 今年Hot Chips大会上的一些有趣的讨论
今年Hot Chips大会上的一些有趣的讨论
今年夏天,全球芯片领域的年度大事——Hot Chips大会,一共举办了25场会议,其中有16场或多或少都聚焦于处理人工智能(AI)任务的芯片上。这些芯片应用涉及范围广泛,从瞄准物联网(IoT)和智能手机的超低功耗组件,到数据中心所需的高耗电芯片等。
曾经围绕着x86架构的产业整并,使得这一微处理器年度盛事有好几年变得不那么有趣。而今,随着机器学习的崛起,Hot Chips再度成为专注于芯片架构的工程师热烈参与的年度盛会。
不管你相不相信,芯片业近来关注的重点并不只是深度学习。例如,大会中的一位发言人还介绍了可能取代DRAM的竞争方案,并呼吁探讨更多关于内存技术的话题。
赛灵思(Xilinx)展示了一款针对AI打造的全新FPGA变化版本,并邀请与会者针对基于安全的全新运算架构展开设计移动。
Alphabet董事长John Hennessey在发表专题演讲时指出,在Google计算机架构师发现安全漏洞之前,业界广泛使用的推测执行(speculative execution)技术易于遭受旁路攻击(side-channel attack)的情况已经存在长达20年了。
Insight64分析师Nathan Brookwood说:“这不禁令人怀疑还有什么是我们以往没有注意到的......鉴于这些产品如此复杂却仍能有效作业,这一点真的令人惊讶。”。
接下来,我们将重点介绍在今年Hot Chips大会上的一些有趣的讨论。我们将从其中一些令人印象深刻的创新想法和目标设计开始谈起。
新创公司Tachyum挑战Xeon
新创公司Tachyum无疑是其中最具有胆识的,但却并不被看好。该公司的目标在于透过其Prodigy芯片,从而在主流服务器(server)用处理器和AI加速器市场分一杯羹。Tachyum宣称其Prodigy芯片的核心“比英特尔(Intel)的Xeon更快,也比Arm核心更小”。
该公司表示,这款7纳米(nm) 290 mm2芯片支持多达64个核心,可在4GHz执行频率下提供高达2TFlops的运算效能,预计明年出样。
事实上,如果没有重大的性能升级以及经过多方测试,数据中心营运商不太可能在其x86架构中采用新创公司的芯片和软件。因此,分析师Brookwood对于Tachyum采用超长指令字(VLIW)架构抱持怀疑态度,毕竟这是英特尔在其Itanium中未能完美掌握的技术。他补充说,如果该芯片能取得任何市场吸引力,Tachyum很可能面临来自英特尔等巨擘的专利诉讼。
Tachyum的Prodigy芯片支持九阶整数和14阶浮点运算管线架构(本文图片来源:Hot Chips)
Optane引发法规争议?
英特尔描述其最新的14nm Xeon服务器处理器Cascade Lake。该公司在不久前的一场活动中才发布这款芯片,但在Hot Chips大会上提供了更多细节,但也引发一些争议。
Cascade Lake采用与英特尔现有14nm Xeon相同的机制、散热和插槽接口,也支持相同的核心数、快取结构以及I/O速度。新增部份包括微调14nm工艺,以提高一点性能和降低一些功耗。此外,该芯片还支持新的AI指令和硬件,以避免暴露于Meltdown/Spectre的旁路通道攻击。
但其重点在于,Cascade Lakes是第一款带有内存控制器的Xeon,可支持Intel Optane (即3D XPoint内存),可为每插槽提供高达3TB主存储器以及带来超越DRAM的读/写速度。
介绍该新产品的英特尔工程师并未评论Optane的耐用性。然而,他表示,这些主板使用的Jedec DDR4电气总线采用英特尔的专有协议,这已能让竞争对手近期内都望尘莫及。
Brookwood说:“我认为这并不至于构成法律挑战。”
“如果我是IBM或AMD,当Optane DIMM普及于数据中心而我却无法取得时,那么我可能会要大发牢骚了!英特尔占据了98%的服务器市场,在我看来,这就是一种垄断。”
英特尔目前正主导储存网络产业协会(SNIA),为Optane等替代主流内存打造软件平台
NEC加速器低价挑战Nvidia V100
NEC描述一款新的向量引擎,可搭载PCIe Gen 3板卡,而功耗还不到200W。该芯片专为搭配SX-Aurora超级计算机与Linux服务器中的x86主机而设计,据称其价格要比Nvidia V100更低得多。
