 Markov的各种预测模型的原理与优缺点介绍
Markov的各种预测模型的原理与优缺点介绍

建立有效的用户浏览预测模型,对用户的浏览做出准确的预测,是导航工具实现对用户浏览提供有效帮助的关键。
在浏览预测模型方面,很多学者都进行了卓有成效的研究。AZER提出了基于概率模型的预取方法,根据网页被连续访问的概率来预测用户的访问请求。SARUKKAI运用马尔可夫链进行访问路径分析和链接预测,在此模型中,将用户访问的网页集作为状态集,根据用户访问记录,计算出网页间的转移概率,作为预测依据。SCHECHTER构造用户访问路径树,采用最长匹配方法,寻找与当前用户访问路径匹配的历史路径,预测用户的访问请求。XU Cheng Zhong等引入神经网络实现基于语义的网页预取。徐宝文等利用客户端浏览器缓冲区数据,挖掘其中蕴含的兴趣关联规则,预测用户可能选择的链接。朱培栋等人按语义对用户会话进行分类,根据会话所属类别的共同特征,预测用户可能访问的文档。
在众多的浏览模型中,Markov模型是一种简单而有效的模型。Markov模型最早是ZUKERMAN等人于1999年提出的一种用途十分广泛的统计模型,它将用户的浏览过程抽象为一个特殊的随机过程——齐次离散Markov模型,用转移概率矩阵描述用户的浏览特征,并基于此对用户的浏览进行预测。之后,BOERGES等采用了多阶转移矩阵,进一步提高了模型的预测准确率。在此基础上,SARUKKAI建立了一个实验系统[9],实验表明,Markov预测模型很适合作为一个预测模型来预测用户在Web站点上的访问模式。
1 Markov模型
1.1 Markov模型
Markov预测模型对用户在Web上的浏览过程作了如下的假设。
假设1(用户浏览过程假设):假设所有用户在Web上的浏览过程是一个特殊的随机过程——齐次的离散Markov模型。即设离散随机变量的值域为Web空间中的所有网页构成的集合,则一个用户在Web中的浏览过程就构成一个随机变量的取值序列,并且该序列满足Markov性。
一个离散的Markov预测模型可以被描述成三元组,S代表状态空间;A是转换矩阵,表示从一个状态转换到另一个状态的概率;B是S中状态的初始概率分布。其中S是一个离散随机变量,值域为{x1,x2,…xn},其中每个xi对应一个网页,称为模型的一个状态。
Markov预测模型是一个典型的无后效性随机过程,也就是说模型在时刻t的状态只与它的前一个时刻t-1的状态条件相关,与以前的状态独立。即:

王实等提出一种新的基于隐马尔可夫模型的兴趣迁移模式发现方法,并利用用户迁移模式间的关联规则来发现兴趣迁移模式。而借助隐马尔可夫模型, 挖掘蕴涵在用户访问路径中的信息需求概念, 以此进行预取页面的评价, 也可以实现基于语义的网页预取。
隐Markov模型尽管考虑了用户兴趣,但和简单的Markov模型一样,存在一定的不足:用户访问序列串长是动态时变的,采用固定阶数的传统Markov链模型并不能准确地对用户的访问行为建模。
2.2 多Markov模型
虽然用户在Web空间的浏览过程是一个受浏览目的、文化背景、兴趣爱好等多种因素影响的复杂过程,有很多差异,然而观察大量用户的浏览过程可以发现,某些用户的浏览过程表现出相同或相近的特点,如他们浏览的网页基本相同,浏览各个网页的顺序相似等,这一现象引发了对Web用户分类的研究。通过对用户分类,同一类别的用户用同一个模型来描述它,而不同类别的用户其浏览过程差别较大,用不同的模型来描述他们的特征则更为合理。
假设2(用户分类假设):假设根据用户在Web空间的浏览特点,可以将所有用户分为K类。如果用C={c1, c2,…,ck}表示用户的类别,则任意一个用户属于类别ck的概率为P(C=ck),而且有:

