 后摩尔时代,半导体的新战场与新机会
后摩尔时代,半导体的新战场与新机会
来源:智东西公开课
智东西公开课推出的AI芯片系列课完结第五讲,华登国际合伙人王林就主题《人工智能带来半导体的又一波创新浪潮》进行了一场系统且深入的讲解。在此番讲解中,王林认为,“随着技术推动力——摩尔定律,受到越来越大的挑战,而应用的最大推动力——智能手机,也遇到了非常大的增长瓶颈”,全球半导体行业已经进入后摩尔时代与后智能手机时代。他判断,在后摩尔+后智能手机时代,神经网络/深度学习已经成为半导体的新战场。
在行业应用层面,深度学习在快速变革传统行业并带来非常多新的应用,比如无人驾驶、医疗影像分析、工业自动化,FinTech。尤其是汽车,已经变成非常巨大的半导体应用平台。“全球所有顶尖的半导体公司都在围绕汽车来做未来的产品规划,希望其能够成为智能手机之后,对全球半导体行业有巨大推动力的推手。”而在处理器或架构层面,围绕深度学习训练与推理二个维度的加速需求,尤其是云端训练与推理、以及终端推理,出现非常多的芯片层面实现加速的创新方法或技术。结合有代表性的AI加速芯片产品或案例,就其中存在的创业机会与投资机会,他进行了深入的介绍和分析。
主讲实录
王林:大家晚上好,我是华登国际的王林,很高兴今天晚上有机会在智东西公开课的AI芯片社群跟大家做一些交流。其实今天晚上的演讲压力还是很大的,因为我看到群里有很多我的老朋友,都是芯片或者AI领域的高手。
平时演讲我都是尽量在懂芯片的人面前讲AI,在懂AI的人面前讲芯片,但是今天就没办法这么做了,因为群里有很多芯片和AI领域的高手。我尽我所能,如果有说的不对或者不太好的地方,还请大家多多包涵,主要是能有这样一个跟大家交流的机会确实非常难得。
今天来讲AI加速芯片还是一个挺应景的事情,因为昨天深鉴科技宣布被Xilinx全资收购。这也是我们能够看到近期少有的中国高科技公司被美国半导体公司并购的案例,以前我们更熟悉的是听到中国资本去海外并购一些科技公司或者半导体公司。深鉴科技在这方面做了一个很好的范例。从另一方面也说明我们中国的AI芯片在全球也处于比较领先的地位,当然也证明了AI芯片方面的创业还是挺有前(钱)景的。
讲到半导体,不得不从摩尔定律说起。我相信群里半导体从业人员对摩尔定律已经非常熟悉了,从Intel创始人戈登·摩尔提出摩尔定律到现在已经53年了。过去的53年中,半导体行业一直受着摩尔定律的指导。芯片越做越小,单位面积的晶体管越来越多,功耗越来越低,价格越来越便宜,也使得这个行业过去五十多年来一直保持不错的增长趋势。
我想给大家看下这张图。其实过去在投资界有一个共识,大家都认为半导体投资是非常不划算的事情,风险高、投资大、回报相对来说又比较低。所以,风险投资对半导体行业的投资在过去十来年一直不温不火,甚至是持续下降的趋势。当然半导体行业的增长也基本上印证了这样一个理念,也就是从前些年来看,全球半导体行业并没有一个非常大的增长幅度。
从右边这张表可以看到2016年全球半导体的增长率也就7%,很多时候半导体的增长率可能只有2%-3%。但是,很奇怪的是2017年全球半导体有了一个跳跃式增长,达到20%。这是过去十年来半导体行业从来没有看到过的事情,大家都瞠目结舌。所以,大家是否也有这样一个疑问:为什么2017年的增长这么大?
