 基于C55x DSP核芯片实现基带信号处理系统的设计
基于C55x DSP核芯片实现基带信号处理系统的设计
一、 引言
DSP芯片,也称数字信号处理器,是一种特别适合于进行数字信号处理的微处理器。我们在进行产品的开发过程中,往往需要对信号进行实时处理,就是指系统必须在有限的时间内对外部输入的信号完成指定的处理功能,也就是说信号处理速度应大于信号更新的速度,而DSP芯片的处理器结构、指令系统和数据流程方式,使其很容易满足实时信号处理的要求。DSP的应用几乎已遍及电子与信息的每一个领域,本文没有必要对其应用一一罗列,也不打算再花不必要的篇幅来介绍DSP的结构和原理,因为这方面的书籍和资料也较多。本文结合作者基于TI公司C5510系列DSP负责完成的某国防科研项目的基带信号处理的一点感悟,谈谈C55x系列DSP在基带信号处理中的应用和实现,因为目前介绍C54x系列DSP的资料已不少,而介绍C55x系列DSP的书籍和资料却相对太少。虽然C55x和C54x都属于TI的C5000系列的产品,很多书籍往往仅以“C54x与C55x在软件上完全兼容”来一笔代过。但对于一个DSP开发者来说,却不是这么简单的事,我们考虑的不仅仅是其功能的实现,也好考虑如何去优化和利用资源。所以有必要研究一下C55x在C54x基础上的改进功能,探讨一下C55x的应用问题。
二、 C55x与C54x比较
C54x系列是针对低功耗、高性能的高速实时信号处理而专门设计的定点DSP,广泛应用于无线通信系统中,它的CPU具有下列特征:
⑴ 采用改进的哈佛结构,一条程序总线(PB)、三条数据总线(CB、DB、EB)和四条地址总线(PAB、CAB、DAB、EAB);
⑵ 40bit的算术逻辑单元(ALU)以及一个40bit的移位器和两个40bit的累加器(A、B),支持32bit或双16bit的运算。
⑶ 17bit×17bit的硬件乘法器和一个40bit专用加法器的组合(MAC)可以在一个周期内完成乘加运算;
⑷ 比较、选择和存储等单元能够加速维特比译码的执行。
⑸ 专用的指数编码器(EXP encoder)能够在一个周期内完成累加器中40bit数值的指数运算。
⑹单独的数据地址产生单元(DAGEN)和程序地址(PAGEN)产生单元,能够同时进行三个读操作和一个些操作。
C55x通过增加功能单元,与C54x相比,其综合性能提高了5倍,而功耗仅为C54x的1/6。C55x采用变长指令以提高代码效率,增强并行机制以提高循环效率,不仅仅增加了硬件资源,也优化了资源的管理,所以性能得到了大大的提高,其处理能力可达400~800MIPS。C55x在CPU的功能单元方面作了如下扩展:
⑴ 总线增加了两条,一条读操作线(BB),一条写操作线(FB);
⑵ 乘加单元(MAC)增加了一个;
⑶ 增加了一个16bit的ALU;
⑷ 将累加器增至4个,即AC0、AC1、AC2和AC3;
⑸ 临时寄存器增至4个,即T0、T2、T2和T3;
由于结构上的变化,我们在系统设计中必须注意C55x和C54x寄存器的变化关系,尤其是当我们在C55x设计中采用与C54x的兼容模式,而不是增强模式,这更为重要。下表为C54x和C55x的寄存器对应关系。

