 PCI标准的局限性及PCI Express系统的解决方案分析
PCI标准的局限性及PCI Express系统的解决方案分析
基于ISA(工业标准架构)总线的首个扩展卡最初在1978年问世,由于要求提升系统整体性能,MCA(微通道架构)等总线系统或是扩展的ISA总线随后也相继出现。鉴于数据通道宽度(主要是8或16位)和总线架构的速度问题,许多标准都限制了带宽。此外,万一错误配置了总线,很难确定差错在哪里,因此调试这个系统时就会遇到各种问题。根据这些旧的总线标准的经验,新的标准PCI(外设部件互连)最终得以确定。本文将探讨PCI标准的局限性,以及下一代PCI Express是如何以节约成本的方式得以实现的。
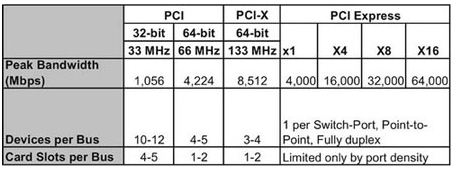
为了克服旧标准的上述局限,1992年人们建立了PCI。其目的是构建一个更高带宽的标准,有即插即用功能和更稳健的协议。PCI协议支持差错校验,通过与计算机的BIOS(基本输入输出系统)通信实现即插即用功能,并通过标准的控制/状态软件接口就地址范围或PCI插卡功能等信息进行交换。如果出现地址范围重叠等差错,计算机本身可以提供一些反馈。一个基本的32位33MHz的PCI系统,可支持的传输速率高达132MBps。但是,这个架构也有一些限制因素。总线是单向的(发起方和被请求的目标设备不能在同一时间进行通信),且几个卡要共享一条总线。如果一张卡正在传输数据,所有其他的可访问总线的部件必须等待。此外,在系统中无法处理PCI带宽的低性能卡将进行“重试”请求,以确保有更多时间来处理数据。这就大大降低了整个系统的带宽。PCI的另一个限制是各种应用对所需求带宽不断增加,特别是在视频、通信和总线领域。图1列出的一些应用,已经接近或超过了理论上的PCI带宽132MBps。

图1:各种应用的带宽需求对比理论上PCI提供的132MBps。
PCI还有其他一些缺点,如限制只能有5个部件访问总线。由于PCI总线特殊的无端接总线的反射,电路板的设计也更加困难。数据路径宽度为32或64位的并行线也对时序有苛刻的要求。
根据以往经验,PCI-SIG(PCI特别兴趣小组)与行业内的领先公司合作,定义了PCI的下一代标准。新标准最初被称为3G IO(第三代输入输出),后来改名为大家熟悉的PCI Express。PCI Express的首个规范于2002年4月公布,其解决了原有PCI标准的所有限制因素。为了克服无端接的大量并行总线并增加带宽,PCI Express转变为运行速率2.5Gbps的串行链路,提供两个方向同时进行的2Gbps的原始数据率。为了满足更高的带宽要求,规范允许使用几个并行的“通道”。因此对于目前计算机的低带宽应用,有很多x1和x4通道;对于有高带宽的要求,例如显卡,则有x16的插槽。
由于PCI Express规范使用基于层的协议,类似于OSI的层次模型,它很容易改变物理层和保留上层协议。这种做法已被最近发布的PCI Express 2.0规范所采纳,使得链路速度高达5Gbps。然而,大多数新的设计开始仍然是基于PCI Express 1.1版本的2.5Gbps。
一个PCI Express系统可以用几个部件组成。所有的系统都需要有一个根联合体(Root Complex)对整个系统进行管理。交换设备(Switch)是用来将几个卡连接到另一个PCI Express链路,“端设备”则代表了用户应用。桥接是端设备的特殊形式,可以将旧的PCI应用连接至PCI Express总线。FPGA主要用于端设备或桥接应用。
在PCI Express应用中FPGA起着重要的作用,主要有三种设计方法:
*PCI-Express至PCI桥和FPGA
*外部的PCI-Express PHY和FPGA
*PCI-Express的PHY集成在FPGA之中
第一种使用PCI-Express至PCI桥的方法,优点是可以重用旧的PCI设计,但由于额外的桥接单元,成本很高。在桥和FPGA之间,这个应用仍然被PCI的缺点所限制,在成本方面处于不利地位。
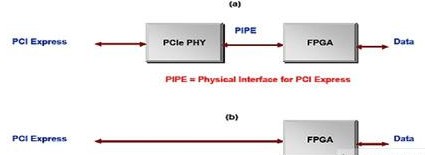
图2A和2B
当仅需纯粹的PCI Express接口,而不需要其它逻辑时,外部的PCI Express PHY和FPGA(图2A)相结合可能极具吸引力。利用被称为PIPE的并行接口,PCI Express PHY可以连接到FPGA。虽然PIPE接口被认为是一个标准,但不同厂商在实现方面有着细微的差别,因此物理层芯片就不容易互换。此外,工业级的外部PCI Express PHY芯片也不太容易买到,要不就是价格昂贵。此外,许多应用程序使用领先的器件,可用的领先的PCI Express PHY芯片也是很有限的。
