 《大规模图像理解、分割新进展》的主题演讲
《大规模图像理解、分割新进展》的主题演讲
7月28-29日,由中国人工智能学会和深圳市罗湖区人民政府共同主办,马上科普承办的“2018 中国人工智能大会(CCAI 2018)”完美收官。
香港中文大学终身教授,腾讯优图实验室杰出科学家,IEEE Fellow贾佳亚作题为《大规模图像理解、分割新进展》的主题演讲。
以下是根据速记整理的大会讲座实录。
贾佳亚 香港中文大学终身教授,腾讯优图实验室杰出科学家,IEEE Fellow
目前,机器视觉已在下面几个领域得到了成功的应用。
1. 在游戏领域。机器视觉可以知道一个人的形体、骨骼、结构,可以制作出很多新的游戏。这个市场非常大。
2. 安防领域。传统上需要看很多的摄像头,需要很多人力去审查,现在基于机器视觉技术,日常的判别不需要人去看,电脑就可以完成。
3. 娱乐领域。视觉技术可以创造出非常漂亮的人物,改变每一个人的外观。基于此,腾讯做了很多的娱乐应用,如QQ里就有非常多有趣的玩法。
4. 医疗领域。从被医生主导到现在电脑技术和人工智能技术,病变和异常可以自动检测出来,这也是计算机视觉可实用的一部分。
5.自动驾驶领域。计算机视觉是其中一个基本模块。
我今天演讲的主要部分是偏技术的,在演讲之前,给大家看一些有趣的东西。
第一个是是超分辨率的结果图(见上图)。这是一个老问题,研究了几十年。我们去年在ICCV发表的一篇论文又在之前的基础上极大地提高了速度和结果的分辨率,在一个非常模糊的图片中生成清晰的细节。系统很简单,它对在网络上需要大量传输的图像或者视频,可以极大地减少带宽流量需求,节省成本。
第二个是我们团队研究了多年的Deblurring去模糊。当大家看到像上面这张模糊照片时第一个反应是把这张图像删除,节省空间。现在我们的技术可以“变废为宝”,从这些图像里解析出车牌、人脸、字符,以及其他很多清晰细节。去模糊是图像处理里比较难的问题之一,因为它是一个高度ill-posed(病态)的问题,已经研究了十年。最近我们又开发出了新的方法,把结果做的更好。
第三个是我们和Intel的合作者今年在CVPR大会上发表的一个有趣的图像生成系统。给出一个简单的画板(见上图),可以生成非常真实的图像结果。这个过程可以用历史上的文艺发展阶段来理解。人类经历了一个从写实派到抽象派的发展过程。现在电脑技术创造还处在一个连写实派都做不好的阶段 —— 从一个任意的简单构思到电脑帮你生成一张高质量的相片还是非常难做到。这是其中一个我们要攻克的难关。
第四个就是我们去年做了一个Make-UP Go(一键卸妆)的系统。其目标是把上了妆(如上面左图所示)的和实际样子差别太大的图片回复到上妆之前的容貌。这个系统在未婚男士群体中需求量很大。
基于这个系统和改进,我们今年发表了一个Face edit(脸部编辑)系统。它可以任意改变面部的表情和真实容貌,可以加胡子,去除胡子;变年轻,变老;变哭为笑。这些效果都非常真实,就像一个人真实面容一样。上图示一个主持人的视频,我们可以随便改变他的样子,比如留英俊的小胡子,年轻10岁;或者看到他20年后的样貌。
以上的技术和效果都叫做前端视觉,就是可以让人直接看到很多效果的一类视觉研究。很有趣,用了很多时间研发。加入腾讯以后,我发现前端视觉有非常多的应用,可以给不同的团队和产品赋能。所以在这一年时间里,腾讯产品里多了很多以这样的技术为基础的产品应用。
除了给大家列举的这些前段视觉的例子,今天我主要讲的技术叫做语义分割,它是计算机视觉里最难的技术之一。同时这类研究我也称之为后端视觉。因为它们是基本工具,不能直接变成视觉效果。但是这些工具确实非常有用,基本上很多应用都必须用到,这是为什么叫它后端视觉的原因。
从2016年到今天,3年时间里,我们做了大量的图像语义分割研究。它的目标是把一幅图像里的每个像素分到一个类别里,比如人、车或者道路。这是一个非常难的问题,需要分辨每个像素是什么类别。而总类别有80个以上,这就使得合理的分割具有很大的歧义性和巨大的搜索空间。
下面是语义分割技术的应用范围。