C55x虽然也能兼容C54x,在C55x DSP上也能运行C54x的指令,但C55x与C54x又是不同的,C55x在指令上作了较大的简化。比如,相对C54x的装载(LD)与存储(ST),C55x用更加灵活易用的MOVE操作指令来实现装载和存储,将MOVE操作的范围扩大到数据交换、堆栈操作等。另外,在兼容模式中,我们要注意XC、SACCD和ARx+0等情况的使用。
三、 C5510 在基带信号处理中的应用
下面结合作者参加的某国防项目具体谈谈C5510在通信系统的基带信号处理中的应用和实现,由于篇幅所限,仅给出程序流程图,源代码略。
1.基带信号处理中DSP的任务
本系统基带信号的处理中,DSP主要完成对数据进行加扰和解扰、卷积编码和VITERBI译码、交织和解交织、成帧(或子帧)和拆帧等处理。首先,针对主传数据进行随机化加扰(采用外同步预置式,使用n=17级的m序列),再进行(2,1,7)卷积编码,约束长度K=7的卷积码,生成多项式为(用8进制表示):1+D+D^2+D^3+D^6=(171),八进制g1=171,G1=1+D^2+D^3+D^5+D^6=(133),八进制,g2=133,故每次编码前需加尾比特K-1=6位。编码后一子帧内的比特数为50(考虑了在一个大帧范围内对控制信息比特所占传输速率的补偿)。再加上每个子帧的控制信息比特(如子帧数据类型比特)后,一个子帧的有效比特数为56,然后经过7×8的分组块交织,加上8比特同步保护码,最终成为一个64bit的子帧,经缓存等处理后送给调制器。
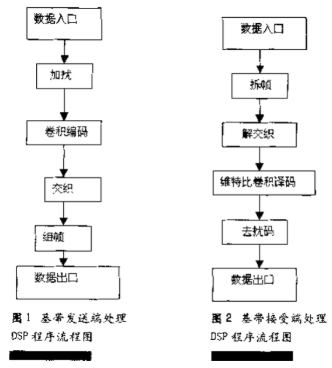
2.基于C5510基带信号处理实现
A.数据加扰与解扰
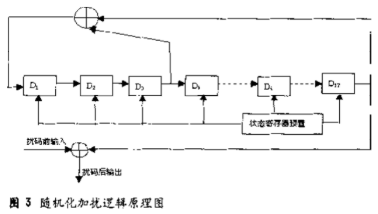
加扰使用n=17级的m序列来实现,其生成多项式的8进制表示为g=400011,多项式f(x)=x17+x3+1,有三个反馈抽头。并采用外同步预置式,减少误码扩散。每传送一个大帧(含20个子帧),触发预置式脉冲一次,脉冲预置可用软件方式实现。加扰、解扰逻辑原理如图3所示,加扰和去扰只需循环使用C55x的XOR src,dst就可以解决,因而不需详说。
B.卷积编解码
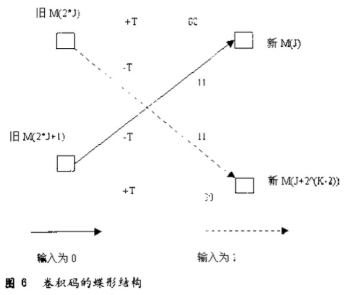
采用了性能相对比分组码好的卷积码(2,1,7),其限制长度K=7,生成多项式(8进制表示)G0=171,G1=133,自由距离df=10,渐近编码增益Gh=3.98dB。卷积码编码器的原理示意图如下图所示。
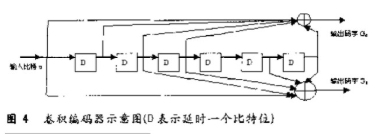
卷积编码器的输出序列是G0 G1 G0 G1 G0 G1.。..。.,在DSP C5510编程中,可以采用指令BFXPA来完成输出序列的排列这样就可以在程序中多次调用这个宏文件,从而简化和缩短源程序,具体实现时可以定义一个宏:
merge .macro src1,src2,temp,dst ;宏定义
BFXPA #5555h,src1,temp ;抽取src1偶数位置的比特位
BFXPA #0AAAAh,src2,temp ;抽取src2奇数位置的比特位
XOR temp,dst ;两者取异或运算
SFTL src1,#-8,src1 ;src1右移8位
SFTL src2,#-8,src2 ;src2也右移8位
.endm
卷积码译码采用最大似然译码器—维特比译码。其流程如图5所示。
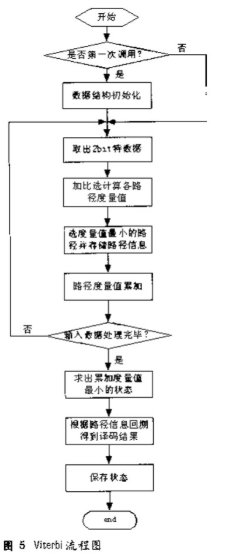
其算法思想是:
① 从时间单位j=m开始,计算进入每一状态的单个路径的部分量度并存贮量度的路径及其量度。这样的路径称为幸存路径。