NEC声称其向量芯片可提供高达307GFlops的双精度性能。在大多数基准检验下,其性能可介于Xeon和V100二者之间。该公司还指出,NEC芯片的内存带宽略高,而且在一些工作负载上的性能功耗比几乎相当于Nvidia GPU。
相较于Nvidia V100芯片尺寸约840 mm2,NEC的1.6GHz、16nm向量芯片尺寸相对较小——480-mm2。此外,NEC的芯片支持多达6个Hi8或Hi4 HBM2内存堆栈,可提供高达48GB的总内存容量。
为IoT打造超低功耗AI加速器
美国哈佛大学(Harvard University)和Arm的研究人员连手发表一种用于物联网中执行深度学习任务的超低功耗加速器。这款所谓的SMIV芯片采用台积电(TSMC) 16-nm FFC工艺打造,芯片尺寸约为25 mm2。
SMIV可说是使用Arm Cortex-A核心的首款学术界开发芯片。它在always-on的加速器丛集中使用近阈值操作,并透过嵌入式FPGA模块提供大约80个硬件MAC和44Kbits RAM。
因此,该芯片能以低功率提供更高精确度。同时,相较于竞争方案,它的功率和面积效率都提高了近10倍。
MIT打造更低功耗导航芯片
美国麻省理工学院(MIT)的研究人员则为机器人和无人机打造了一款客制设计的导航芯片,据称该芯片的功耗较Arm CPU核心更低。这款Navion导航芯片采用65nm CMOS制造,在20-mm2芯片面积上打造视觉惯性测距引擎。
研究人员称,该芯片的性能是标准CPU的2倍至3倍,并可缩减多达5.4倍的内存占用空间。它在最大配置下的功耗为24mW,而在优化配置时的功耗仅2mW,而仍能实现实时导航。
在Hot Chips大会的多场会议中只针对已发布的组件(有的甚至都已经出货)提供较多细节。接下来我们将先介绍用于客户端系统的AI加速器和CPU,并将关注焦点转向服务器处理器和加速器。
Arm展示新款机器学习核心实力
Arm深入探讨其预计将在年底出现在芯片中的机器学习核心。新款机器学习核心可在1GHz提供约4TOPS运算性能,以及在以7nm制造的2.5-mm2核心上提供超过3TOPS/W性能。其乘法累加单元支持8个16位宽点乘积。
Arm介绍其机器学习核心上的8 x 8区块压缩
三星举例说明聪明的工程师如何在工艺技术进展趋缓时显著提升性能。因此,从一系列基准检验来看,目前在其智能手机中使用的2.7GHz M3应用处理器,轻轻松松地就能超越前一代M2至少50%以上。
这项进展来自于在其分支预测器中使用神经网络,以及利用德州农工大学(Texas A&M )教授Daniel A. Jiménez的学术研究成果。不过,M3应用处理器的芯片尺寸是M2的2倍以上,但采用了10 LPP工艺——这是三星10 LPE工艺的微幅升级。
Mythic展示内存处理器最新进展
Mythic描述其内存处理器(PIM)设计细节,它可用于处理具有0.5 picojoules/MAC的深度学习影像。该芯片设计针对监控和工厂相机,功耗约为5W,包括所有数字控制逻辑。
PIM概念已出现多年了,但一直到最近才被应用于AI。Mythic打造基于NOR单元的可变电阻器数组,但并不在内存单元写入和读取深度学习权重。相反地,它将电压施加到数组线,以求和并读取电流级,进一步达到省电的效果。
初始芯片可处理有限数量的权重,但基于砖式(tile)的设计可为全标线芯片扩展多达5倍权重。此外,还可以添加Arm核心以创建可编程组件,而且多个芯片间可以协同工作以执行更大的应用程序(app)或更快地执行。但缺点之一在于无法利用神经网络的稀疏特性。
Mythic声称,这款40nm芯片的功耗只有GPU的一小部份。该公司预计明年年中提供样片,并预计于2019年底量产。
Mythic的PIM目的在于以MCU功率提供GPU性能,而不至于影响稀疏神经网络
Google侧写Pixel Visual Core
Google介绍在其最新智能手机中的Pixel Visual Core。这款基于A53的可编程引擎,专为手机摄影机执行目前仍在发展中的最新版HDR +算法。一位Google工程师打趣地说:“它能让你的社交媒体图片看来不会太糟糕。”
有趣的是,三星内存部门的一位工程师问道,未来世代是否会放弃典型的图像处理管线,转而采用新兴的深度学习技术?Google工程师回复说:“但我们还没在这个领域发布太多AI算法啊!”
