 实现减轻Cortex-M设备上CPU功耗的方法和技巧
实现减轻Cortex-M设备上CPU功耗的方法和技巧
1 、理解Thumb-2
首先,让我们从一个看起来并不明显的起点开始讨论节能技术—指令集。所有Cortex-M CPU都使用Thumb-2指令集,它融合了32位ARM指令集和16位Thumb指令集,并且为原始性能和整体代码大小提供了灵活的解决方案。在Cortex-M内核上一个典型的Thumb-2应用程序与完全采用ARM指令完成的相同功能应用程序相比,代码大小减小到25%之内,而执行效率达到90%(当针对运行时间进行优化后)。
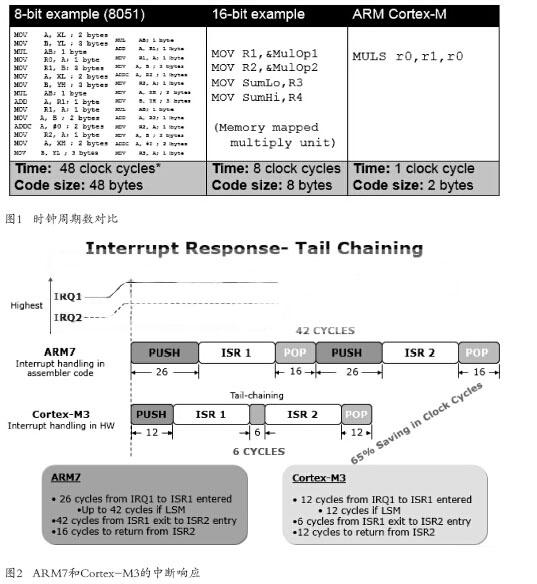
Thumb-2中包含了许多功能强大的指令,能够有效减少基础运算所需的时钟周期数。减少时钟周期数意味着现在你能够以更少的CPU功耗完成手头的工作。例如,假设要完成一个16位乘法运算(如图1所示)。在一个8位8051内核的MCU上执行这个运算将需要48个时钟周期,并占用48字节的Flash存储空间。使用一个16位内核的MCU(例如C166)执行相同的运算需要8个时钟周期,并占用8字节的Flash存储空间。相比之下,在使用Thumb-2指令集的Cortex-M3内核中完成相同运算仅仅需要1个时钟周期,并占用2字节的Flash存储空间。Cortex-M3内核能够通过使用更少时钟周期完成相同任务,节省了能耗;同时也能够通过占用极少的Flash存储空间,减少Flash存储器访问次数,实现最终能耗节省的目标(除此之外,更小的应用代码也使得系统可以选择更小的Flash存储器,进一步降低整体系统功耗)。
2 、中断控制器节能技术
Cortex-M架构中的中断控制器(Nested Vectored Interrupt Controller or NVIC)在降低CPU功耗方面也起着关键作用。以前的ARM7-TDMI需要“多达”42个时钟周期,Cortex-M3 NVIC从中断请求发生到执行中断处理代码仅需要12个时钟周期的转换时间,这显然提高了CPU执行效率,降低了CPU时间浪费。除了更快进入中断处理程序之外,NVIC也使得中断之间切换更加高效。
在ARM7-TDMI内核实现中,需要先花费数个时钟周期从中断处理程序返回主程序,然后再进入到下一个中断处理程序中,中断服务程序之间的“入栈和出栈(push-and-pop)”操作就要消耗多达42个时钟周期。而Cortex-M NVIC采用更有效的方法实现相同任务,被称为“末尾连锁(tail-chaining)”。这种方法使用仅需6个时钟周期处理就能得到允许,进入下一个中断服务程序的所需信息。采用末尾连锁,不需要进行完整的入栈和出栈循环,这使得管理中断过程所需的时钟周期数减少65%(如图2所示)。
3 、存储器节能注意事项
存储器接口和存储器加速器能够明显影响CPU功耗。代码中的分支和跳转可能会对为CPU提供指令的流水线产生刷新影响,在这种情况下CPU需要延迟几个时钟周期以等待流水线重新完成填充。在Cortex-M3或Cortex-M4内核中,CPU配备了一条3级流水线。刷新整条流水线将导致CPU延迟3个时钟周期,如果有Flash存储器等待状态发生,时间会更长,以便完成重新填充过程。这些延迟完全浪费功耗,没有任何功用。为了帮助减少延迟,Cortex-M3和M4内核包括一个被称为推测取指(Speculative Fetch)的功能,即它在流水线中对分支进行取指的同时也取指可能的分支目标。如果可能的分支目标命中,那么推测取指能够把延迟降低到1个时钟周期。虽然这个特性是有用的,但显然不够,许多Cortex-M产品供应商都增加了自己的IP以增强这个能力。
举个例子,即使在广受欢迎的ARM Cortex-M类的MCU中指令缓冲的运行方法也有不同。采用简单指令缓冲的MCU,例如来自Silicon Labs的EFM32产品,可以存储128x32(512 bytes)的目前大多数当前执行指令(通过逻辑判断请求的指令地址是否在缓冲中)。EFM32参考手册指出典型应用在这个缓冲中将有超过70%的命中率,这意味着极少的Flash存取、更快的代码执行速度和更低的整体功耗。相比之下,采用64x128位分支缓冲器的ARM MCU能够存储最初的几条指令(取决于16位或32位指令混合,每个分支最多为8条指令,最少为4条指令)。因此,分支缓冲实现能够在1个时钟周期内为命中缓冲的任何分支或跳转填充流水线,从而消除了任何CPU时钟周期延迟或浪费。两种缓冲技术与同类型没有缓冲特性的CPU相比,都提供了相当大的性能改善和功耗减少。
4 、M0+内核探究
对功耗敏感型应用来说每个nano-watt都很重要,Cortex-M0+内核是一个极好的选择。M0+基于Von-Neumann架构(而Cortex-M3和Cortex-M4内核是Harvard结构),这意味着它具有更少的门电路数量实现更低的整体功耗,并且仅仅损失极小的性能(Cortex-M0+的0.93DMIPS/MHz对比Cortex-M3/M4的1.25DMIPS/MHz)。它也使用Thumb-2指令集的更小子集(如图3所示)。几乎所有的指令都有16位的操作码(52x16位操作码和7x32位操作码;数据操作都是32位的),这使得它可以实现一些令人感兴趣的功能选项以降低CPU功耗。

