 采用FPGA来实现系统定制流量管理
采用FPGA来实现系统定制流量管理
目前硬件高速转发技术的趋势是将整个转发分成两个部分:PE(Protocol Engine,协议引擎)和TM(Traffic Management,流量管理)。其中PE完成协议处理,TM负责完成队列调度、缓存管理、流量整形、QOS等功能,TM与转发协议无关。
随着通信协议的发展及多样化,协议处理部分PE在硬件转发实现方面,普遍采用现有的商用芯片NP(Network Processor,网络处理器)来完成,流量管理部分需要根据系统的需要进行定制或采用商用芯片来完成。在很多情况下NP芯片、TM芯片、交换网芯片无法选用同一家厂商的芯片,这时定制TM成为了成本最低、系统最优化的方案,一般采用FPGA来实现,TM的常规结构如图1所示。
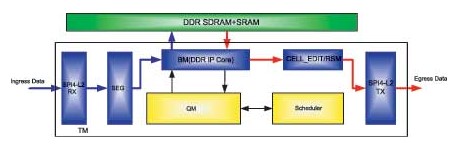
图1 TM的常规结构图
目前主流的TM接口均为SPI4-P2接口形式,SPI4-P2接口信号速率高,TCCS(Chan nel-to-channel skew,数据通道的抖动,包含时钟的抖动)难以控制,在常规情况下很难做到很高的速率。SPI4-P2接口为达到高速率同时避免TCCS问题在很多情况下都对接收端提出了DPA(动态相位调整)的要求。对于SPI4-P2接口形式可直接采用Altera公司的IP Core实现。Altera的主流FPGA均实现了硬件DPA功能,以Stratix II器件为例,在使能DPA的情况下使用SPI4-P2 IP Core可实现16Gb/s的接口数据速率。
SEG模块为数据切分块,根据交换网的数据结构要求,在上交换网的方向上负责把IP包或数据包切分为固定大小的数据块,方便后期的存储调度以及交换网的操作处理,SEG模块可配合使用SPI4-P2 IP Core来实现。与SEG模块对应的是RSM模块,RSM模块将从交换网下来的数据块重新组合成完整的IP包或数据包。
BM(Buffer Management)模块为缓冲管理模块,管理TM的缓冲单元,完成DRAM的存取操作。外部DRAM的控制部分可使用使用DDR SDRAM IP Core实现。
QM模块为队列管理模块,负责完成端口的数据队列管理功能,接收BM模块读写DRAM时的数据入队、出队请求,TM所能支持的数据流的数目、业务类型数目、端口的数目等性能指标在QM模块处体现出来。
Scheduler模块为调度模块,根据数据包类型及优先级和端口分配的带宽进行调度,TM流量整形、QOS等功能通过调度模块实现。
CELL_EDIT模块完成输出数据的封装,把由DRAM中读出的数据封装后发送出去。
在TM中需要基于数据服务策略对于不同服务等级的数据包进行不同的管理策略,同时要保证流媒体的数据包不能乱序,数据包有大有小,经过SEG模块所分割成的数据块的数目也有多有少,这样就必须有一套行之有效的数据结构基于链表的方法管理这些数据。QM模块基于业务、数据流的方式管理队列,包的管理便由BM模块完成。
BM模块中基于包的数据结构方面由两部分构成:BRAM和PRAM。BRAM为数据缓冲区,对应片外的DRAM。BRAM负责存储数据单元,相对于SEG模块切分的数据单元,BRAM内有相应大小的存储单元BCELL与之对应,BCELL在BRAM内以地址空间划分,每个BCELL相同大小,BCELL为BRAM的最小存取单元。在实际系统中基于SEG模块切分的数据单元大小,BCELL一般为64~512B。