• 可以分辨哪些是人、车、树和房屋,是自动驾驶和道路理解里很重要的部分。
• 可以把提取出来的物体轮廓做增强,帮助很多有视力疾病的人,使他们生活变得更加便利。
• 智能医疗的核心部分是病理图像的理解。其中最关键的部分就是语义分割,找到病变的图像部分,或者分析心血管的内部结构信息。这对于医生的帮助非常大,可以节省时间或者提高诊断的准确度。
• 卫星图像理解。可以自动定位出不同的人、树、房屋;也可以在卫星图像里找到道路,以及更加复杂的环境布局。
• 可以把图像或者视频中的人物提取出来,自动切换背景,以及实现虚化等效果。
这些都是在图像语义分割的基础上实现的。
展望未来,如果有家庭机器人,它一定要有本领理解环境,看到周围的事物。而语义分割技术可以改进机器人的识别能力,是其一个重要的组件。
上面我讲的是图像语义分割研究的重要性,下面的内容就更加技术化,主要阐述怎样开发这类算法和算法的特点。
首先要展开讲的技术是传统语义分割。如上图所示,2012—2013年语义分割技术没有大的变化,说明领域出现了一个小瓶颈;2014年,因为有了新的神经网络模型——全卷积神经网络(FCN)为代表的工作,使这个领域又被推动了一步;从2013—2018年每年都有提升,说明这个领域开始进入了一个新增长期。在可用数据集上,传统用的是Pascal VOC 2012,包含大概2万张图片,数据量并不大。后来出现了cityscapes 数据集,标注了更多道路图像,有粗标注和精细标注的种类。
在方法上,传统的语义分割技术需要预处理、主程序和后处理,现在的深度学习框架下则全部统一了。也就是说,输入一个视频或者图像直接在网络里输出结果。这对于硬件适配也是很好的简化。
在2017年我们推出了一个技术叫做PSPNet(见上图)。这是我们学校的研究组和商汤科技一起开发的,它最重要的部分就是中间把输入的图像通过网络分成不同大小的特征,每一个特征做提取,最后做一个聚集达到高质量的结果。这个网络非常简单,但是拿到了ImageNet Scene Parsing Challenge 2016 第一名。刚才说到的FCN准确率44.8%,这个网络达到57.21%,提高了13%,是非常大的进步。这个框架现在有很多应用,在不同领域都可以使用,包括显著性检、双目深度估计、运动估计、3D重建,而且我们已经将它开源。
开发完这个技术之后我们开始新的挑战。在上面的图表里,横轴是时间,越往右说明算法越快;纵轴是准确率,越往上越高。我们让所有之前的算法都在这个图里根据速度和准确度找到自己的位置。在统计意义上,里面有三个部分。一个部分是做的很准,但是模型很复杂,计算量大,所以跑的很慢;一个是做的很快,但是因为对网络简化的太厉害导致效果不好。基于此,我们迎接了一个挑战,就是把分割做到又快又准,这就是在这个图标里进入右上角的象限。
我们提出的算法叫做ICNet,是今年ECCV的论文。它的原理是把图像特征提取分成几个部分,对于小尺度的图像,用一个比较深的网络来提取特征,因为每一层的运算非常小,所以这部分时间开销不大;对于大一些的图像尺度把网络的层数减少,也可以很快减少运算量。按照这个思路,在三个尺度上对图像提取了特征,最后做融合和分类,这个网络就完成了。ICNet既满足了运算量的压缩需求,又没有损失太多的特征信息,是一个比较好用的网络结构。我们的代码也是开源的。
利用PSPNet和ICNet,在2016年开始的各类语义分割比赛中拿到了很好的成绩,证明了我们这套框架在实际应用中有效,可以被广泛的应用。
以上是传统语义分割。同期我们进行了另外一个重要研究,就是把语义分割延展到个体理解。语义分割不需要知道一张图里有几个人,只要能正确地把人的像素点给分类正确就可以了。而新的个体分割(instance segmentation)需要理解的更深刻,把图像分成个体而不是类别。这个问题更难解决,因为它有了计数的概念。个体分割的概念提还不到10年时间。
从2015—2018年3年时间里,我们在这类研究中投入巨大,当时成绩也是不错的。在这个例子里,我们可以把这复杂的十几辆有遮挡,有断层,颜色相近,大大小小的车全部分割出来。