还有一个比较值得关注的点,欧美的半导体行业已经持续呈衰退状态,但是2017年,其增长甚至比中国还要高,尽管中国一直维持着半导体高速增长的趋势。从全球来看,中国市场仍然是增长最显著的动力源,也是一个非常耀眼的明星。
其实半导体的增长和集成电路芯片的应用息息相关。不得不说过去十年半导体的增长,一定依赖于智能手机行业的爆发式增长。可以说,到目前为止可能全球有一半的芯片是为了智能手机生产和使用的。所以说,智能手机一定是过去十年集成电路行业发展非常大的推动力。
但这里又不得不说,到现在为止我们已经到了后智能手机时代。这里摘录了一些新闻,通过标题大家就可以看到从2016年开始,整个智能手机的增长相比之前是非常缓慢的。相信大家日常生活中应该也能明显感受到,手机上的创新越来越少,换机的动力也越来越小,所以整个市场的增长持续一个很平静的状态。
同时,从技术角度来看,摩尔定律近期也受到了非常大的挑战。虽然我仍然坚信摩尔定律至少在近些年会持续演进下去,但是不得不说,随着工艺节点的越来越小,也会带来成本的显著性提高。我相信,未来7nm、5nm、3nm量产的日子一定会到来,但是也许到了那天可以用上或者说用得起那么先进工艺的芯片公司也寥寥可数。业界目前有这样一个共识:28nm应该会是一个长期存在的工艺节点,其性能、成本是一个比较合理的均衡状态。
对于半导体行业从业人员来说,这是一个很悲催的事情。技术的推动力——摩尔定律,受到越来越大的挑战,而应用的最大推动力——智能手机,也遇到了非常大的增长瓶颈。从技术推动力和应用两大层面来说,半导体行业都遇到了很大的问题。所以,这也进一步印证了为什么前几年投资界对半导体行业这么悲观,从某种程度上来说也是有一定道理的。
当然,我们不能不承认,敢从事半导体方面的人员一定是非常值得尊敬的,都是敢啃硬骨头的。从我发的这张图可以看到,其实工业界已经在尝试用多种方法尽量去使摩尔定律能够更长期的延续下去,或者能够以更低的成本延续下去,包括大家所知道的FinFET、FD SOI,都是业界正在推动的一些主流技术路线。EUV光刻技术,三维封装等都是能够使摩尔定律长期维持下去的一个非常有效的手段。
从我个人来看,如果半导体行业仍然要像过去智能手机时代一样飞速成长,一定要找到下一个应用推手,也就是说一定要找到后智能手机时代什么应用才是对我们半导体行业有巨大推动力的应用。我们来看下戈登·摩尔怎么说,他五十三年前提出摩尔定律的时候,同时做了一个预言。大家可以看下上图右上角用红色字体标注的这段话。
其实戈登·摩尔在五十三年前已经说了“集成电路会带来家用电脑或者至少是和中央电脑所连接的终端设备、自动驾驶、个人便携通讯设备等”。看到这里,我们就应该清楚戈登·摩尔在五十三年前所做的预言,到今天为止已经基本上都实现了。也就是说,其实戈登·摩尔已经看到了集成电路的发展会带来非常多的新应用,而这些新应用反过来会成为集成电路发展的巨大推动力。
说到这里,让我们来看,在后智能手机时代,什么才是集成电路行业的最大推动力呢?
人工智能的出现让业界眼前一亮,或者是让半导体行业找到了新的方向和推动力。当然,很多人会说,深度学习也好、神经网络也好,只是一个技术,为何能够成为从应用角度去推动集成电路发展的一个推手呢?