PRAM为指针缓冲区,PRAM对应片外的SSRAM。PRAM内部同样以地址空间分为PCELL,PCELL与BCELL一一对应,每一个PCELL对应于一个BCELL,对应的PCELL与BCELL地址相同。
PCELL的地址对应的代表相应单元的BCELL的地址,PCELL中的基本信息是下一跳指针。PRAM与BRAM关系如图2所示。
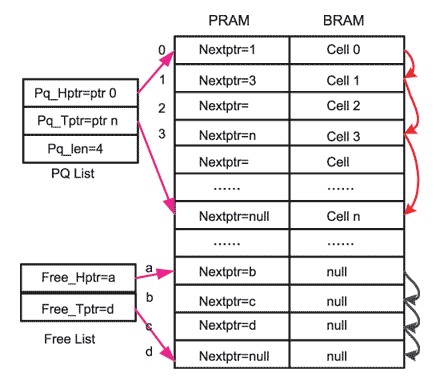
图2 PRAM与BRAM关系图
在PRAM中存在两种链表形式,PQ List代表已经存储的数据包链表。为方便数据读出,PQ List需要记录数据包的第一个数据块地址,即首指针Pq_Hptr,为方便新的数据写入,PQ List需要记录数据包的最后一个数据块地址,即尾指针Pq_Tptr。PQ List同时需要记录该链表的长度作为调度模块进行调度的权值计算使用。
Free List代表空闲的地址队列。为方便地辨识、管理空闲的地址,避免地址冲突,在BM中将所有空闲的地址使用一个链表进行管理。这个链表就是空闲地址队列。空闲地址队列依据系统需求的不同有着不同的形式,一般空闲地址队列的构成和PQ List相似,由空闲地址首指针Free_Hptr和空闲地址尾指针Free_Tptr构成。BM模块的所有操作都围绕着空闲的地址队列Free List进行。
基于BM模块的数据流结构,BM模块一般分为Write Control模块、Free List control模块、Read Control模块、PRAM Control模块、BRAM Control模块。BM的结构如图3所示。
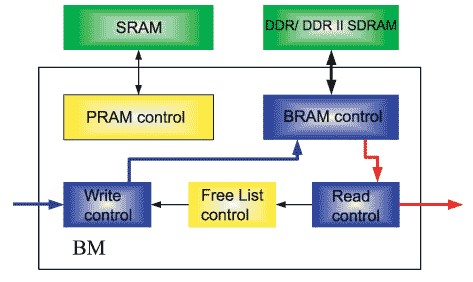
图3 BM结构图
Write Control模块从Free List模块处得到空闲地址,向BRAM Control模块提出写请求,同时更新PRAM中的内容。Free List control模块负责管理空闲地址列表,提供Write Control模块的写BRAM地址及PRAM地址,回收经Read Control模块读出数据块后释放的地址。Read Control模块根据调度器的调度结果,通过BRAM Control模块读出需要发送的数据单元,同时将释放的缓冲单元地址写入空闲地址列表。PRAM Control模块为外部SSRAM的控制模块,可直接使用参考设计完成。BRAM Control模块为外部DRAM控制模块,一般分为Datapath与Controler两个子模块。Datapath模块专门负责数据接口部分,完成DRAM接口的DQ、DQS处理以及相应的延时调整,Controler模块负责完成DRAM的控制需求。
在BM模块中,BRAM的带宽与PRAM的带宽一般为TM的瓶颈。PRAM的带宽主要受限于访问的次数,而BRAM的带宽受限于接口带宽。例如对于一个10G的TM,BRAM的有效带宽必须保证20G,以接口利用率最差只能达到65%计算(考虑SEG模块切分信元出现的N+1问题),需要保证接口带宽达到30G。使用64位的DRAM接口,接口速率不能低于500MB/s,这样对Datapath模块的设计提出了更高的要求。在实际系统中,BRAM主要使用DDR SDRAM、DDR II SDRAM。
当使用Stratix II FPGA,BRAM使用DDR II SDRAM时,测试表明DDR II SDRAM接口速率可达到800MB/s。在常规使用的情况下,DDR II SDRAM接口速率可保证达到667MB/s。对于一个64位的DRAM接口,接口速率可达到42.7GB/s,完全可以满足一个10G的TM系统。
