 基于机器学习的磁盘故障预测的挑战及设计思想
基于机器学习的磁盘故障预测的挑战及设计思想
RGF算法+迁移学习精确预测硬盘故障。《Predicting Disk Replacement towards Reliable Data Centers》由IBM研究院发表于数据挖掘顶会议KDD 2016。磁盘是当今数据中心中最常见的硬件设备,也是最易发生故障的设备。尽管有如RAID的防御机制,系统的可用性和可靠性仍然经常严重冲击。 本文采用RGF算法和迁移学习精确预测硬盘故障从而判断硬盘是否应该更换。其方法对硬件设备的故障预测有借鉴意义。
互联网迅速发展,网络服务数量骤增, 大规模海量数据存储系统是必不可少的支持。虽然新的存储介质例如SSD,已经在读性能等很多方面拥有了比磁盘更好的性能,但就目前来讲,其高昂的花费使大部分数据中心难以负担。因此,大型数据中心依然采用传统的以磁盘为主的存储系统。这样做采购成本上虽然有了节省,但磁盘频繁损坏导致的数据丢失给企业带来的损失也是不可忽视的重大问题。
据美国63个数据中心组织进行的一项研究显示,数据中心的停机费用在过去几年中显著增加,从2010年的5600美元/分钟增加到2016年的8851美元/分钟。以往基于磁盘SMART属性建立的各种磁盘故障预测模型,虽然取得了一定的效果,但是其在SMART属性选择、准确性以及模型的复用性上存在不足之处。
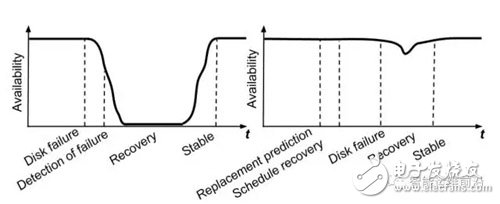
因此,本文提出了一个自动、精确的磁盘故障预测的方法,判断磁盘在接下来一段时间内需不需要替换。下面两个图展示的是有无替换预测的磁盘可用性示意图。左图代表的是传统的磁盘异常检测,磁盘状态开始变差后才检测到磁盘故障,这时的可用性已经降到了最低才开始更换磁盘。右图展示的是使用磁盘故障预测的情况,首先系统判断磁盘的状态即将要变差,然后工程师在磁盘可用性降低之前更换磁盘。通过这两个图的对比,我们可以看出提前预测磁盘故障可以降低故障对系统可用性的冲击。
磁盘故障预测的挑战
但是,磁盘故障预测,存在如下挑战:
不是所有的SMART属性都与磁盘故障相关。因为缺乏SMART属性对磁盘状态指示的标准,所以需要从SMART属性中选择与一部分磁盘故障相关的属性,作为故障预测模型的输入。
磁盘故障数据高度不平衡。随着时间的推移,健康磁盘的SMART数据量一直在增加,但是只有一小部分磁盘(2%)被替换,即被替换的磁盘数据非常少。分类算法通常最大限度地提升整体精度,少数类所包含的信息就会很有限,从而难以确定少数类数据的分布,即在其内部难以发现规律,进而造成少数类的识别率低。
不同类型的磁盘SMART存在差异。SMART是特定于制造商的,它们的编码和标准化在制造商之间差别很大,所以不能使用同一个预测性模型来判断不同型号的磁盘。下面两个图展示的是不同类型磁盘的SMART数据差异,其中左图表示的是温度,右图表示的是开机关机的周期,从两个图的对比可以看出,不同类型的磁盘SMART确实存在差异。
设计思想
本文分为如下五步来解决故障预测的挑战:
选择SMART属性。使用突变点(changepoint)检测的方法对SMART属性分类,选择与磁盘替换相关的SMART属性。
生成时间序列。使用指数平滑来生成简化但是信息丰富的时间序列。
解决数据不平衡性。通过欠抽样(downsampling)选择具有代表性的健康磁盘的数据,然后用这些数据来代表全部的健康磁盘,从而使健康磁盘与替换磁盘的比例达到平衡。
对磁盘状态分类。RGF是一个分类算法,可以将磁盘的状态分成0/1的状态,如果当前时间序列被分成1状态,则认为磁盘即将出现故障,需要更换磁盘。
