 实现40纳米DSP核心500MHz的频率时钟设计
实现40纳米DSP核心500MHz的频率时钟设计
在低于40纳米的超深亚微米VLSI设计中,时钟树网络在电路时序收敛、功耗、PVT变异容差和串扰噪声规避方面所起的作用要更重要得多。高性能DSP芯片会有大量关键时序路径,会要求时钟偏斜超低的全局时钟分布。两点间时钟偏斜若不合要求,特别是如果这些点间还存在数据路径的话,可能会限制时钟频率或导致功能性错误。
本文中所描述的是以500MHz时钟频率运行的DSP核心,多数时序关键路径都有超过20级的逻辑层。考虑到时钟抖动率和建立时间,满足高频需求真的是项非常具有挑战性的任务。如果使用传统时钟树设计方法,我们至多能获得全局时钟偏斜为150ps的时钟树。而在早期STA阶段,我们会发现由于时钟偏斜不平衡而导致的从-100ps到0ps的建立时序违规高达1万多条。这些均使得偏斜较低的时钟设计方法成为了一种迫切需要,而且还要求这种方法应能够改善时钟PVT变异容差并降低功耗。
用以衡量DSP时钟树分布结果质量(QOR)的参数主要有三个:一是RC分布扩展;二是插入延时扩展;三是同级延时扩展。我们将比较新时钟设计方法与传统方法,产生时钟衡量指标。
时钟设计
本文中40nm 500MHz DSP设计使用了一种可覆盖整个功能块的单节点、双相全局时钟,在这个案例下我们将其称为CLK。DSP的时钟结构如图1所示,CLK可驱动超过 5.3万的触发器,因此我们建议采用一种有效的设计方法来创建更鲁棒的低偏斜时钟。
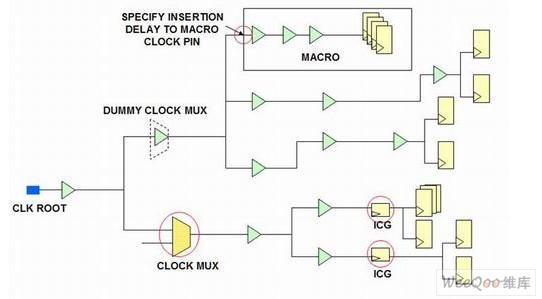
图1 DSP功能块的时钟结构
时钟缓冲器选择
驱动强度超低和超高的时钟缓冲器都是隐藏的。
隐藏超高驱动强度单元有以下优势:降低由于打开关闭高驱动单元而导致的局部时钟树功耗和动态IR违规;缩短每级时钟的有效网路长度。
隐藏超低驱动强度单元有以下优势:减少时钟树根上缓冲器总数;避免EM问题的潜在风险性。它也将带来一些劣势,比如:可能潜在地提高时钟插入延时;可能导致同样插入延时具有更高时钟树功耗(同时减轻局部动态IR降热点)。
在此我们还禁用了时钟树反相器(CTI),因为它将导致毫无差别的时钟树拓扑结构。而且我们还发现微捷码工具用来创建只有缓冲器(buffer-only)的时钟树拓扑结构会比用来创建混合型时钟树拓扑结构更有效。
时钟斜率控制
非可控性斜率违规不仅会导致时钟插入延时的增加和电学DRC违规,而且还会造成不符合通道热载流子规则的设计违规。在本文中,我们使用了以下两种方法来控制好时钟斜率:
1)限制每个时钟树单元(icg、ctb) 的扇出。
2) 在CTS过程中使用微捷码Talus命令明确定义时钟树斜率范围,当依据全局‘斜率’范围所设置的斜率范围还不如这个范围严格时则以这个范围为准。
force limit slew $m/mpin:clk -clock 250p -context $m
增强区别于微捷码自带“fix clock”的选项/方法
微捷码提供了一个名称为‘fix clock’的可预先创建时钟插入脚本。微捷码自带CTS围绕两个命令为中心:i)“run route clock”(RRC) ,创建初始时钟树;ii) “run gate clock”(RGC),调整RRC所创建的时钟树。
RRC有个默认值为2.0的隐藏选项。时钟树布线器可根据这个选项的指示,通过2.0因子超速驱动时钟单元,其效果会比根据其时序弧报告指示来得更好。虽然这个选项可能用于高驱动单元时是极为理想,但当高驱动单元处于隐藏状态时它达不到最佳结果。如果我们发现时钟树处于缓冲状态时,那可能就是出于这项功能的原因。
对该设计进行的各项实验均显示出,这种开关的最佳值为1.5。在本文中,微捷码自带CTS脚本通过编辑可加入这个隐藏的开关。
到RRC的最后,默认使用标准全局和信号布线器执行时钟布线。微捷码自带CTS中标准全局和信号布线器用于65纳米以上设计可能已足够准确,但若用于40纳米设计则还需要在RGC之前执行精确的详细布局和高强度全局布线,这样才可确保到时RGC时有准确的时序信息来调整时钟偏斜。
RGC后,建议再进行一次详细布局和高强度全局布线来完成RGC中新添加的时钟偏斜缓冲器的布局,这样才能为CTS后进一步时序优化提供必要时序信息。
时钟串扰规避
在本文中,一直使用非默认时钟网路规则来降低串扰影响。如下所示,选择较高MET层进行时钟网路布线:
rule layer preference Mn clock /sr70
rule layer preference Mn+1 clock /sr70
我们一直建议采用具有2倍宽和3倍间距的NDR(Non-default Rule)来降低耦和度。事实证实,这对PTSI有很大帮助。微捷码工具中所定义的非默认规则。这种规则只应用于MET3及更高层,同样还只应用于时钟网络中非叶级网路。