BM模块作为缓冲管理模块,缓冲的基本单元为BCELL,基于对BCELL的管理,对于BM的操作都牵涉到空闲地址队列的操作以及链表的操作。最基本的操作就是写入操作和读出操作。BM模块的写入操作由Write Control模块发起。
对于Write Control模块,有数据单元需要写入,首先向Free List模块申请空闲地址,Free List将首指针a给Write Control模块,作为该数据块的写地址,同时读出首指针a对应在PRAM中的内容,得到下一跳地址b,将下一跳地址b作为新的空闲地址首指针。
PQ List将尾指针n更新为新写入的地址a,同时更新PRAM中n地址的内容,将a作为下一跳添入n地址。基于节省操作周期,NULL的内容保留原值,不再更新。这样,一次BRAM的写入操作需要一次PRAM的读取操作及一次PRAM的写入操作。
QM模块接收调度模块的出队信息,将出队的PQ链表信息传送给BM模块进行读取操作。
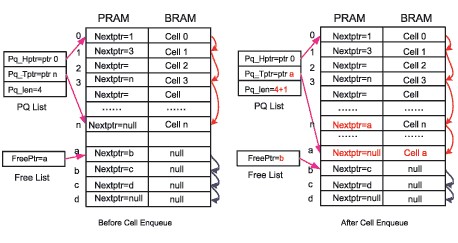
图4 BM模块的写入操作
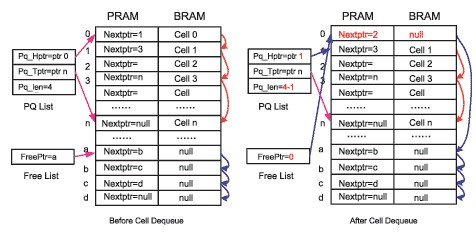
图5 读出操作的Free List堆栈结构
BM模块的读取操作由Read Control模块发起完成,当有数据单元需要读出,相应的数据单元地址则需要回收进入空闲地址队列Free List。对于不同的系统需求,空闲地址队列Free List有不同的形式。比较简单的操作是将Free List作为堆栈形式使用。
Read Control模块由PQ List的首地址0读出相应的BRAM中的内容,同时读出PRAM中对应的下一跳地址1,更新地址1为新的首地址。Free List将首指针a更新为刚释放的地址0,同时地址0中写入下一跳指针a。这样一次BRAM的读出操作需要一次PRAM的读取操作及一次PRAM的写入操作。
作为堆栈形式的空闲地址队列在实际操作中会把一部分空闲地址队列放入片内缓冲中。这样在读BRAM释放地址进入空闲地址队列时可以节省PRAM的一次写入操作,在写BRAM时申请空闲地址时可以节省PRAM的一拍读取操作。PRAM堆栈结构下内置空闲地址队列表如图6所示。
图6 PRAM堆栈结构下内置空闲地址队列表
以图5的读出操作为例,当Read Control模块由PQ List的首地址0读出相应的BRAM中的内容,同时读出PRAM中对应的下一跳地址1,更新地址1为新的首地址。这时,地址0为已经释放的地址,按空闲队列的操作要求,地址0需要进入空闲地址队列中,在写操作时再将地址0读出提供给Write Control模块用于写BRAM。而基于图6的结构,地址0在被释放后不再进行更新PRAM中的空闲地址队列Free List的操作,直接写入片内缓冲中,在Write Control模块申请地址时由片内缓冲中读出提供给Write Control模块 。仅在片内Free List缓冲几乎满时,进行PRAM中的空闲地址队列Free List的更新操作,或在片内Free List缓冲空时进行PRAM中的空闲地址队列Free List的读取操作。基于图6的结构,在一个读写周期内,可以节省两次PRAM的操作,在最坏情况下也可节省一次PRAM的操作。但基于堆栈的结构,栈顶的地址被高频率的反复的调用,栈底的地址很难被使用,DRAM的工作寿命会因此受到影响。为保证DRAM的工作寿命,在有些系统中将空闲地址队列Free List做成链表形式,从而保证每个DRAM的存储空间都能被平均的使用。读出操作的Free Lis链表结构如图7所示。
