 利用牌照区域灰度变化频率的方法对车牌定位
利用牌照区域灰度变化频率的方法对车牌定位
车牌识别(LPR)技术是计算机视觉、图像处理技术与模式识别技术的融合,是智能交通系统中一项非常重要的技术。一般说来,车牌识别前期的处理技术至关重要,其前期技术包括:车牌的定位、车牌图像的二值化及字符分割。本文主要针对车牌定位算法进行研究。
车牌定位就是在车辆图像中定位牌照区域的位置。由于车辆图像都采集于自然环境中,而在自然环境中车牌和背景的成像条件一般是不可控制的,随机变化的因素(尤其是光照条件)和复杂的背景信息给目标搜索带来巨大困难。不同光照下,车牌的颜色、亮度、明蝉对比度都有很大变化;背景信息通常比车牌信息更加复杂,某些背景区域可能与车牌区域差异不大;再加上摄像距离、角度的不同,要从种种干扰中区别出目标是十分困难的。而车牌区域在整幅图像中所占的比例较小,要从整幅图像中定位车牌区域必然要在大量的背景信息中搜索,而且由于应用的特殊性,要求快速、准确地完成车牌定位。如果没有高效率的搜索方法,就需要耗费很多计算时间和存储空间。所以车牌定位技术一直以来是一个难点,是车牌识别系统的一个关键技术环节。
目前,已经提出了很多车牌定位的方法这些方法都具有一个共同的出发点即通过牌照区域的特征来判断牌照。根据不同的实现方法,大致可以把现有的定位方法分为两类:直接法、间接法。
(1)直接法:直接分析图像的特征。例如,文献提出一种基于线模板的二值化图像中的角检测算法。该算法利用车牌的边框角点,检测车牌的四个角点,并以此来定位车牌。文件介绍一种基于直线边缘识别的图像区域定位算法,并且利用该算法定位车牌的边框线,以此定位车牌。文件介绍利用车牌的尺寸、字符间距、字符特征等纹理特征定位车牌。文件利用车牌部分垂直高频丰富的特点先利用小波提取图像的垂直高频信息,然后利用数学形态学方法对小波分解后的细节图像进行一系列的形态运算,进一步消除无用的信息和噪声,以定位车牌。
(2)间接法:主要是指利用神经网络法或者遗传算法定位车牌的方法。利用神经网络和遗传算法等柔性方法进行计算是当前研究热点之一。文献提出利用BP神经网络定位车牌,文件提出利用DTCNN(Discrete-Time Cellular Neural Network)和模糊逻辑结合的方法。文献利用多层感知器网络(MLPN)对车牌进行定位。文献提出利用遗传算法定位车牌,它利用遗传算法对图像进行优化搜索,结合区域特征矢量构造的适应度函数,最终寻找到车牌的版照区域的最佳定位参量。
通过分析和观测得知,与汽车图像中其他区域相比,车牌区域主要有以下特征:
(1)车牌字符区域中的垂直边缘较水平边缘相对密集,而车身其他部分(如保险杠等)的水平边缘明显,垂直边缘较少。另外,车牌一般悬挂在车身上较低的位置,其下方基本上没有明显的边缘密集区域。
(2)有明显的边框,在其内部规则地排列着一系列的省名缩写(汉字)、地区代号(英文字母)和5位字母/数字编号(普通民用车辆)。底牌与字符的颜色主要有蓝底白字、黄底黑字、黑底白字和白底黑字(或红字)四种。随拍摄角度和车牌自身污损程度的不同,所采集到的车牌边框经常出现倾斜、断裂等现象。
因此直接定位法是利用边框特性(利用特征2)以模模匹配的方法寻找牌照的四个角来定位或者寻找车牌边框直线定位车牌以及利用牌照区域的灰度变化频率(利用特征1)来定位。
由于车牌边框有时有污染,相对来说车牌字符区域灰度频率变化是车牌区域最稳定的特征,所以本文提出一种利用车牌字符区域灰度变化频率的方法定位车牌,即基于边缘检测和扫描线相结合的车牌定位算法。该算法的思想是首先对车牌图像进行边缘增强,再利用水平扫描线进行车牌区域的检测。
1、 车牌定位的预处理
图像预处理的作用是突出图像中的有用信息,不同的图像预处理对应于不同的图像分割以获得最佳的车牌特征。车牌定位预处理目睥是突出车牌区域的特征,抑制其它无用的特征。车牌定位预处理目的是突出车牌区域的特片,抑制其它无用的特征。车牌区域的主要特征之一是垂直边缘较密集。所以本文提出增强垂直边缘的差分算子进行垂直边缘增强。
为了不失一般性,本文对灰度图像进行研究。由于本文采集的图像是彩色图像,所以要把彩色图像转化为灰度图像。为了减少不必要的彩色-灰度转化的运算,本文只对输入的彩色汽车图像的绿色分量作处理。
边缘检测的算子很多。例如:如Sobel算子、Roberts算子、Prewitt算子、Laplacian算子等。Sobel、Roberts、Prewitt、Laplacian算子都不是专门用于检测垂直边缘的,且运算量较大。虽然可以只用它们的垂直边缘检测算子,但是相对而言,运算量还是比较大。为此,本文专门设计了一个水平模板算子,即[1,1,1…,1,1,1,1]。该算子与图像进行卷积然后再与原图像作差分运算,当差分值大于某一门限值就认为它是边缘目标,否则是背景。
水平模板即[1,1,1…,1,1,1,1],它与图像进行卷积相当于图像水平方向进行低通滤波,再与原图像差分,其目的是突出图像的垂直方向的高频信息(相当于对图像进行高通滤波)。由于该算子可以做增量运算,也就是在计算局部平均值时,先计算水平方向窗口内各点之和,将前次运算的结果减去窗口最左边点的值再加上右边新一点的值。这样可以减少求和运算次数,所以其运算量比Sobel算子少。
算子描述如下:
1/n[111.。.1111]-[000.。.1000] (1)
式(1)的左半部分是水平模板,即[1,1,1…,1,1,1,1]与图像进行卷积,右半部分可理解为原始图像。它们进行差分是式(1)的运算结果。
由于可以做增量运算,所以算子的长度对运算量影不大。在这里取9,其目的是与字符笔划的宽度相符。
从图1可以看出:图像进行卷积然后再与原图像作差分的数据,只有车牌区域、车轮、车灯等灰度突变处值相对较高,而其它几乎为零。通过对整幅图像的处理,得到车辆图像的二值化图像如图2(a),对差分图像进行二值化,结果如图2(b)(其中阈值取10)。

