 采用HDFS技术的云存储的应用解决方案
采用HDFS技术的云存储的应用解决方案
海量的高校信息资源需要整合,这是当前不争的事实,因为高校信息资源存在着资源分布不均衡、更新维护成本高、共享程度低和安全性差等一系列问题。整合需要解决的首要问题就是信息的合理存储,以便实现对其高效、安全的访问。与传统的存储方式相比,云存储很好地解决了这个问题。
云存储(Cloud Storage)是在云计算(Cloud Computing)概念上延伸和发展出来的一个新的概念,它是指通过集群应用、网格技术或分布式文件系统等功能,将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。
1 存储方式的比较
高可靠性:云存储实现对信息的分布式存储,信息被切分为多个数据块分散存储在云中的节点中,实现了多副本备份机制,因此安全性要远高于传统的单一甚至带有镜像服务器的信息存储方式。
访问的高效性:云中的控制节点通过"心跳检测"不断地监视存储节点的状态,当发现存储节点已经失效时,控制节点能够将工作负载交给那些运行正常的存储节点来完成。同时,由于云中的数据是分布式的存储,能够很好地分担存储和访问的压力,这些都使得云存储具有很高访问的效率。
存储成本低:原先的信息资源的存储一般使用专业的存储设备,价格不菲,使得资源存储的成本也随之提高。而云中的存储设备都是廉价的商业机,跟单一的大容量专业存储设备相比较,存储容量更大,存储成本更低。
管理便捷:云存储能够在软件层做到自动容错而不依赖硬件本身的容错,而且将信息资源存储在云中,有利于对资源进行统一的管理,提高资源的使用率。
另外,云存储还具有超强的可扩展性、不受具体地理位置所限、基于商业组件、按照使用收费(如每G收15美分)、可跨不同应用等。所有这些充分体现了云存储这种方式的优越性。
2 基于HDFS的云存储
2.1 HDFS的引入
目前各大公司都有自己的云存储产品,如微软公司的"Windows Live Sky Drive"网络移动硬盘服务、Google公司的"Google Stora ge"的云计算存储服务、亚马逊的Amazon webservices等。
在众多的云存储产品技术中,HDFS技术可以实施运行在普通的PC集群上,有效降低存储成本,该技术是Google文件系统(GFS)的开源实现,是分布式计算开源框架Hadoop的底层实现,Hadoop是Google集群系统的一个开源项目总称,Google集群系统是使用低成本的成熟技术构建的一个稳定、高性能、高可用性、可扩展的系统。Hadoop平台虽然是一项新兴的技术,但它的发展非常迅速,已开始被应用在企业、高校、科研机构等各个行业。文中重点研究HDFS云存储在高校信息整合中是如何应用的。
2.2 HDFS的理论剖析
Hadoop文件系统(Hadoop Distributed File System,HDFS)虽然和现有的文件系统有相似之处,也是可以运行在普通的硬件之上的分布式文件系统,但是HDFS具有高容错性,可以部署在低成本的硬件之上,可以以流的方式访问文件数据,从而高吞吐量地对应用程序进行访问,这些还是和一般的文件系统有区别的。图1是HDFS体系结构图。
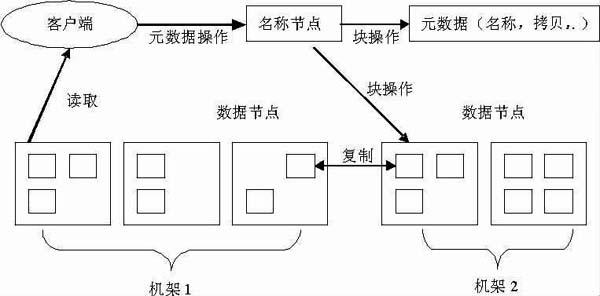
图1 HDFS体系结构图
研究HDFS的体系结构图可以得知,名称节点上保存这控制数据节点信息的元数据。客户端可以通过名称节点对元数据进行操作,也可以直接对数据节点进行读写。HDFS体系结构是个主从结构,这个主从结构常由单个的名称节点和多个数据节点组成,名称节点负责管理文件命名空间和客户端访问的主服务器,而数据节点则负责对存储进行管理,下面来剖析一下体系结构各部分的功能。
2.2.1 名称节点和数据节点的功能
名称节点的功能包括4个方面:一是管理元数据和文件块:二是管理文件系统的命名空间,包括记录文件系统元数据被修改的情况:三是监听客户端和数据节点请求和处理这些请求。客户端事件比较复杂,比如名字空间的创建与删除,文件的创建、删除和修改等,数据节点的事件包括文件块信息变化、心跳响应等:四是心跳检测。所谓心跳检测,就是数据节点会定期将自己的负载情况通过心跳信息向名称节点汇报。
