 深入解读人工智能、机器学习和认知计算
深入解读人工智能、机器学习和认知计算
人工智能的发展曾经经历过几次起起伏伏,近来在深度学习技术的推动下又迎来了一波新的前所未有的高潮。近日,IBM 官网发表了一篇概述文章,对人工智能技术的发展过程进行了简单梳理,同时还图文并茂地介绍了感知器、聚类算法、基于规则的系统、机器学习、深度学习、神经网络等技术的概念和原理。
人类对如何创造智能机器的思考从来没有中断过。期间,人工智能的发展起起伏伏,有成功,也有失败,以及其中暗藏的潜力。今天,有太多的新闻报道是关于机器学习算法的应用问题,从癌症检查预测到图像理解、自然语言处理,人工智能正在赋能并改变着这个世界。
现代人工智能的历史具备成为一部伟大戏剧的所有元素。在最开始的 1950 年代,人工智能的发展紧紧围绕着思考机器和焦点人物比如艾伦·图灵、冯·诺伊曼,迎来了其第一次春天。经过数十年的繁荣与衰败,以及难以置信的高期望,人工智能及其先驱们再次携手来到一个新境界。现在,人工智能正展现着其真正的潜力,深度学习、认知计算等新技术不断涌现,且不乏应用指向。
本文探讨了人工智能及其子领域的一些重要方面。下面就先从人工智能发展的时间线开始,并逐个剖析其中的所有元素。
现代人工智能的时间线
1950 年代初期,人工智能聚焦在所谓的强人工智能,希望机器可以像人一样完成任何智力任务。强人工智能的发展止步不前,导致了弱人工智能的出现,即把人工智能技术应用于更窄领域的问题。1980 年代之前,人工智能的研究一直被这两种范式分割着,两营相对。但是,1980 年左右,机器学习开始成为主流,它的目的是让计算机具备学习和构建模型的能力,从而它们可在特定领域做出预测等行为。
图 1:现代人工智能发展的时间线
在人工智能和机器学习研究的基础之上,深度学习在 2000 年左右应运而生。计算机科学家在多层神经网络之中使用了新的拓扑学和学习方法。最终,神经网络的进化成功解决了多个领域的棘手问题。
在过去的十年中,认知计算(Cognitive computing)也出现了,其目标是打造可以学习并与人类自然交互的系统。通过成功地击败 Jeopardy 游戏的世界级选手,IBM Watson 证明了认知计算的价值。
在本文中,我将逐一探索上述的所有领域,并对一些关键算法作出解释。
基础性人工智能
1950 年之前的研究提出了大脑是由电脉冲网络组成的想法,正是脉冲之间的交互产生了人类思想与意识。艾伦·图灵表明一切计算皆是数字,那么,打造一台能够模拟人脑的机器也就并非遥不可及。
上文说过,早期的研究很多是强人工智能,但是也提出了一些基本概念,被机器学习和深度学习沿用至今。
图 2:1950 - 1980 年间人工智能方法的时间线
人工智能搜索引擎
人工智能中的很多问题可以通过强力搜索(brute-force search)得到解决。然而,考虑到中等问题的搜索空间,基本搜索很快就受影响。人工智能搜索的最早期例子之一是跳棋程序的开发。亚瑟·塞缪尔(Arthur Samuel)在 IBM 701 电子数据处理机器上打造了第一款跳棋程序,实现了对搜索树(alpha-beta 剪枝)的优化;这个程序也记录并奖励具体行动,允许应用学习每一个玩过的游戏(这是首个自我学习的程序)。为了提升程序的学习率,塞缪尔将其编程为自我游戏,以提升其游戏和学习的能力。
尽管你可以成功地把搜索应用到很多简单问题上,但是当选择的数量增加时,这一方法很快就会失效。以简单的一字棋游戏为例,游戏一开始,有 9 步可能的走棋,每 1 个走棋有 8 个可能的相反走棋,依次类推。一字棋的完整走棋树包含 362,880 个节点。如果你继续将这一想法扩展到国际象棋或者围棋,很快你就会发展搜索的劣势。