2、 车牌的预定位
2.1 长程滤波与颗粒滤波
(1)长程滤波
从图2(b)可以看出预处理后很多边缘点连接成长程带状曲线(特别是在车轮、车窗)。而车牌区域不会有这种情形。如果不作相应处理,就会给车牌定位带来干扰。因此,在定位前应当先作长程滤波。

长程滤波算法基于这样的思想:如果许多点边缀成一个长程曲线L,那么长程滤波器考察L在x方向和y方向的空域延展程度。如果超过阈值,即将所有属于L的候选点从候选点集合中滤掉。
(2)颗泣滤波
长程滤波后,图像中仍有许多候选点集结成小型的彼此分离的颗粒状,而车牌区的候选点一般不会有这种情况。由此进行了颗粒滤波处理,滤掉颗粒噪声。
由此本文定义两个模块:击不中模板、击中模板,如图3所示。只要击中模板和图像乘积大于一定阈值,而击不中模板与图像乘积小于一定阈值就把击中模板内的图像全置为零。
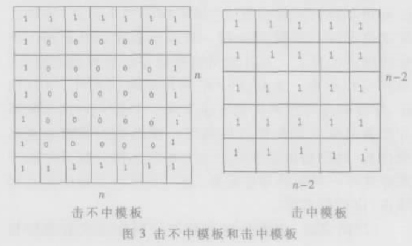
颗粒滤波基于这样的想法:对于某一个候选点颗粒状集合,在它周围一定存在一个小矩形区(矩形区的大小与所考察的颗粒粒度有关),这个小矩形区的四周,包含非常少的候选点(理想情况是没有候选点)。那么,对全图进行小矩形区扫描,检查矩形区周边上的候选点个数是否小于阈值。如果小于,则认为该矩形区内的所有候选点形成了孤立的颗粒状命令,抹去这些点,就达到了颗粒滤波的目的。由于颗粒大小不一,可以进行若干次不同粒度的颗粒消抹。对图2(b)进行长程滤波与颗粒滤波后的处理结果如图4所示。