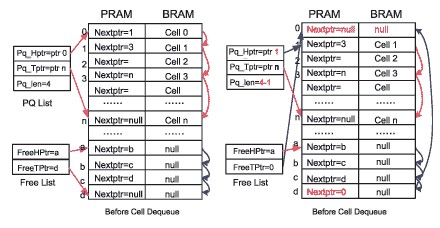
图7 读出操作的Free Lis链表结构
Read Control模块由PQ List的首地址0读出相应的BRAM中的内容,同时读出PRAM中对应的下一跳地址1,更新地址1为新的首地址。
Free List相对于堆栈模式增加尾指针d。Free List在回收地址时维持首指针a不变,将尾指针d更新为刚释放的地址0,同时地址d中写入下一跳指针0。这样一次BRAM的读出操作同样需要一次PRAM的读取操作及一次PRAM的写入操作。对于链表方式的空闲地址队列Free List,在每个读、写周期必须进行两次PRAM的写入操作及两次PRAM的读取操作,PRAM的效率不高。
针对两种空闲地址队列的效率及对DRAM的影响,在很多系统中采用了折中的方法,即在PRAM中使用链表方法管理空闲地址队列Free List,在片内采用堆栈模式另建一个空闲地址队列Free List,在这种情况下,每个读、写周期需要三次PRAM的操作。
在实际系统中,BRAM的带宽与PRAM的带宽一般为TM的瓶颈,PRAM主要受限于访问的次数,而BRAM受限于接口带宽。
在10G的TM系统中,片内数据总线的位宽定为128位,系统时钟定为150MHz,BCELL的大小定为64B。在这种情况下,读取操作和写入操作均为4个时钟周期。在满足10G系统的需求下,读取、写入操作周期为7个时钟周期。在前面曾计算过,在满足10G TM系统的情况下,BRAM采用64位 DDR II SDRAM,接口时钟使用250MHz即可满足数据接口的需求。PRAM采用32位ZBT SRAM ,接口时钟使用系统时钟,每个PCELL为64位,每个读、写周期需要6个时钟周期完成。在实际系统中采用Altera FPGA,BM的设计可以满足10G的TM线速工作的需求。
在40G核心网的TM系统中,片内数据总线的位宽为256位,系统时钟采用250MHz(在40GE的系统中可选用200MHz)。采用DDR II SDRAM,接口时钟使用333MHz,则192位的BRAM可以满足40G的TM需求。此时,BCELL可为96B、192B、384B,在这里选用192B。当BCELL选用192B时,读取操作和写入操作同样均为6个时钟周期。在满足40G系统的需求下,读取、写入操作周期为9个时钟周期。PRAM采用48位QDR SRAM,接口时钟使用150MHz,每个PCELL为96位,在每个读、写时钟周期内,PRAM最多可被操作5次。在采用Altera FPGA的情况下,BRAM采用192位 DDR II SDRAM,PRAM采用48位QDR SRAM,BM的设计可以满足40G的TM线速工作的需求。
-
处理器
+关注
关注
68文章
19286浏览量
229841 -
FPGA
+关注
关注
1629文章
21736浏览量
603384 -
芯片
+关注
关注
455文章
50816浏览量
423613
发布评论请先 登录
相关推荐
远程管理系统定制
适用于FPGA、GPU和ASIC系统的电源管理
适用于FPGA、GPU和ASIC系统的电源管理
如何实现定制缓冲管理?
怎么实现基于FPGA的具有流量控制机制的高速串行数据传输系统设计?
基于FPGA和IP Core的定制缓冲管理的实现

采用FPGA实现同步、帧同步系统的设计
采用FPGA与IP来实现DDR RAM控制和验证的方法





 工商网监
工商网监
评论