感知器
感知器是单层神经网络的一个早期监督学习算法。给定一个输入特征向量,感知器可对输入进行具体分类。通过使用训练集,网络的权重和偏差可为线性分类而更新。感知器的首次实现是 IBM 704,接着在自定义硬件上用于图像识别。

图 3:感知器与线性分类
作为一个线性分类器,感知器有能力解决线性分离问题。感知器局限性的典型实例是它无法学习专属的 OR (XOR) 函数。多层感知器解决了这一问题,并为更复杂的算法、网络拓扑学、深度学习奠定了基础。
聚类算法
使用感知器的方法是有监督的。用户提供数据来训练网络,然后在新数据上对该网络进行测试。聚类算法则是一种无监督学习(unsupervised learning)方法。在这种模型中,算法会根据数据的一个或多个属性将一组特征向量组织成聚类。
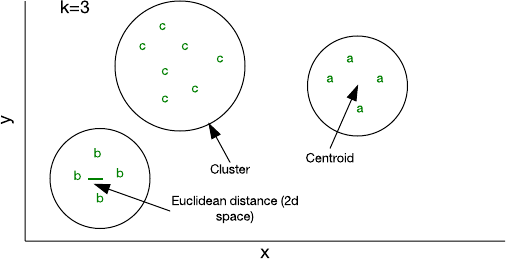
图 4:在一个二维特征空间中的聚类
你可以使用少量代码就能实现的最简单的聚类算法是 k-均值(k-means)。其中,k 表示你为样本分配的聚类的数量。你可以使用一个随机特征向量来对一个聚类进行初始化,然后将其它样本添加到其最近邻的聚类(假定每个样本都能表示一个特征向量,并且可以使用 Euclidean distance 来确定「距离」)。随着你往一个聚类添加的样本越来越多,其形心(centroid,即聚类的中心)就会重新计算。然后该算法会重新检查一次样本,以确保它们都在最近邻的聚类中,最后直到没有样本需要改变所属聚类。
尽管 k-均值聚类相对有效,但你必须事先确定 k 的大小。根据数据的不同,其它方法可能会更加有效,比如分层聚类(hierarchical clustering)或基于分布的聚类(distribution-based clustering)。
决策树
决策树和聚类很相近。决策树是一种关于观察(observation)的预测模型,可以得到一些结论。结论在决策树上被表示成树叶,而节点则是观察分叉的决策点。决策树来自决策树学习算法,其中数据集会根据属性值测试(attribute value tests)而被分成不同的子集,这个分割过程被称为递归分区(recursive partitioning)。
考虑下图中的示例。在这个数据集中,我可以基于三个因素观察到某人是否有生产力。使用一个决策树学习算法,我可以通过一个指标来识别属性(其中一个例子是信息增益)。在这个例子中,心情(mood)是生产力的主要影响因素,所以我根据 Good Mood 一项是 Yes 或 No 而对这个数据集进行了分割。但是,在 Yes 这边,还需要我根据其它两个属性再次对该数据集进行切分。表中不同的颜色对应右侧中不同颜色的叶节点。
图 5:一个简单的数据集及其得到的决策树
决策树的一个重要性质在于它们的内在的组织能力,这能让你轻松地(图形化地)解释你分类一个项的方式。流行的决策树学习算法包括 C4.5 以及分类与回归树(Classification and Regression Tree)。
基于规则的系统
最早的基于规则和推理的系统是 Dendral,于 1965 年被开发出来,但直到 1970 年代,所谓的专家系统(expert systems)才开始大行其道。基于规则的系统会同时存有所需的知识的规则,并会使用一个推理系统(reasoning system)来得出结论。