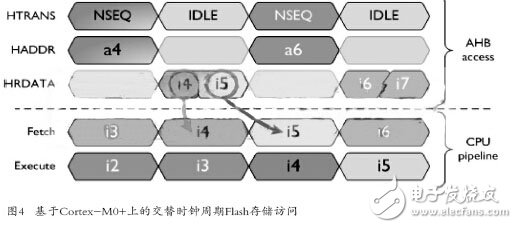
节能性功能选项首要措施就是减少Flash存储访问次数。一个主要的16位指令集意味着你可以交替时钟周期访问Flash存储器(如图4所示),并且可以在每一次Flash存储访问中为流水线获取两条指令。假设你在存储器中有两条指令并对齐成一个32位字;在指令没有对齐的情况下,Cortex-M0+将禁止剩余的一半总线以节省每一点能耗。
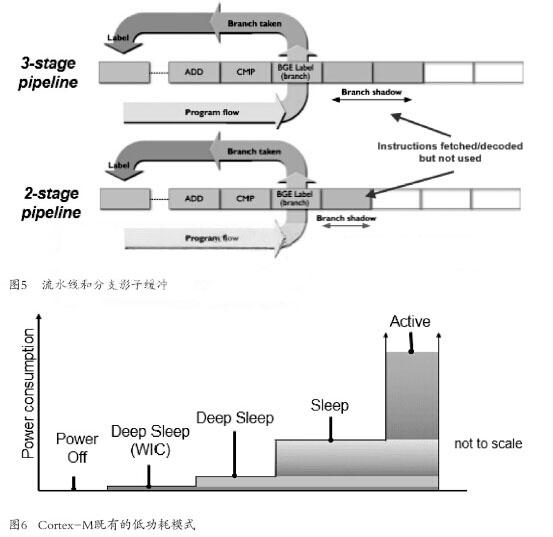
此外,Cortex-M0+内核也可以通过减少到两级流水线而降低功耗。在通常的流水线处理器中,下一条指令在CPU执行当前指令时被取出。如果程序产生分支,并且不能使用下一条取出的指令,那么被用于取指(分支影子缓冲器)的功耗就被浪费了。在两级流水线中,这个分支影子缓冲器缩小了,因此能耗得以节省(虽然仅有少量),这也意味着在发生流水线刷新时,仅需要不到一个时钟周期就能重新填充流水线(如图5所示)。
5 、利用GPIO端口节能
Cortex-M0+内核提供节能特性的另一个地方是它的高速GPIO端口。在Cortex-M3和Cortex-M4内核中,反转一位或GPIO端口的过程是“读-修改-写”一个32位寄存器。虽然Cortex-M0+也可以使用这个方法,但是它有一个专用的32位宽I/O端口,可以采用单时钟周期访问GPIO,使得它能够高效的反位/引脚反转。注意:在Cortex-M0+上,这是一个可选的特性,并不是所有供应商都具备了这个有用的GPIO特性。
6 、CPU的休眠模式
减少CPU功耗的最有效方法之一是关闭CPU自身。在Cortex-M架构中有多种不同的休眠模式,每一种都在功耗和再次执行代码的启动时间之间进行了折中考虑(如图6所示)。它也能够让CPU在完成中断服务后自动进入某个休眠模式,而不需要执行任何代码去完成这个工作。这种方法可以为那些常见于超低功耗应用中的任务节省CPU时钟周期。
在深度睡眠模式下,也可以使用唤醒中断控制器(WIC)来减轻NVIC负担。在使用WIC时,为实现低功耗模式下外部中断唤醒CPU,无需为NVIC提供时钟。
7、 自主型外设可减轻CPU负荷