上述模型称为二步Markov模型,它的核心任务是建立一个与一阶Markov模型的转移概率矩阵同规模的转移概率矩阵。矩阵的行元素代表用户浏览的上一个网页,列元素代表用户下一步可能浏览的网页。通过该矩阵可以根据用户上一步浏览的网页来预测下一步要浏览的网页。

在多Markov模型方面,刘业政等提出可变多阶Markov链模型VMOMC。VMOMC将用推荐目标网页概率值度量的可变多阶Markov链并行组合,组合模型中采用遗传算法确定各单阶Markov链模型的最优权重。陈佳提出了基于混合模型的一种挖掘用户群在页面上兴趣分布程度的模式发现,计算用户群从一个页面到另外一个页面的导航路径模式的概率大小,可得到大量的用户对所访问Web的兴趣及导航模式,从而预测用户的浏览路径。
2.4 结构相关性模型
有研究表明,用户在进行Web浏览的绝大部分时间里都是从当前页面中挑选一个链接继续浏览;在用户将来访问的网页中,46%能在最近3个网页的链接中找到,75%能在所有历史网页的链接中找到 。因此,可以认为用户将来的可能请求大部分存在于由当前页面上所有链接组成的集合中。基于结构相关性的一阶Markov模型包括以下三部分:

通过遍历用户访问序列的节点,可以得到用户的状态空间和转移情况,并最终建立上述模型。
结合页面内容及站点结构来调整状态转移矩阵,以获得更精确的预取结果,提高Web 服务的质量。而利用频繁访问模式树存储Markov链,能够大幅减小存储空间。
3 进一步研究的问题
尽管现有的Markov 浏览预测模型在预测准确率、覆盖率方面已取得较满意的成果,但浏览预测问题的实际应用背景中的一些特殊要求使得这一领域仍存在一些需要进一步研究的问题。这些问题包括:
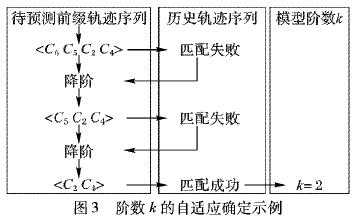
(1)Markov转移概率矩阵的处理。该模型的存储空间主要用于保存状态转移概率矩阵,所以其存储空间的复杂度是网页数目n的平方,即为0(n)。由于n的值一般都比较大,存储复杂率较高。同时为了提高Web预取的命中率,常常联合多个Markov链模型,即用到了多阶状态转移矩阵,使得存储复杂率成倍提高。因此如何存储及处理Markov模型的概率矩阵、降低复杂度是急需解决的问题。此外,在很多情况下状态转移矩阵是稀疏矩阵,采用什么样的数据结构来存储这样的矩阵也是需要研究的课题。
(2)混合Markov模型的求解问题。混合Markov模型在预测用户的浏览行为方面越来越受到学者的重视。有效的模型求解方法,能大大提高模型的效率。虽有学者进行了有益的探索,但这方面的工作仍需要更多学者的参与。
(3)在实际浏览预测问题中,Markov的随机统计方法与其他方法,如神经网络、贝叶斯网络、聚类、关联规则、遗传算法等相结合能获得较高的预测准确率。
(4)用户在Web空间的浏览过程是一个受浏览目的、
文化背景、兴趣爱好等多种因素影响的复杂动态过程,如能有效地度量用户的浏览兴趣,并及时发现用户的兴趣迁移,对于提高预测准确率非常重要。此外,随着无线网络的普及,怎样预测无线网络环境下用户的浏览行为,是研究人员面临的又一个课题。
全文概述了基于Markov的各种预测模型,分析了各个模型的原理及优缺点,指出了今后的研究方向。
-
神经网络
+关注
关注
42文章
4845浏览量
108373 -
浏览器
+关注
关注
1文章
1043浏览量
37215 -
网页
+关注
关注
0文章
75浏览量
19896
发布评论请先 登录
卫星信道三状态Markov模型设计
如何使用Adaboost Markov模型进行移动用户位置预测方法的详细资料说明



评论