Google声称其28nm Pixel核心执行HDR+作业的速度比10nm移动应用处理器的CPU快至少2.8倍
IBM强化Power 9服务器系统
针对服务器领域,IBM与英特尔似乎都在14nm节点停摆一段时间了。IBM这次在Hot Chips介绍其最新的计划,为基于其Power 9处理器的系统强化I/O和内存带宽,不过,至少要到2020年或之后才会针对新工艺提供新设计了。
IBM的目标是在其Power 9服务器上发掘更多内存带宽,同时为基于7-nm处理器的设计做好准备
富士通将Arm核心带入超级计算机
富士通(Fujitsu)描述了7-nm A64FX,其设计目标在于成为超级计算机中的首批Arm核心之一。该512位SIMD芯片为Arm架构带来向量扩展,以执行传统的超级运算和新的AI任务。52核心的芯片使用32GB HBM2内存,可提供2.7TFlops性能和1,024GB/s的内存带宽。
富士通的首款post-Sparc设计A64FX,瞄准用于将在2021年发表的日本新一代Post-K超级计算机
Nvidia展示其GPU服务器实力
Nvidia透过其DGX-2及其内部NVLink互连,从芯片进一步扩展到系统。该公司展示了几项基准检验,包括以DGX-2展现超越标准双GPU系统的性能。
英特尔、AMD以及…中东和平?
英特尔介绍如何使用其嵌入式多芯片互连桥接(EMIB)技术,将其Kaby Lake桌上型x86 CPU与AMD Radeon RX Vega M GPU连接在一个模块(下图)中,以用于轻薄型笔记本电脑。
分析师Brookwood还与英特尔主讲人开玩笑说,“不管是谁来谈成这项协议的,接下来应该可以派他去进行中东和平的任务。“
-
芯片
+关注
关注
455文章
50771浏览量
423406 -
物联网
+关注
关注
2909文章
44608浏览量
373081 -
机器学习
+关注
关注
66文章
8414浏览量
132606
原文标题:Hot Chips 2018大会上13款最“热”芯片
文章出处:【微信号:FPGAer_Club,微信公众号:FPGAer俱乐部】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
分享一些常见的电路

NVIDIA生成式AI闪耀CNCC2024大会

谷歌Wear OS智能手表更新一览
OpenAI硬件负责人热议AI基础设施扩展与节能方案
英特尔至强6系列处理器:全能核心,满足各种工作需求
NVIDIA 在 Hot Chips 大会展示提升数据中心性能和能效的创新技术

泰晶科技亮相2024年世界移动通信大会上海
新华三集团闪耀2024世界移动通信大会上海站
中国移动杨杰在2024年世界移动通信大会上展望数智化革命
芯讯通亮相2024 MWC世界移动通信大会上海展
亚马逊云科技在re:Inforce 2024全球大会上推出众多安全服务新功能
86box开发板在出厂测试固件下ui界面无法语音唤醒控制是什么情况?
主流GPU/TPU集群组网方案深度解析
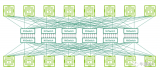
GPU/TPU集群网络组网间的连接方式





 工商网监
工商网监
评论