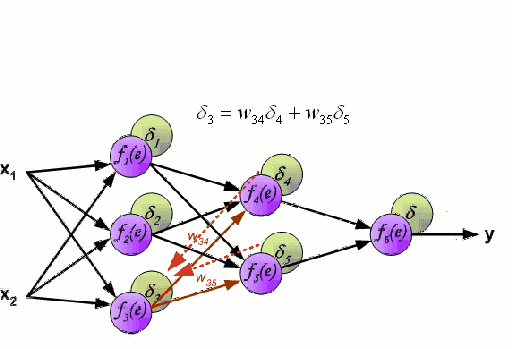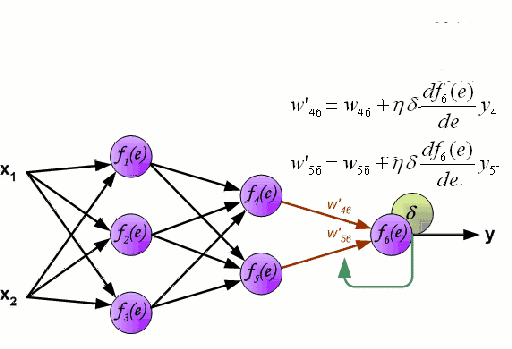
神经网络包含了许多互相连接的节点,称为神经元。输入的特征变量经过这些神经元后变成多变量的线性组合,与各个特征变量相乘的值称为权重。之后在这一线性结合上应用非线性,使得神经网络可以对复杂的非线性关系建模。神经网络可以有多个图层,一层的输出会传递到下一层。在输出时,通常不会应用非线性。神经网络用随机梯度下降和反向传播算法训练。
优点:
由于神经网络有很多层(所以就有很多参数),同时是非线性的,它们能高效地对复杂的非线性关系进行建模。
通常我们不用担心神经网络中的数据,它们在学习任何特征向量关系时都很灵活。
研究表明,单单增加神经网络的训练数据,不论是新数据还是对原始数据进行增强,都会提高网络性能。
缺点:
由于模型的复杂性,它们不容易被理解。
训练时可能有难度,同时需要大量计算力、仔细地调参并且设置好学习速率。
它们需要大量数据才能达到较高的性能,与其他机器学习相比,在小数据集上通常表现更优。
回归树和随机森林
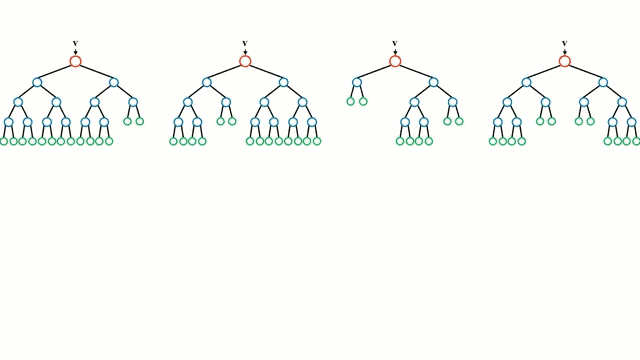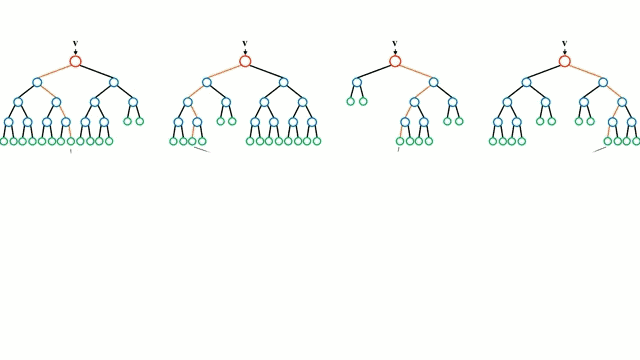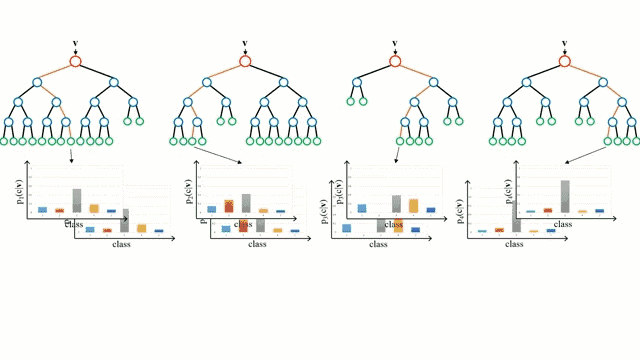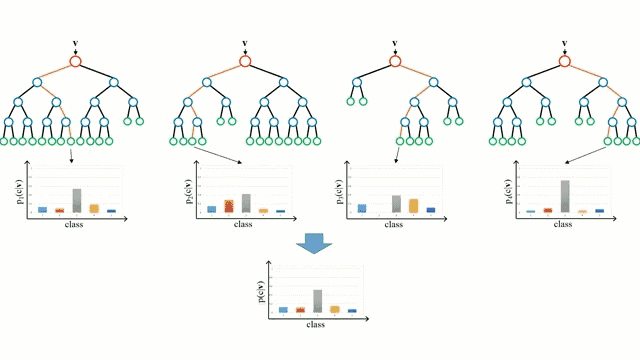
首先从基本情况开始,决策树是一种直观的模型,决策者需要在每个节点进行选择,从而穿过整个“树”。树形归纳是将一组训练样本作为输入,决定哪些从哪些属性分割数据,不断重复这一过程,知道所有训练样本都被归类。在构建树时,我们的目标是用数据分割创建最纯粹的子节点。纯粹性是通过信息增益的概念来衡量的。在实际中,这是通过比较熵或区分当前数据集中的单一样本和所需信息量与当前数据需要进一步区分所需要的信息量。
随机森林是决策树的简单集成,即是输入向量经过多个决策树的过程。对于回归,所有树的输出值是平均的;对于分类,最终要用投票策略决定。
优点:
对复杂、高度非线性的关系非常实用。它们通常能达到非常高的表现性能,比多项式回归更好。
易于使用理解。虽然最后的训练模型会学会很多复杂的关系,但是训练过程中的决策边界易于理解。
缺点:
由于训练决策树的本质,它们更易于过度拟合。一个完整的决策树模型会非常复杂,并包含很多不必要的结构。虽然有时通过“修剪”和与更大的随机森林结合可以减轻这一状况。
利用更大的随机森林,可以达到更好地效果,但同时会拖慢速度,需要更多内存。
这就是三种算法的优缺点总结。希望你觉得有用!
-
神经网络
+关注
关注
42文章
4844浏览量
108203 -
机器学习
+关注
关注
67文章
8567浏览量
137255
原文标题:如何为你的回归问题选择最合适的机器学习算法?
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
机器学习中的数据质量双保障:从“验证”到“标记”


机器学习特征工程:缩放、编码、聚合、嵌入与自动化
算法工程师需要具备哪些技能?
机器学习和深度学习中需避免的 7 个常见错误与局限性
用于单片机几种C语言算法
C语言的常见算法
有哪些常见的AI算法可以用于装置数据的异常检测?

量子机器学习入门:三种数据编码方法对比与应用

AI 驱动三维逆向:点云降噪算法工具与机器学习建模能力的前沿应用

任正非说 AI已经确定是第四次工业革命 那么如何从容地加入进来呢?
【嘉楠堪智K230开发板试用体验】K230机器视觉相关功能体验
有几种电平转换电路,适用于不同的场景



评论