数据节点的功能包括3个方面:一是通过自身服务进程与文件系统客户端打交道,完成数据块的读写;二是周期性的向名称节点发送信号,报告本节点的状态;三是执行数据的流水线复制。
2.2.2 元数据和数据交互
HDFS体系结构中有三种类型的元数据保存在名称节点的内存中,分别是:文件(包含目录)的名字空间、文件到文件块的映射、文件块的位置信息。这种数据结构对于数据访问的效率和安全性都有很大的帮助。
HDFS中数据的交互无外乎数据的读和写,重点设计的对象就是客户端、名称节点和数据节点。客户端首先从名称节点中读取对应的文件块信息,再和数据节点建立连接并获取数据,图2具体描述了数据读取过程。
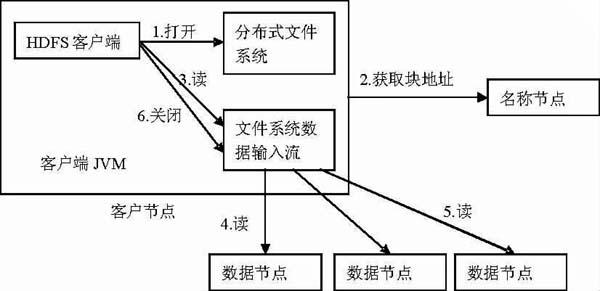
图2HDFS 数据读取过程
HDFS的数据写入过程比读取过程细节上更为复杂一些,但是模型图非常类似。除了数据的读写,维护数据的可用性和一致性也是系统最基本的要求和重要的功能。一般来说,系统通过数据复制、节点故障、数据校验、垃圾回收机制来维护数据的可用性和一致性。
3 HDFS的云存储应用于整合高校信息资源
3.1 系统分析与设计
目前高校信息资源面临着空前的海量数据管理难题,存储数据的成本在不断增加,而且信息的安全性也亟待提高。因此要借用云存储这种新的工作模式来解决这个问题。根据高校的特殊情况,结合云存储的优点,要设计一个成功的云存储案例,需要考虑这么几个方面:
1)低成本海量存储 将数据存储在一般的个人电脑构成的网络中,并进行合理调配,构成一个有机海量存储设备。
2)高效率的访问 数据尽可能的存储在不同的数据节点中,当客户端对信息进行请求时,能高效的回复,并做到并发。
3)安全性高 每个文件都会有多个副本分别存储在多个数据节点上。如果某个数据节点出现问题,不会发生文件丢失的现象。
3.2 系统功能设计
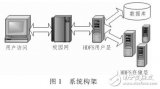
高校相对于云存储系统是一个用户,而高校内部有多个部门,相对于云存储系统的用户高校来说是一个子用户。云存储系统能够创建、管理、维护高校云存储用户;高校云用户能够创建、管理、维护各部门子用户。而子用户才是真正的终端信息存储用户,他们上传、下载、删除数据信息。由于我们的这个系统是基于HDFS的,而一个基本的HDFS由一个NameNode和n个DataNode组成,云存储系统是由多个地方的HDFS存储设备通过应用软件集合起来协同工作,完成外部访问请求。可以将本文描述的分布式文件系统(DFS)抽象成一个三级模型,如图3所示。
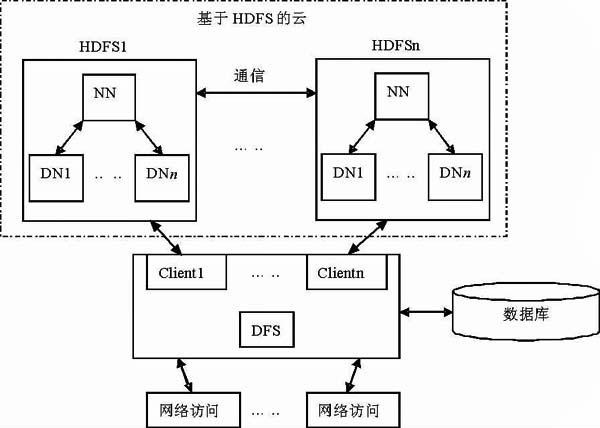
图3 系统结构图
根据系统结构图可以清楚看到本文描述的分布式文件系统(DFS)的业务逻辑模型:终端网络发出信息存取访问请求,DFS通过封装与HDFS通信协议的Client客户端与基于HDFS的云存储系统进行通信,完成对信息的访问。HDFS存储业务以云状分布在网络的各个部分,它具有容量大、性能高、可靠性好、协同优良的特点,正是这些特点,完成了高校信息资源高效访问与存储。
4 结论
基于HDFS的云存储是一种动态可调整、基于互联网的存储解决方案,用户可以通过通用和易用协议和应用程序接口通过网络访问存储目标,这种新技术对最终用户来说很有好处。云存储可以让用户很容易增加存储容量,而且不需要购买、安装和管理任何存储基础设施,却提供了一个完善的备份、容灾数据中心。云存储的成本和易用性优势对高校具有很强的吸引力,发展和应用前景广阔。
-
Google
+关注
关注
5文章
1758浏览量
57428 -
云计算
+关注
关注
39文章
7744浏览量
137222 -
云存储
+关注
关注
7文章
732浏览量
46004
发布评论请先 登录
相关推荐

采用Sun StorEdge技术创建存储解决方案
269私有云服务器的完全解决方案
hadoop hdfs 文件优点
如何用MRAM和NVMe SSD构建未来的云存储的解决方案

HDFS优化面临新挑战,如何按照数据冷热程度进行分层存储
基于HDFS校园云存储平台
应对海量图片存储的分布式存储解决方案





 工商网监
工商网监
评论