很明显,到现在为止,大家耳熟能详的从“互联网+”到“AI+”可以看到深度学习的出现,给非常多的传统行业带来翻天覆地的变革机会,甚至带来一些新的应用。我觉得,这是深度学习所带给我们的广阔天地。大家比较熟悉的AlphaGo下围棋,包括戈登·摩尔所说的无人驾驶汽车,其背后不得不说是深度学习的出现才带来了这样巨大的、有前景的应用。当然,还有医疗影像分析,GE、飞利浦、西门子这三家巨头在他们最新的医疗影像设备上,其实已经集成了非常强大的人工智能算法来辅助医疗影像科的医生去更快更好更准确的做诊断;工业自动化领域,半导体生产制造、封装测试领域带有机器视觉功能的机器已经非常多了,当然还有FinTech。深度学习给各行各业带来的变革已经非常明显。
我们应该感谢深度学习给集成电路行业的发展带来这么多新的应用机会。但是反过来,没有集成电路行业的有力支持,深度学习也不可能达到今天这样令全球瞩目的地位。
上面这张图展示的是四代AlphaGo所使用的硬件平台。第一代AlphaGo Fan是跑在176个GPU上,打败李世石的第二代AlphaGo Lee当时是跑在48个第一代Google TPU上,打败柯洁的第三代AlphaGo Master跑在4个Google第二代TPU上,包括前不久出现的使用对抗神经网络等算法的AlphaGoZero仍然是跑在4个TPU上。
大家还是否记得一开始我说的为什么去年欧美半导体的增长这么大?在这里想跟大家说一下,我觉得AI是一个非常大的推动力,带来的更多是云端的一些需求,对数据和算力上的创新需要大量的存储、更快的光通信等,同时对工业和汽车领域也带来了非常多新的机会。
不得不说,欧美的半导体厂家在服务器、工业、汽车领域仍然拥有很强大的不可撼动的优势和地位。如果说这三大领域得到了非常快速的应用增长和半导体芯片需求的增长,那么首先得益的肯定是欧美半导体公司。这也是为什么欧美的半导体公司在2017年能够有这么耀眼的成绩。
正如戈登·摩尔所说,集成电路的发展带来了无人驾驶汽车,在这里也要感谢深度学习算法的出现,毫无疑问汽车已经变成了一个非常巨大的半导体应用平台。可以说全球所有顶尖的半导体公司都在围绕着汽车来做未来的产品规划,希望其能够成为智能手机之后,对全球半导体行业有巨大推动力的推手。当然这个行业也在经历着巨大的变化,就是要实现汽车行业的四个现代化:新能源化、智能化、共享化、互联网化。
从智能化的角度来说,没有深度学习的出现,智能化的到来将是遥不可及的事情。但也正是因为智能化的出现,给了汽车非常多的卖点,使得消费者愿意去选择更智能、更具有吸引力的汽车,也使得汽车行业的增长带来了集成电路行业这样一个巨大的应用平台。
这张图非常有意思,我经常喜欢跟朋友们分享福特、通用和特斯拉这三家车厂最近的一些变化。通过这张图大家可以看到汽车行业正在经历着巨大的变化,一方面是因为汽车的半导体化电子化,另一方面也是因为深度学习带来的汽车智能化。大家可以看到拥有电子化和智能化的特斯拉的市值已经和通用、福特到了一个相同的位置。但是从出货量和成立时间来看,特斯拉跟这两位老大哥的差距其实还很大。
前面讲了一些应用以及半导体行业的一些发展趋势,我觉得现在有必要再和大家探讨一下,深度学习到底给我们带来了什么?带给半导体行业的创新点到底是什么?因为我是学工科出身的,其实对于学工科的学生来说,一开始接触到深度学习会带来一个非常大的思维障碍。因为对于我们来说,以前学习的理论或者定理,总是要知道来龙去脉,不仅要知其然,还要知其所以然。但是对于深度学习来说,其实我们很难把他搞得这么清楚。
打一个不恰当的比方,深度学习更像中医,可能更多的是凭经验或者感觉,其实很多时候对我们来说深度学习就像一个黑盒子或者灰盒子的状态,我们没办法也没能力去把这么庞大的神经网络里面的运算规律搞清楚。