迁移学习。考虑到同一厂商生产的不同磁盘模型之间也存在一定差异,本文使用了迁移学习的方法,从而利用某种磁盘上训练的模型来预测同一厂商的其他磁盘的故障替换情况。
1、选择SMART属性
因为SMART数据是随着时间的增长而生成的,所以文中是通过时间序列突变点(changepoint)检测来确定SMART与磁盘替换的相关性。当被替换的磁盘SMART时间序列中某个SMART属性发生突变,而且这个转变是永久性不可恢复的,那么可以认为这个属性与磁盘替换是相关的。
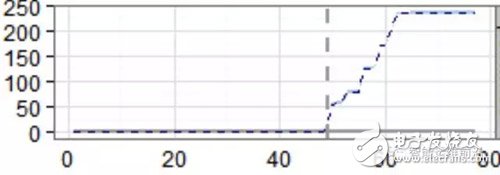
下图展示的是SMART_187_raw(无法纠正的错误)的折线图,这是报告给操作系统的无法通过硬件ECC校正的错误。如果数据值不为零,就应该备份磁盘上的数据了。从图中可以看出在第50天的时候,SMART_187_raw值突然增大,即第50天为突变点。
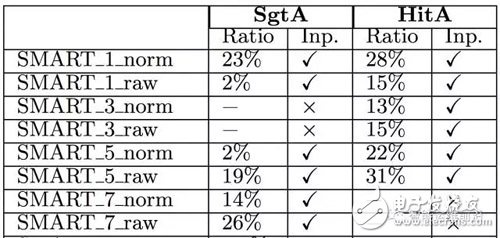
通过检测每一个SMART属性,本文得到了下表中展示的结果(只展示部分结果)。在表格中,SgtA和HitA分别表示希捷和日立的磁盘型号,Ratio表示磁盘替换前该属性值出现突变的比例。我们可以看出有些SMART属性确实与磁盘替换无关,而且对于不同型号的磁盘,与磁盘替换事件相关的SMART属性是不相同的。
2、生成时间序列
经过第一步的SMART属性值的挑选,下一步需要做的是生成预测模型可以使用的时间序列。使用时间序列作为模型的数据是基于如下三点考虑的:
每天的数据都是不稳定的,可能某天的SMART数据缺失。
磁盘具有一定的自恢复性,不能根据某一天的数据来判定磁盘接下来一段时间的状态。
如果只看某一天的数据,则无法提前一段时间来预测磁盘故障,也就无法留出充足的时间给工程师更换磁盘。
所以本文使用指数平滑的方法来生成时间序列,S_t=α·Y_t+(1-α)·S_(t-1)是指数平滑的公式,其中α是平滑参数,Y_t是之前t个数据的平滑值。α越接近1,平滑后的值越接近当前时间的数据值。指数平滑不舍弃过去的数据,而是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。
3、解决数据不平衡性
遇到不平衡数据时,以总体分类准确率为学习目标的传统分类算法会过多地关注多数类,而使少数类样本的分类性能下降。因为这些算法大多数建立在各类数据分布平衡的假设之下,以寻求数据总体分类准确率为最大目标。而在磁盘故障预测的场景下,磁盘故障的数量是远远小于正常磁盘的。本文使用了欠抽样(downsampling)的方式来平衡数据。
具体做法是这样的,对健康磁盘的时间序列样本做K-means聚类,聚类之后每一个类别中样本都是相似的,然后选择距离聚类中心最近的n个点作为健康磁盘样本的抽样结果。
4、对磁盘状态分类
本文使用了RGF算法对磁盘状态分类。RGF 算法是一个分类算法,它是GBDT(梯度提升决策树)算法最好的变种之一。针对 GBDT 每次迭代只优化新建树以及过拟合的问题,RGF使用了正则化的全局优化贪心搜索改进算法:
每次迭代直接对整个贪心森林进行学习
新增决策树后进行全局的参数优化
引入显式的针对决策树的正则项来防止过拟合

文中对比了RGF与其他分类算法的分类结果,上表中的P、R、F分别表示准确率(precision)、召回率(recall)、F-分数(F-score)。从表中可以看出,RGF的效果是最好的。
5、迁移学习
同一厂商生产的不同磁盘模型之间也是存在差异的。本文发现,不同磁盘模型之间具有相似的SMART属性,但相同的SMART属性之间的数据分布不同。因此,直接将训练集磁盘模型上建立的预测模型用于同一厂商生产的其他磁盘模型的故障预测,不能达到最好的预测效果。