2.2 车牌的预定位
本文利用了车牌字符的连续特性。车牌区域有连续7个字符,而且字符与字符之间的距离在一定范围内。本文定义从目标到背景或者从背景到目标为一个跳变。牌照区域相对于其它非车牌区域跳变多,而且间距在一定范围内和跳变次数大于一定次数。通常为14以上,因为车牌中今有7个字符,每个字符有两个以上跳变,为了防止字符的断裂、模糊、车牌倾斜等的影响,本文保守起见采用10。
因此本文扫描线在二值化图像中扫描定位车牌(一般来说车牌都在车辆的下部,与车牌文字类似的文字干扰大多在上部),采用从左到右、从下到上的顺序扫描。算法如下:
从下到上的顺序扫描,对图像的每一行进行从右向左的扫描。
(1)碰到跳变点记录下当前位置,如果某行有连续10个跳变点以上,并且前一个跳变和后一个跳变点的距离在一定范围内,就记录下起始占烽终止点位置。
(2)如果连续有十行以下这样的跳变点,并且相邻上下行的起始点和终止点相邻。就认为该区域是车牌预选区域。图5显示一幅典型的车辆图像的定位结果图。

从定位结果看,本定位算法还适合车辆图像中包含多车牌的情况,而且定位速度受多车牌影不大。虽然车灯和车上的字符(包括车牌、车灯等垂直边缘丰富的区域,以及缴费车牌等)也可能定位为预选区域,但是由于它们大都在车牌的上方,本文又采用从下而上的方式对预选区域进行筛选,所以对定位速度影响不大。在99%以上的情况下遇到的的第一个预选区域是车牌区域如图6(a)、(c),很少有象图6(b)的情况。基于这种情况,本文这样设计定位策略:若要求实时处理,就只选取第一个预选区域,把它送入切分和识别模块;如果不要求实时性,就可以把各个预选区域分别送入切分和识别模块。同时对于2000式车牌(图6(c)),本文算法也能准确定位。对于2000式车牌中上排的字符,只能通过切分模块反馈获得车牌左右边界的进一步定位。

对大多数车辆来说车牌定位非常准确,但是对某些车牌来说,特别是货车的车牌,牌照很有可能与附近的汽车纹理轮廓的某些区域发生了粘连,所有这些区域均构成了候选牌照区。因此为提取正确车牌区域,必须设法去除虚假候选牌照区,从粘连的候选牌照区和复合块中分离出真正的牌照区。在实际场景中,用上述算法预选的区域粘连都是与车牌左右两边的一些纹理轮廓粘连,几乎不与车牌上下部分粘连(由于算法只利用垂直边缘),所以前面定位的预选区域的高度就可以近似为车牌的高度,可以依据车牌的先验知识,根据牌照字符高宽比,可估计出牌照字符宽度CharWidth。在此可能参看文献的算法。该算法通过牌照字符度估计出牌照宽度Platewidth(对于普通车牌一般取10CharWidth),同时根据牌照区图像的垂直边缘图在牌照字符处高度集中,而在其他地方相对分散的纹理特征和估计出的牌照宽度来自动搜索牌照字符区域所在的位置,即真正车牌区域边缘向下投影为最大。具体步骤可参看文献。
采用该方法对图7进行了牌照左右边界确定,结果如图8所示。白色矩形框,是车牌的预选区域。可以看出其车牌与车灯粘连,根据预定位的长度比大于一定数值,就认为车牌和车灯等区域粘连。运行上述算法,进一步确定车牌左右边界。结果如图8所示。

3、 实验结果
部分车辆图像定位结果如图9所示。

结果分析:
①准确性:实验结果表明车牌定位的准确性大于99%,车牌定位的区域在外界有干扰以及车牌倾斜时比车牌稍大。
②时间特性:根据车牌情况不同在VC环境下运行时间在0.1到0.15秒之间(128M内存PIII 733)。
③适应性:车牌的噪声对定位没有影响,在光照很强和光照很弱的情况下,都能提取出车牌的图像。但对于车牌严重腿色的情况,由于检测不到笔画等的边缘会导致定位失败。
④其它特性:本定位算法适合车辆图像中包含多车牌的情况,而且定位速度受多车牌影响不大(同时也可能出现定位错误的区域和车灯等垂直边缘丰富的区域以及缴费车牌区域等,这可以在以后的切分和识别模块进行抛弃)。
责任编辑:gt
-
神经网络
+关注
关注
42文章
4762浏览量
100521 -
计算机
+关注
关注
19文章
7412浏览量
87693 -
频率
+关注
关注
4文章
1438浏览量
59145
发布评论请先 登录
相关推荐
基于纹理和颜色的模糊车牌的增强与定位


多种特征的车牌定位算法
如何使用机器视觉实现汽车牌照的识别






 工商网监
工商网监
评论