但是不管怎样,深度学习带给我们的结果大家是看得到的,深度学习我们使用的时候需要做训练,然后反过来需要推理,这样的过程我们已经做得非常熟了,所以在以后工程化应用过程中,已经没有理论上的一些障碍了。
深度学习也确实给工业界带来了巨大的效率提升,虽然我这里只是列了一些比较老的数据,但其实96.4%的准确度已经已经超过了人类的水平。
那么深度学习要选择处理平台或者什么样的架构来做运算呢?其实很自然的一个想法就是,既然神经网络是从人脑来仿真和模拟出来的,那么我们是不是应该有一个类脑运算平台或者类脑芯片呢?其实业界也有非常多的公司在做这方面的探索。
在这里我就列了两家做公司做的类脑芯片:IBM的Truenorth和高通的Zeroth,都是比较典型的类脑芯片。不知道大家是否有印象,大概一两年前,国内曾有报道称浙江大学发布了应该是国内第一款基于SNN(脉冲神经网络) 的类脑芯片。
因为负责这款芯片开发的教授正好是我浙大的师兄,所以看到这个新闻之后,我也跟他做了一些沟通,就是基于SNN的类脑架构在理论水平和芯片水平上到底是什么层次?可以看到趋势还是很明显的,至少在工程上已经得到了实现的可能性验证,他们在OCR的识别上应该有达到70-80%的准确度。但是,很遗憾的是SNN一直没有非常合适运算平台,造成SNN从理论、算法的基础研究上是严重滞后于深度学习的科研水平。
不管怎样,我认为类脑芯片还是非常值得我们关注的一个未来趋势。但是,短期来看还是基于深度学习算法和运算平台更值得工业界去关注和探索。
这里我们不得不提到另外一个人——冯·诺依曼。他在1946年提出的冯诺依曼架构一直指导着我们计算体系架构的发展。绝大多数的体系架构创新都是基于冯诺依曼架构的,都没有超出他的框架范围。冯诺依曼提出所有的计算机的都由存储、控制、逻辑运算、输入和输出五部分组成。
我大致做了一个归类,不知道是否准确,只是说在我做投资和分析的时候给我一些指导,可能对我个人有些帮助。我把冯诺依曼架构的五大组成部分分为三类,输入输出归类于交互,控制和逻辑归类于计算,存储单独列为一类,也就是交互、计算和存储三部分。我觉得深度学习对这三方面都提出了非常多的创新要求,也使我们看到了非常多创新的机会。
大家都在说深度学习三要素:算法、算力和数据,从某种程度上跟我之前总结出来的交互、计算和存储三大计算机体系组成是一一对应、息息相关的。后面我也会从算力和存储的方向,阐述下我个人认为创新的点和需要攻克的难点到底在哪里。
深度学习到目前为止可以说是兵家必争之地,包括我们现在看到深鉴科技被Xilinx收购。其实国内还有很多企业在做深度学习加速的研究。国际上,高通投资了商汤,Intel投资了地平线,华为海思的麒麟970里面集成的深度学习加速IP来自北京的寒武纪科技。其实可以看到,不管是创业公司还是国际上的大公司,深度学习都受到非常多的关注。
虽然都是深度学习的加速,但是在不同的应用领域,我们还是要分别来对待。包括深度学习的训练和推理,芯片的应用场景,比如云端和我们所谓的终端,我认为在不同的芯片里面,对于加速的要求还是不太一样的。
对于终端的训练来说,我还没有看到太多的机会或者应用场景,包括从功耗的角度是否存在这样的可能性,也值得大家去探讨和思考。
但是在云端训练的角度来看,GPU是占有绝对优势的,当然FPGA的加速卡、包括Google在做的TPU用来做训练的ASIC也都在显示自己的威力;我觉得终端inference,会是一个更加广阔的应用场景。对于终端来说,从功耗、成本的角度来考虑,ASIC是更加值得大家去关注的一个趋势。

接下来我来给大家分享一些比较主流的深度学习在芯片层面实现加速的方法。我相信有更多的专家在这方面会讲出更值得大家去思考和探讨的内容。