自主型片上外设具有降低功耗的优点。大多数MCU供应商已经在本身产品架构中实现了外设之间的自主型交互,例如Silicon Labs的EFM32 MCU使用的外设反射系统(PRS)。自主型外设能够实现十分复杂的外设动作链(触发而不是资料传输),同时保持CPU处于休眠状态。例如使用EFM32 MCU上的PRS功能,应用能够被配置为在CPU休眠的低功耗模式下,当片上比较器检测电压值超过了其预设的门限值,则触发一个定时器去开始减数。当定时器到达0时,触发DAC去开始输出 — 所有事件发生过程中CPU可以一直保持休眠状态。
自动进行如此复杂的交互,这使得外设之间能够完成大量工作而无需CPU参与。此外,带有内建智能的外设(例如传感器接口或脉冲计数器)能够通过预设的条件用于中断唤醒CPU,例如在累积10个脉冲时中断唤醒CPU。在这个例子中,当CPU被特定中断唤醒时,它明确知道需要做什么,而不需要检查计数器或寄存器以判别发生了什么,因此可以节省相当多的时钟周期,更好的完成其他重要任务。
我们已经介绍了多种易于实现的减轻Cortex-M设备上CPU功耗的方法。当然,还有其他因素影响功耗,例如用于加工设备的处理工艺或者用于存储应用代码的存储器技术。工艺和存储技术能够显著影响运行时功耗和低功耗模式下的漏电,因此也应当纳入嵌入式开发人员的整体功耗设计考虑之中。
-
控制器
+关注
关注
112文章
16400浏览量
178549 -
存储器
+关注
关注
38文章
7514浏览量
164003 -
cpu
+关注
关注
68文章
10880浏览量
212206
发布评论请先 登录
相关推荐
ARM Cortex-M的音频性能解析
为什么说Cortex-M是低功耗应用的首选
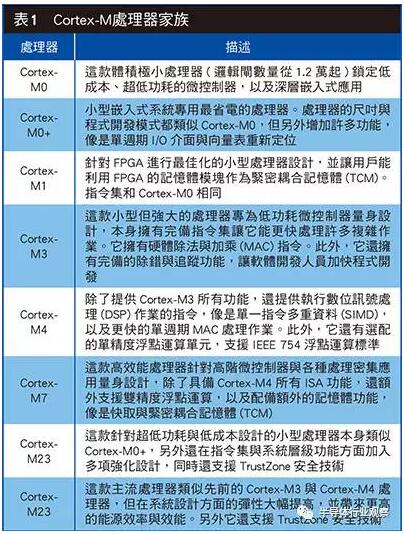
如何使用Ozone分析Cortex-M异常
你总得知道你为什么要用Cortex-M
基于Cortex-M处理器的高精度关键词识别实现
介绍Cortex-A和Cortex-M的TrustZone之间的差异
介绍易于使用的Arm Cortex-M处理器上的信号处理功能
Azure RTOS是否可用于STM32MP1设备的Cortex-M呢?
降低ARM Cortex-M CPU功耗的技巧分析

米尔科技Cortex-M Prototyping System +介绍

Cortex-M中断向量表原理及其重定向方法~

分享一下Cortex-M裸机环境下临界区保护的几种实现方法







 工商网监
工商网监
评论