基于规则的系统通常由一个规则集合、一个知识库、一个推理引擎(使用前向或反向规则链)和一个用户接口组成。下图中,我使用了知识「苏格拉底是人」、规则「如果是人,就会死」以及一个交互「谁会死?」

图 6:基于规则的系统
基于规则的系统已经在语音识别、规划和控制以及疾病识别等领域得到了应用。上世纪 90 年代人们开发的一个监控和诊断大坝稳定性的系统 Kaleidos 至今仍在使用。
机器学习
机器学习是人工智能和计算机科学的一个子领域,也有统计学和数学优化方面的根基。机器学习涵盖了有监督学习和无监督学习领域的技术,可用于预测、分析和数据挖掘。机器学习不限于深度学习这一种。但在这一节,我会介绍几种使得深度学习变得如此高效的算法。
图 7:机器学习方法的时间线
反向传播
神经网络的强大力量源于其多层的结构。单层感知器的训练是很直接的,但得到的网络并不强大。那问题就来了:我们如何训练多层网络呢?这就是反向传播的用武之地。
反向传播是一种用于训练多层神经网络的算法。它的工作过程分为两个阶段。第一阶段是将输入传播通过整个神经网络直到最后一层(称为前馈)。第二阶段,该算法会计算一个误差,然后从最后一层到第一层反向传播该误差(调整权重)。

图 8:反向传播示意图
在训练过程中,该网络的中间层会自己进行组织,将输入空间的部分映射到输出空间。反向传播,使用监督学习,可以识别出输入到输出映射的误差,然后可以据此调整权重(使用一个学习率)来矫正这个误差。反向传播现在仍然是神经网络学习的一个重要方面。随着计算资源越来越快、越来越便宜,它还将继续在更大和更密集的网络中得到应用。
卷积神经网络
卷积神经网络(CNN)是受动物视觉皮层启发的多层神经网络。这种架构在包括图像处理的很多应用中都有用。第一个 CNN 是由 Yann LeCun 创建的,当时 CNN 架构主要用于手写字符识别任务,例如读取邮政编码。
LeNet CNN 由好几层能够分别实现特征提取和分类的神经网络组成。图像被分为多个可以被接受的区域,这些子区域进入到一个能够从输入图像提取特征的卷积层。下一步就是池化,这个过程降低了卷积层提取到的特征的维度(通过下采样的方法),同时保留了最重要的信息(通常通过最大池化的方法)。然后这个算法又执行另一次卷积和池化,池化之后便进入一个全连接的多层感知器。卷积神经网络的最终输出是一组能够识别图像特征的节点(在这个例子中,每个被识别的数字都是一个节点)。使用者可以通过反向传播的方法来训练网络。
图 9.LeNet 卷积神经网络架构
对深层处理、卷积、池化以及全连接分类层的使用打开了神经网络的各种新型应用的大门。除了图像处理之外,卷积神经网络已经被成功地应用在了视频识别以及自然语言处理等多种任务中。卷积神经网络也已经在 GPU 上被有效地实现,这极大地提升了卷积神经网络的性能。
长短期记忆(LSTM)
记得前面反向传播中的讨论吗?网络是前馈式的训练的。在这种架构中,我们将输入送到网络并且通过隐藏层将它们向前传播到输出层。但是,还存在其他的拓扑结构。我在这里要研究的一个架构允许节点之间形成直接的回路。这些神经网络被称为循环神经网络(RNN),它们可以向前面的层或者同一层的后续节点馈送内容。这一特性使得这些网络对时序数据而言是理想化的。
在 1997 年,一种叫做长短期记忆(LSTM)的特殊的循环网络被发明了。LSTM 包含网络中能够长时间或者短时间记忆数值的记忆单元。
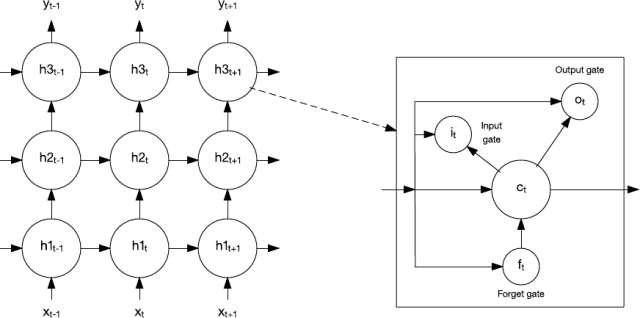
图 10. 长短期记忆网络和记忆单元