脉动阵列并不是一个新鲜的词汇,在计算机体系架构里面已经存在很长时间。大家可以回忆下冯诺依曼架构,很多时候数据一定是存储在memory里面的,当要运算的时候需要从memory里面传输到Buffer或者Cache里面去。当我们使用computing的功能来运算的时候,往往computing消耗的时间并不是瓶颈,更多的瓶颈在于memory的存和取。所以脉动阵列的逻辑也很简单,既然memory读取一次需要消耗更多的时间,脉动阵列尽力在一次memory读取的过程中可以运行更多的计算,来平衡存储和计算之间的时间消耗。
上面这张图非常直观的从一维数据流展示了脉动阵列的简单逻辑。当然,对于CNN等神经网络来说,很多时候是二维的矩阵。所以,脉动阵列从一维到二维也能够非常契合CNN的矩阵乘加的架构。
我们还可以从体系架构上对整个的Memory读取来做进一步的优化。这里摘取的是寒武纪展示的一些科研成果。其实比较主流的方式就是尽量做Data Reuse,减少片上Memory和片外Memory的信息读取次数,增加片上memory,因为片上数据读取会更快一点,这种方式也能够尽量降低Memory读取所消耗的时间,从而达到运算的加速。

还有就是大家比较熟悉的剪枝技术。这也是深鉴科技当时出来创业赖以成名的绝技。对于神经网络来说,其实很多的连接并不是一定要存在的,也就是说我去掉一些连接,可能压缩后的网络精度相比压缩之前并没有太大的变化。基于这样的理念,很多剪枝的方案也被提了出来,也确实从压缩的角度带来了很大效果提升。
需要特别提出的是,大家从图中可以看到,深度学习神经网络包括卷积层和全连接层两大块,剪枝对全连接层的压缩效率是最大的。下面柱状图的蓝色部分就是压缩之后的系数占比,从中可以看到剪枝对全连接层的压缩是最大的,而对卷积层的压缩效果相比全连接层则差了很多。
所以这也是为什么,在语音的加速上很容易用到剪枝的一些方案,但是在机器视觉等需要大量卷积层的应用中剪枝效果并不理想。我相信这也是未来很好的创业和搞科研的方向。
对于整个DeepLearning网络来说,每个权重系数是不是一定要浮点的,定点是否就能满足?定点是不是一定要32位的?很多人提出8位甚至1位的定点系数也能达到很不错的效果,这样的话从系数压缩来看就会有非常大的效果。从下面三张人脸识别的红点和绿点的对比,就可以看到其实8位定点系数在很多情况下已经非常适用了,和32位定点系数相比并没有太大的变化。所以,从这个角度来说,权重系数的压缩也会带来网络模型的压缩,从而带来计算的加速。
当然,一个不能回避的问题是计算和存储之间的存储墙到现在为止依然存在,仍然有大量的时间消耗在和存储相关的操作上。
一个很简单直观的技术解决方式,就是堆叠更多更快速更高效的存储,HBM孕育而生,也即在运算芯片的周围堆叠出大量的3D Memory,通过通孔来连接,不需要与片外的接口进行交互,从而大大降低存储墙的限制。
更有甚者提出说,存储一定要和计算分离吗,存储和运算是不是可以融合在一起,PIM(Processing in Memory)的概念应运而生。我觉得,这也是一个非常值得大家去关注的领域。我知道,群里有些朋友也在PIM领域做一些创业的尝试。
当然,除了前面说到存储内置,以及存储与运算的融合,有没有一个更快的接口能够加速和片外Memory的交互也是一个很好的方向。其实上面这个概念是NVIDIA提出来的interface(接口),叫做NVLink。下面的表展示的是NVLink和PCIe Gen3的对比。大家平时看到跟存储相关的的PCIe卡可能是PCIe Gen3 by 4,只有4个lanes和Memory对接,但是NVLink与有16个PCIe的lanes的PCIe Gen3对比,速度也有很大的提升,可以看到NVLink在速度层面是一个非常好的interface。

前面讲了一些在我看来比较经典的加速方法。下面我会分享几个已经存在的AI加速芯片的例子,相信这样会更加直观。