时钟分析
时钟分析是采用已开发的脚本,产生时钟树分布指标,*估时钟树的结果质量(QOR)。
RC分布扩展
RC延时分布是可用以改善设计期间时钟树鲁棒性的第一个指标。时钟树RC延时百分比等于互连线延时在每个接收端(sink)总插入延时中所占比率。
对于每个时钟网路:
%RC delay = [RC delay ]/[RC delay + Gate delay]
窄(<10%)分布意味着良好的跨角点时钟延时追踪。互连线在时钟路径占主导地位与门在时钟路径占主导地位相交叠的机率比较小。这种分析不包括数据路径时钟树。
图2显示了一种更好的RC扩展分析 。在图3中,采用了微捷码自带CTS的NOM角点RC扩展率在25%以上,而图2的则在15%左右。在图3中,MAX 角点RC扩展率在10%左右,而图2的则在5%左右。
图 2 使用新时钟设计方法的RC扩展
图3 使用微捷码自带CTS的RC扩展
插入延时扩展
插入延时分布是可用以改善设计期间时钟树鲁棒性的第二个指标。不同角点的插入延时通过使用以下方法实现w.r.t WEAK角点(QC_MAX)标准化。
1) 每个时钟接收端的插入延时是依据不同角点来计算的。称呼延时为,Di,corner
2) 一个角点的插入延时率等于每个接收端插入延时除以WEAK角点插入延时。
Ri,corner = Di,corner/Di,WEAK
3) 上述插入延时率的平均值是针对每个角点来计算。
Avgcorner= ∑iRi,corner/N, 在此N系指接收端的数量
4) 每个接收端的插入延时率等于每个角点平均率的标准值。
NRi,corner=Ri,corner/Avgcorner
5) 现在,{NRi,corner}的划分如图4和图5所示。WEAK角点结构位于y=1这一条直线。
图4显示了一个50ps的较低扩展,这意味着更好的跨角点延时追踪。在图5中,微捷码自带CTS结果显示了超过150ps的较高扩展。
图4使用新时钟设计方法的插入延时扩展
图5使用微捷码自带CTS的插入延时扩展
同级延时扩展
同级延时分布是可用以*估设计期间时钟树鲁棒性的第三个指标。它是通过以下程序进行计算:
1)对于每个接收端,让Di,corner 作为插入延时,让Li 作为时钟树深度。
2) 每个接收端平均级延时为
Si,corner=Di,corner/Li
级被定义为一个缓冲器和其驱动的互连线。
3) 计算所有“平均级延时”的全局平均值,
ESDcorner= ∑iSi,corner/N
4) 计算同级延时,
ESi,corner=Di,corner/ESDcorner
5) 理想上,每个接收端应可跨角点地拥有同等的级数,例如,对于接收端j,
ESj,corner1=ESj,corner2=…
图6和图7所展示的例子是相同级数以及两种实现方式的扩展。在图6中,ESD扩展拥有从18到23的一种更好分布。在图7中,微捷码自带CTS结果显示了从27到37的一种分布。
图6使用新时钟设计方法的 ESD扩展
图7使用微捷码自带CTS的ESD扩展
新时钟设计方法已经实施于40纳米DSP核心。事实证明,使用这种方法的CTS单元门数要比使用微捷码自带CTS工具的少了17%。鲁棒性低偏斜时钟树分布现已成功实现。实验结果显示,新设计方法在降低保持缓冲器门数方面可起到很好效果。同时这种设计方法还可用于H-tree时钟结构。未来工作中,我们还将部署更多分析来改善功耗。
-
dsp
+关注
关注
553文章
7984浏览量
348703 -
时钟
+关注
关注
10文章
1733浏览量
131442 -
触发器
+关注
关注
14文章
2000浏览量
61125
发布评论请先 登录
相关推荐
请问ADC08500差分输入时钟可以大于500MHZ吗 ?
为什么ADS5402的采样频率与输入时钟频率范围不一样?
用于仪表的500MHz时钟合成器评估板AD9911 PCB
请问有什么办法可以使Spartan 6 PLL 500MHz时钟供内部使用?
用于SY89533L 33至500MHz高速时钟合成器的评估板
用于SY89532L 33至500MHz高速时钟合成器的评估板
如何读取源同步DDR数据与500MHz时钟?
EL5462 pdf datasheet (500MHz L
EL5462 pdf datasheet (500MHz L
EL8302 pdf datasheet (500MHz R
DC696A LT5546EUF | 具有VGA和I/Q解调器和宽基带带宽的500MHz IF接收器

Tektronix DPO7054数字示波器500MHz






 工商网监
工商网监
评论