我们设计模型时尝试了很多办法。举这个Simpson的例子,里面三个人,如果要把Simpson分离出来,需要设计一个网络(见上图)。首先想到的是检测出Simpson,然后把他提取出具体轮廓;后来把每个个体的各个部分分割出来组合成整体,这是第二个解决方案;第三个算法是把物体的横向和竖向信息分别找一遍,然后结合起来一个二维的理解,把人提取出来;最后还有一个方法根据物体边界,把里面填满就可以找出需要的个体信息。
首先讲第一个从部分到整体的方法。原理是分别用小范围信息分割出需要的像素点,最后整合成整体目标。这个算法与乐高玩具的原理比较相近。一个乐高的玩具车可以被拆成很小的部件;同时如果合理的利用这些部件,加以改变,就可以组装成另外车的样子。所以,一个物体的组成是依赖于自己小部件的组合方式,以及每一个小部件的特点。这个结构里包含了两条路径分别分割出物体,以及给出合适的类别标签。
第二个我们探索的个体分割的算法类似于一个建筑物的建造过程 ,是由一砖一瓦慢慢由底至上搭建起来的。类似提出了sequential Grouping(序列组合)的算法,去实现逐步分割出物体的过程。我们的想法是,用线条组成物体的基本几何元素,这样利用横线和竖线的交叉(见上图),以及起点终点的建立,就可以搭出一个所需物体的轮廓。
横线和竖线是一维的信息;把它们结合到一起就变成了二维的特征。这个方法很有创新性,是之前没有人做过的。我们的结果也很激动人心,在这样的程序下面也可以得到相当准确的结果。大家有兴趣可以到我们的项目网站上查询更多细节。
最后要介绍的方法是我们最近的研究结果PANet(见上图),它基于了Mask R-CNN一个理解。我们的重要算法是将各层级提出来的特征做融合,使语义和结构信息更好保留,对最后检测和分割有很大的提高。
这个改进非常有效,在最有代表性的COCO数据集上比之前的方法提高了好几个百分点。
这一页slide给大家看看个体分割的进展。从2015年开始, 2016年达到了37.6的分割结果。我们的PANet实现了46.7点的分割结果,比上一年最好的方法有了24%的相对进步。
后面的例子包含的信息量很大。上图是很多车在画面中,我们分割出其中最重要的驾驶员。他们虽然个体很小,使用我们的方法也能比较准确地找到了他们。
在上图所示复杂雨天打伞排队的图像里,哪怕有些人被遮挡了一半或者三分之二,还有小朋友个头比较小的,同样都可以把他们找到分割出来。其它的物品还包括背包、雨伞等。后面还有很多例子不具体介绍了。
最后我想说的是,语义分割和个体分割都是计算机视觉里最有挑战性的问题。它们的重要性不言而喻,可以提供给很多应用所需的工具。它们就是我之前所说的背景视觉。真正设计开发出里面的算法都是不容易的。所以,科研做事情要耐得住辛苦和长时间的失败。但是一旦成功,一个算法就能够帮助这个领域之外的很多应用,包括医学图像的分析、工业图像的分析和日常图像的理解等。
-
机器视觉
+关注
关注
161文章
4343浏览量
120106 -
人工智能
+关注
关注
1791文章
46850浏览量
237539
原文标题:CCAI2018演讲实录丨贾佳亚:大规模图像理解、分割新进展
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
先进封装中互连工艺凸块、RDL、TSV、混合键合的新进展
揭秘超以太网联盟(UEC)1.0 规范最新进展(2024Q4)
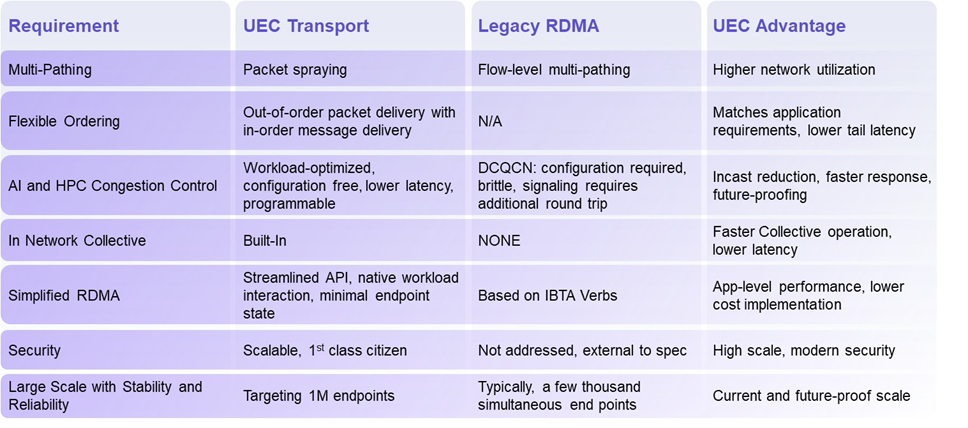
Qorvo在射频和电源管理领域的最新进展
智能优化的自动点焊控制系统:电源技术新进展与应用实践
芯片和封装级互连技术的最新进展
5G新通话技术取得新进展
开放原子开源生态大会OpenHarmony生态主题演讲报名开启
图像语义分割的实用性是什么
图像分割与语义分割中的CNN模型综述
机器人视觉技术中常见的图像分割方法
广东的5G-A、信号升格和低空经济,又有新进展!

百度首席技术官王海峰解读文心大模型的关键技术和最新进展

清华大学在电子鼻传感器仿生嗅闻方向取得新进展





 工商网监
工商网监
评论