记忆单元包含了能够控制信息流入或者流出该单元的一些门。输入门(input gate)控制什么时候新的信息可以流入记忆单元。遗忘门(forget gate)控制一段信息在记忆单元中存留的时间。最后,输出门(output gate)控制输出何时使用记忆单元中包含的信息。记忆单元还包括控制每一个门的权重。训练算法(通常是通过时间的反向传播(backpropagation-through-time),反向传播算法的一种变体)基于所得到的误差来优化这些权重。
LSTM 已经被应用在语音识别、手写识别、语音合成、图像描述等各种任务中。下面我还会谈到 LSTM。
深度学习
深度学习是一组相对新颖的方法集合,它们从根本上改变了机器学习。深度学习本身不是一种算法,但是它是一系列可以用无监督学习实现深度网络的算法。这些网络是非常深层的,所以需要新的计算方法来构建它们,例如 GPU,除此之外还有计算机集群。
本文目前已经介绍了两种深度学习的算法:卷积神经网络和长短期记忆网络。这些算法已经被结合起来实现了一些令人惊讶的智能任务。如下图所示,卷积神经网络和长短期记忆已经被用来识别并用自然语言描述图片或者视频中的物体。
图 11. 结合卷积神经网络和长短期记忆来进行图像描述
深度学习算法也已经被用在了人脸识别中,也能够以 96% 的准确率来识别结核病,还被用在自动驾驶和其他复杂的问题中。
然而,尽管运用深度学习算法有着很多结果,但是仍然存在问题需要我们去解决。一个最近的将深度学习用于皮肤癌检测的应用发现,这个算法比经过认证的皮肤科医生具有更高的准确率。但是,医生可以列举出导致其诊断结果的因素,却没有办法知道深度学习程序在分类的时候所用的因素。这被称为深度学习的黑箱问题。
另一个被称为 Deep Patient 的应用,在提供病人的病例时能够成功地预测疾病。该应用被证明在疾病预测方面比医生还做得好——即使是众所周知的难以预测的精神分裂症。所以,即便模型效果良好,也没人能够深入到这些大型神经网络去找到原因。
认知计算
人工智能和机器学习充满了生物启示的案例。尽管早期的人工智能专注于建立模仿人脑的机器这一宏伟目标,而现在,是认知计算正在朝着这个目标迈进。
认知计算建立在神经网络和深度学习之上,运用认知科学中的知识来构建能够模拟人类思维过程的系统。然而,认知计算覆盖了好多学科,例如机器学习、自然语言处理、视觉以及人机交互,而不仅仅是聚焦于某个单独的技术。
认知学习的一个例子就是 IBM 的 Waston,它在 Jeopardy 上展示了当时最先进的问答交互。IBM 已经将其扩展在了一系列的 web 服务上了。这些服务提供了用于一些列应用的编程接口来构建强大的虚拟代理,这些接口有:视觉识别、语音文本转换(语音识别)、文本语音转换(语音合成)、语言理解和翻译、以及对话引擎。
继续前进
本文仅仅涵盖了关于人工智能历史以及最新的神经网络和深度学习方法的一小部分。尽管人工智能和机器学习经历了很多起起伏伏,但是像深度学习和认知计算这样的新方法已经明显地提升了这些学科的水平。虽然可能还无法实现一个具有意识的机器,但是今天确实有着能够改善人类生活的人工智能系统。
-
人工智能
+关注
关注
1791文章
47279浏览量
238510 -
机器学习
+关注
关注
66文章
8418浏览量
132643
原文标题:IBM长文解读人工智能、机器学习和认知计算
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
嵌入式和人工智能究竟是什么关系?
具身智能与机器学习的关系
人工智能、机器学习和深度学习存在什么区别






 工商网监
工商网监
评论