第一个是Google的TPU。从右边的芯片框图可以看到,有一个64K的乘加MAC阵列对乘加运算进行加速。从论文中可以看到里面已经用到了脉动阵列的架构方法来对运算进行加速,另外也有我们前面提到的大量的片上Memory 这样的路径。上面蓝色框图中大家可以看到有一个24MiB的片上Memory,而且有两个高速DDR3接口能够与片外的DDR做交互。
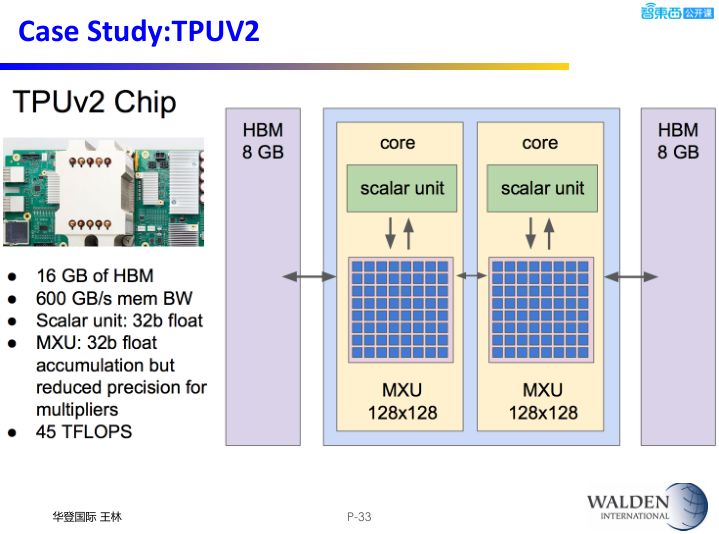
上图展示的第二代TPU。从图中可以很直观的看到,它用到了我们前面所说到的HBM Memory。从其论文披露的信息也可以看到,二代TPU在第一代的基础上增加了我们前面说到的剪枝,权重压缩等方面做了很多尝试,也是一个非常经典的云端AI加速芯片的例子。
这家公司叫SambaNova,不知道大家有没有听说过,是我们和Google Venture投资的一家做云端AI加速芯片的硅谷公司。他们更多是想要挑战NVIDIA在云端训练的地位。前面提到的很多加速的方法他们都会去做尝试,包括片上Memory、HBM等。其实更值得一提的是SambaNova非常强大的软件实现的团队力量。其实大家现在看到的一些加速芯片所支持的框架,可能更多是TensorFlow、Caffe这两个比较流行的框架。但是,他们开始支持微软和Facebook发布的框架Onnx。在他们看来,Onnx是通用性和兼容性更好的一个框架。
接下来跟大家分享几个终端做Inference的例子。第一个是Rokid和杭州国芯共同打造的一颗针对智能音箱的SoC,AI加速只是里面的一个功能。通过右边的框图可以看到里面集成了Cadence的DSP,还有自己设计的语音加速硬件IP——NPU。这款芯片还集成了一些实现智能音箱必要的interface,最值得一提的是在SiP层面封装了Embedded DRAM,可以更好的在系统层面实现数据的交互,实现存储和运算的加速,也实现了AI加速的功能。
最后说一款华为海思最新的IP Camera芯片——3559A,也是我个人比较喜欢的一款芯片。从集成度以及整个设计的均衡性来说,都令人眼前一亮。可以看下右上角几个蓝色的标准模块,里面集成的是海思自主研发的做推理的IP——NNIE,同时还集成了Tensilica DSP,在灵活性和扩展度上做了一个非常好的补充。
今天不光讲了创业的机会、投资的机会,我认为也正是因为中国有了现在非常好的产业政策,不管是人才还是市场,都是一个很好的创业土壤。我觉得AI加速方面创业和投资的机会依然存在,也希望和有志于在AI领域创业的朋友多多交流。谢谢大家,我的分享到这里就结束了。
-
芯片
+关注
关注
454文章
50594浏览量
422782 -
半导体
+关注
关注
334文章
27179浏览量
217698 -
晶体管
+关注
关注
77文章
9667浏览量
138000 -
AI
+关注
关注
87文章
30503浏览量
268741
原文标题:后摩尔时代,半导体的新战场与新机会
文章出处:【微信号:iawbs2016,微信公众号:宽禁带半导体技术创新联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
半导体迎来触底反弹,半导体时代即将绽放光彩
中国半导体产业:面临关键时刻的抉择
警惕KKR收购ASMPT:中国半导体产业的关键时刻与抉择

高密度互连,引爆后摩尔技术革命
特种玻璃巨头肖特发力半导体业务,新材料基板成为下一代芯片突破口

半导体行业回暖,万年芯深耕高端封装

意法半导体加速AI时代业务重组,重塑半导体制造未来
中国半导体产业需凝聚共识、智慧与力量
时代半导体获43.28亿战略投资 助力功率半导体产业发展
半导体发展的四个时代
半导体发展的四个时代
高精度纳米级压电位移平台“PIEZOCONCEPT”!

2023年Chiplet发展进入新阶段,半导体封测、IP企业多次融资
奎芯科技唐睿:高速接口 IP与 Chiplet成后摩尔时代性能突破口






 工商网监
工商网监
评论