首先我们来说明迁移学习中的两个重要概念,域(domain)和任务(task)。如下图所示。
域(domain):包括特征空间(feature space)X和边缘概率分布(marginal probability distribution)P(x), x ∈X。例如,一组图片中的所有可能颜色构成一个特征空间,而各种颜色出现的频率则为边缘概率分布。
任务(task):给定一个域,任务还包含两个要素,标签空间(label space)y和预测函数(predictive function)f(·)=P(y|x)。例如,一组图片中可能出现的所有元素构成一个标签空间,而通过预测函数可以得出某幅特定图片中包含哪些元素。
同一厂商生产的不同磁盘模型之间具有一定的关联性,但它们之间存在样本选择偏差(sample selection bias)。即不同种磁盘模型之间虽然具有大量的重叠特征,但源数据实例(带标签的训练数据)和目标数据实例(无标签的测试数据)的分布不同。因此,作者采用了基于实例的迁移学习方法来消除源数据和目标数据之间的样本选择偏差,从而将某种磁盘上训练的模型应用于其他磁盘上。
具体的,对于两种磁盘模型1和2,将带标签的磁盘1实例与无标签的磁盘2实例放在一起。训练一个分类函数,使f(x)表示一个磁盘属于模型1或模型2的概率。利用分类函数f对带标签的训练数据集进行重新采样,从而消除样本选择偏差,使训练集与测试集数据服从同一分布。此时,根据重新采样的训练集,利用前文所述的RGF算法训练出函数,g(x)代表该类型磁盘的一个实例需要进行替换的概率。由于重新采样的训练集与测试集服从相同的数据分布,因此可将预测函数g直接应用于同一厂商生产的其他磁盘模型上(测试集)。
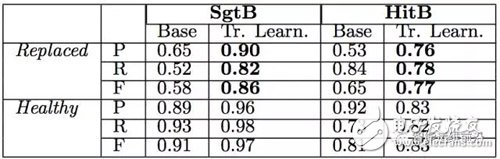
作者分别使用两个厂商生产的磁盘的数据集SgtA和HitA训练模型,并使用迁移学习的方法将两种模型分别应用于同厂商的其他磁盘数据集SgtB和HitB上。上表分别展示了直接将模型 A应用于磁盘B上以及运用迁移学习方法将模型A应用于磁盘B的替换预测的准确率、召回率、F-分数。可以看出,应用迁移学习方法后,预测准确性得到了很大提高,从而大大减少了需要训练的模型数量。
总结
本文介绍了一套自动、精确的磁盘故障预测方法,用于判断磁盘在接下来一段时间内是否需要替换。通过选择SMART属性、生成时间序列、解决数据不平衡性等步骤,将磁盘故障预测转化为对时间序列数据的分类问题。之后使用RGF算法对磁盘状态进行分类,从而找出可能发生故障的磁盘。对于同一厂商生产的不同型号的磁盘,采用迁移学习的方法进行处理,在保证预测准确性的同时减少模型训练开销。最后,文中采用不同厂商、多种类型的磁盘SMART数据验证该方法,达到了较高的准确率和召回率。
-
IBM
+关注
关注
3文章
1774浏览量
74911 -
磁盘
+关注
关注
1文章
380浏览量
25308 -
机器学习
+关注
关注
66文章
8453浏览量
133166
发布评论请先 登录
相关推荐
[转]物联网和机器学习究竟有哪些真实应用价值?
【下载】《机器学习》+《机器学习实战》
深度学习在预测和健康管理中的应用
什么是机器学习? 机器学习基础入门
基于机器学习的车位状态预测方法
磁盘阵列技术原理学习

美国军方“征用”AI助手 用机器学习预测军车故障
“预测”是美国政府应用机器学习的重要途径
如何使用机器学习技术解决社会网络链接预测问题
磁盘阵列的常见故障
机器学习准确预测发病风险
基于机器学习算法的水文趋势预测方法







 工商网监
工商网监
评论