因此,如果只有一个PCI Express接口链路,而且在FPGA中只要少量的额外逻辑(除了温度范围的限制,以及可用的领先器件),这种做法颇有意义。对于所有其他应用,最好是考虑一个整合的解决方案,如图2B所示。
如果采用整合的解决方案,首个挑战是寻找一个低成本的器件。在过去,PCI Express需要的串行链路一般只在高端昂贵的FPGA中才有。然而,今天许多应用需要较低成本的解决方案。中档LatticeECP2M,或最近推出的LatticeECP3 FPGA系列,拥有适合这种应用的一些功能。这两种器件都集成了可用于实现PCI Express x1或x4的串行通道。除了低成本优势外,与高端FPGA解决方案相比,这两类器件的功耗也非常低。该“节能方案”使系统工程师能够降低功耗,因此只需要使用较小供电电源。图3展示了近期推出的ECP3 FPGA系列的结构图。
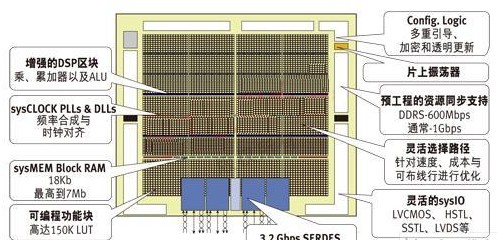
图3:LatticeECP3中档FPGA框图,内有集成的SERDES模块。
利用这些FPGA的另一个优点是它们能够处理PCI Express使用的扩频时钟。许多其他的“单芯片”解决方案推荐使用外部的PLL和去除抖动来处理时钟,这意味着电路板上会有两到三个额外的器件。这些器件也可用在工业温度范围。
既然这些FPGA的串行链路只能实现物理层的SERDES部分,所以需要额外的逻辑来实现完整的PCS。这由软IP核来完成,它可以配置成x1或x4 PCI Express端点。莱迪思的ispLEVER设计软件包括一个称为IPexpress的工具,通过GUI来配置功能,如PLL、存储器等,还有软IP。PCI Express核可从莱迪思网站上下载,使用IP Express进行配置并产生编程文件。即使没有有效许可证,也可以运行这个应用数小时,从而获得一个全面的系统*估。
为了符合系统的需要,配置PCI Express核的某些功能是非常重要的。例如, PCI Express提供不同的有效载荷大小。有效载荷的规模越大,核中需要的FIFO也越大。为了节约资源,可以通过IPexpress来选择针对PCI Express核的正确有效载荷的大小。还有一些应加以调整的其他参数,以针对系统要求优化FPGA的利用率。
在许多项目开发中,只有在开发后期才能得到样机电路板。为了熟悉PCI Express的协议,可从莱迪思获取PCI Express设计套件。该套件包含了电路板,可用于x1或x4的插槽,并有一些演示配置:
* 基本方法
o 用户访问内存和寄存器
o 在电脑上运行演示与在电路板上的PCIe IP核之间提供简单的互动
* 吞吐量
o 在PCIe核和SERDES之间演示和测量带宽性能
o 使用DMA在PC机内存和PCI Express卡之间传送数据
设计人员可以选择使用其中一个准备好的编程文件,在30分钟内构建一个完整的演示。套件不仅提供了硬件设计文件,而且还提供驱动程序和运行在PC上的应用程序,这样就为设计人员的应用提供了一个良好的起点。图4展示了莱迪思的一个完整的PCI Express演示设计。
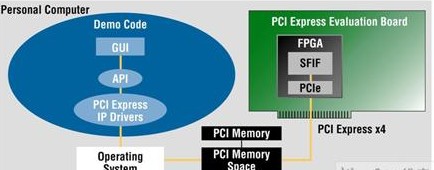
图4:Lattice PCI Express的演示。
用协议分析仪和示波器可以调试系统。但是,利用功能或者RTL级仿真时,设计人员已经可以找到许多问题。
系统调试的三个主要方法:
* 串行环回
* 激励发生器和测试器
* 总线功能模型
莱迪思的PCI Express核包含一个简单的采用串行环回的测试平台。借助一些来自测试平台的互动建立PCI Express链路,并发送一些数据包。这是仿真设计的非常基本的方法。
一个更先进的方法是使用激励发生器和测试器。FPGA中串行链路的仿真模型被一个模型所取代,后者生成数据包,并检查FPGA内的逻辑响应。
最全面且成本昂贵的方法是建立总线功能模型。有几个供应商提供PCI Express的仿真模型。根据总线功能模型,设计人员可以测试应用程序,以及FPGA的串行链路与整个系统的互动。
-
FPGA
+关注
关注
1630文章
21791浏览量
605092 -
PCI
+关注
关注
4文章
671浏览量
130402 -
总线
+关注
关注
10文章
2899浏览量
88277
发布评论请先 登录
相关推荐
PCI Express标准技术性概述
针对可编程PCI Express解决方案的评估方法
PCI Express插槽,什么是PCI Express插槽
PCI-Express插槽
采用中档FPGA设计面向PCI Express系统的解决方案
PCI Express总线
LSI推出PCI Express固态存储解决方案样片
PCI Express解决方案的介绍
如何创建和使用Xilinx的UltraScale PCI Express解决方案






 工商网监
工商网监
评论