② j增加1,将进入某一状态部分分量度与前一时间单元有关的幸存路径的量度相加。计算进入该状态所有路径的部分量度。对每一状态存贮具有最大量度的路径,即幸存路径及其量度,删去所有其他的路径。
③ 若j《(L+m),重复步骤②,否则就停止。此处L为码字长,m=6。
对分支度量值得计算采用软判决,也即欧氏距离,对于编码速率为1/2的卷积码,它的分支度量值为:
T=SD0 G0 (j)+ SD1 G1 (j)
为了计算的简便,Gn (j)用双极性表示,0用+1表示、1用-1表示,或相反,这样分支度量值的计算就可以简化为数据的加和减。在DSP实现过程中就可以分别用寄存器来表示:
T0: + SD0 + SD1
T1: + SD0 -SD1
在C55x中可以用特殊应用指令ADDSUB、SUBADD和MAXDIFF来完成各个状态路径度量值的累加、比较和选择,而且可以充分运用C55x的流水线处理优势。为了方便调用,可以将利用流水线处理的维特比蝶形运算定义为一个宏。
C.交织与解交织
一般的纠错编码是针对随机性错误的,但在无线信道中产生的错误多属于突发性差错,因此我们使用了交织技术,将突发性差错离散成随机差错,实际上是一种隐分集技术,可获得抗深度衰落的效果。但交织对系统会带来时延上的影响,综合考虑系统的纠错性能与复杂性,采用了一个子帧中56bit进行分组块交织的方式。如用矩阵形式处理,即在发端以行写入,收端以列读出。当然也可发端以列写入,收端以行读出。
在C55x中实现交织时,可以用AR0指向待交织数据的输入缓冲地址,AR1指向交织表,AR2指向完成交织的数据的地址。AR1每次加1,对应于AR2所指交织数据字的比特位置也加1,指向的内容是输入缓冲区的地址偏移量,此偏移量指向的比特就是需要交织到AR2指向字的比特位置。程序的重要结构相当于有两层循环,在外层循环中指针AR2每次加1,对应内层循环执行16次。去交织是交织的逆过程,需要使用相同的的交织表,程序结构也和交织大致相同,但比特搬移方向相反,因而在编程实现过程中,只需将交织程序稍加修改就可以。
四、 总结
随着DSP技术的迅猛发展,芯片集成度的提高也使DSP芯片成本降低,这使DSP的需求上升和应用领域的扩展,DSP已从军用转向民用,在整个电子信息领域得到了广泛的应用,越来越多的人开始或从事DSP的设计和研发。我们知道,现代通信系统中的数字化、宽带化、智能化和多媒体化要求都对信号的处理提出了很高的要求,一片DSP往往只能进行物理层处理,而不能完成处理控制和高层信令,因此DSP有必要与另外的处理器相结合。TI 公司将C55x DSP核与控制性能强的ARM9微处理器结合起来,推出了开放式多媒体应用平台(OMAP)。可以预计,DSP与其它微处理器的结合是DSP未来的发展方向。
责任编辑:gt
-
dsp
+关注
关注
554文章
8060浏览量
350866 -
芯片
+关注
关注
457文章
51345浏览量
428291 -
编码器
+关注
关注
45文章
3679浏览量
135406
发布评论请先 登录
相关推荐
基于DSP的图像处理系统的应用研究
TMS320C55x DSP是什么?有什么应用?
基带信号处理子系统
TDRSS基带信号处理系统的FPGA实现
DSP+FPGA实现语音基带处理系统
TMS320C55x DSP并行处理技术分析
TMS320VC55X的DSP的多通道缓冲串口(MCBSP)的详细资料概述

TMS320C55x EMIF号和DSP与各种类型的必要信号连接SDRAM的讨论

定点DSP C55x音频专用处理器嵌入式教学

基于OMAP5910双核处理器实现实时图像处理系统的应用设计






 工商网监
工商网监
评论