 AttnGAN可以生成任意图像,从普通的田园风光到抽象的场景
AttnGAN可以生成任意图像,从普通的田园风光到抽象的场景
机器学习发展至今,我们看到很多AI模型经过大量数据能画画、能作曲。但是现在一个“神奇”的网站可以通过你的文字生成意想不到的图像。事情还要从大半年前的一篇论文说起。
在今年一月份发表的一篇论文中,微软研究院的实习生们训练了一个机器学习算法,称为AttnGAN。这是GAN的一种变体,可以根据写下的文字生成图像,图像质量是之前技术生成的图像质量的三倍。
这项技术可以生成任意图像,从普通的田园风光到抽象的场景,每幅图都能将文字描述详细地表示出来。
论文简介
最近很多文本生成图像的方法都是基于生成对抗网络(GAN)的,常用方法是将完整的文本描述编写进整个句子向量中作为图片生成的条件。虽然已经能生成质量不错的图像了,但是由于句子向量缺少在词语层面上的微调信息,GAN无法生成更高质量的图像。这一问题在生成复杂场景时更严重。
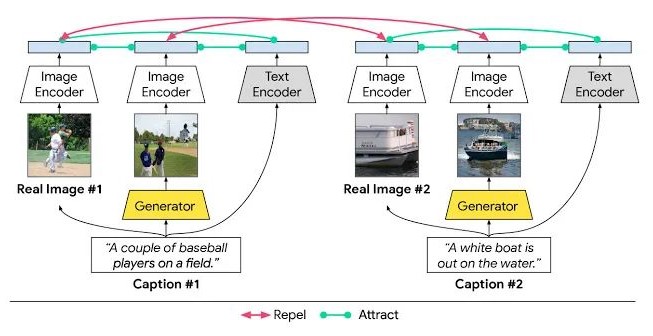
为了解决这一问题,作者提出了注意力生成对抗网络(AttnGAN),用注意力驱动、多阶段的方法对文本生成图像的问题进行微调。AttnGAN的整体结构如图:
模型有两个创新元素。首先是注意力生成网络,其中的注意力机制是通过观察与该区域最相关的文字,生成器画出图像的不同部分。
更具体地说,除了将自然语言描述编码到全局句子向量中,句中的每个单词同样有对应的向量。在第一阶段,生成网络利用全局句子向量生成一个低分辨率的图像。接着,它会通过注意力层用每个区域的图片向量查询词向量,从而形成一个词-语境向量。之后,它会将区域图像向量和对应的词-语境向量相结合,形成一个多模态的语境向量。这就能够在各个阶段生成细节更丰富的高分辨率图像。
该结构中的另一个重要组成部分是深度注意力多模态相似模型(DAMSM)。由于有注意力机制,DAMSM可以计算生成图像和句子之间的相似性。所以,DAMSM对训练生成器提供了额外的调整损失函数。
模型试验
与此前的方法相同,这篇论文提出的方法也在CUB和COCO两个数据集上测试。最终训练的结果如下:
每个场景的第一张图片都是AttnGAN的第一阶段(G0),仅仅描绘出了场景的原始轮廓,图像分辨率很低。基于词向量,接下来的两个阶段(G1和G2)学习纠正前面的结果。
在CUB数据集上的生成结果
经过COCO数据集训练的模型生成的结果,图中的描述几乎是不可能在现实中出现的
奇怪的方向
总的来说,AttnGAN的表现还是不错的。但是国外一些研究者逐渐找到了新的玩法。研究者Cristóbal Valenzuela根据论文搭建了一个网站,用户可以尝试AttnGAN,但不同的是,训练数据换成了更大的数据集。机器学习爱好者Janelle Shane在博客中写道:“当把这个算法在另一个更大的、内容更多样的数据集上训练后,生成的图片难以符合文字描述(并且变得非常奇怪)。”例如下面这个例子,同样的一句话,用原始模型生成的图片是这样的:
然而换了训练数据集后:
这是……什么?由于在更大的数据集上训练过,所以当GAN要画出我要求的内容时,它要搜索的图像就更多,问题也变得广泛。不仅仅在小鸟的生成上有限制,在生成人像上也会出现bug,例如下图:
这个表现得就很糟了,根本分不清哪里是人脸。其他类似的还有很多,完全就是超现实主义作品。
Janelle Shane表示:“这个demo非常有趣,它也体现了目前先进的图像识别算法是如何理解图像和文字的。它们如何理解’狗’或’人类’?在2D图像中,算法看到的人指向前方和侧面是完全不同的。”
对于这一结果,AttnGAN论文的作者Tao Xu也给予了回复。Xu目前是美国理海大学一名研究生,她认为这是对论文结果的重要改进:
“随着深度学习的快速发展,计算机视觉系统非常强大。例如它们可以从医学影像中诊断疾病、在自动驾驶系统中定位行人和汽车。但是,我们仍然不能认为这些系统完全理解了它们所看到的东西。因为,如果机器真的拥有了智慧,它们不会仅识别图像,而是可以生成图像。
我们的AttnGAN将注意力机制和生成对抗网络结合了起来,大大提高了文本生成图像的模型性能。由于注意力是人类特有的概念,我们的AttnGAN就能学习这种”智慧“,像人类一样画画,即注意相关词语以及相关图像区域。
虽然AttnGAN比之前的文本到图像的模型表现得更好,但是生成多种“现实画风”的物体对整个领域还是待解决的问题。我们希望未来在这一方向进行更多研究。”
-
机器学习
+关注
关注
66文章
8381浏览量
132428 -
数据集
+关注
关注
4文章
1205浏览量
24648 -
自然语言
+关注
关注
1文章
287浏览量
13332
原文标题:虽然很惊悚,但这个AI灵魂画手真的很努力了
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

六月,带你品味合心镇的合心瓜,享受田园采摘生活
点阵式液晶任意图片显示的实现
MAX4455 任意图形随屏显示视频发生器
红外场景仿真在导引头图像实时生成中的应用
GAN在图像生成应用综述


一种结合回复生成的对话意图预测模型

一种基于改进的DCGAN生成SAR图像的方法

AIGC最新综述:从GAN到ChatGPT的AI生成历史
基于文本到图像模型的可控文本到视频生成

一键解锁:将任意图像设备秒变GigE Vision设备的终极秘诀





 工商网监
工商网监
评论