 如何提高生成器G样本质量的新方法
如何提高生成器G样本质量的新方法

最近,生成模型的快速发展引起了广泛的关注,尤其是由Goodfellow等人发明的生成对抗网络(GANs),其所建立的学习框架就像老顽童的“左右互搏术”,由生成器G和判别器D组成,两者在博弈过程中扮演着不同角色。
对于给定训练数据Dt,生成器G的目的就是创建与训练数据Dt具有相同概率分布的样本。判别器D属于常见的二分类器,主要负责两个工作。 首先,它要判别输入究竟是来自真实的数据分布(Dt)还是生成器;此外,判别器通过反传梯度指导生成器G创造更逼真的样本,这也是生成器G优化其模型参数的唯一途径。在博弈过程中,生成器G将随机噪声作为输入并生成样本图像Gsample,要使判别器D以为这是来自真实训练集Dt的判断概率最大化。
训练期间,判别器D的一半时间将训练集Dt的图像作为输入,另一半时间将生成器得到的图像Gsample作为输入。训练判别器D要能最大化分类正确的概率,能够区分来自训练集的真实图像和来自生成器的假样本。最后,希望博弈最终能达到平衡——纳什均衡。
所以,生成器G要能使得生成的概率分布和真实数据分布尽量接近,这样判别器D就无法区分真实或假冒的样本。
在过去的几年中,GANs已经被用于许多不同的应用,包括:生成合成数据,图像素描,半监督学习,超分辨率和文本到图像生成。然而,大部分关于GANs的工作都集中在开发稳定的训练技术上。的确,我们都知道GANs在训练期间是不稳定的,并且对超参数的选择十分敏感。本文将简要介绍目前GANs前沿技术,关于如何提高生成器G样本质量的新方法。
卷积生成对抗网络
深度卷积生成对抗网络(DCGAN)为GANs能够成功用于图像生成迈进了一大步。它属于ConvNets家族的一员,利用一些结构约束使得GANs的训练更稳定。在DCGAN中,生成器G由一系列转置卷积算子组成,对于输入的随机噪声向量z,通过逐渐增加和减少特征的空间维度,对其进行变换。
使用DCNNs进行无监督表示学习的网络结构示意图
DCGAN引入了一系列网络结构来帮助GAN训练更稳定,它使用带步幅的卷积而不是池化层。此外,它对生成器和判别器都使用BatchNorm,生成器中使用的是ReLU和Tanh激活函数,而判别器中使用Leaky ReLU激活函数。下面,我们来具体看一下:
BatchNorm是为了将层输入的特征进行规范化,使其具备零均值和单位方差的特性。BatchNorm对于网络训练是至关重要的,它可以让层数更深的模型工作正常而不会发生模式崩塌。模式崩塌是指生成器G创建的样本具有非常低的多样性,换句话说就是生成器G对于不同的输入信号都返回相同的样本。此外,BatchNorm有助于处理由于参数初始化不良引起的问题。
此外,DCGAN在判别器网络中使用Leaky ReLU激活函数。与常规ReLU函数不同,Leaky ReLU不会把所有的负值都置零,而是除以一个比例,这样就能传递一些很小的负的梯度信号,从而使判别器中更多的非零梯度进入生成器。
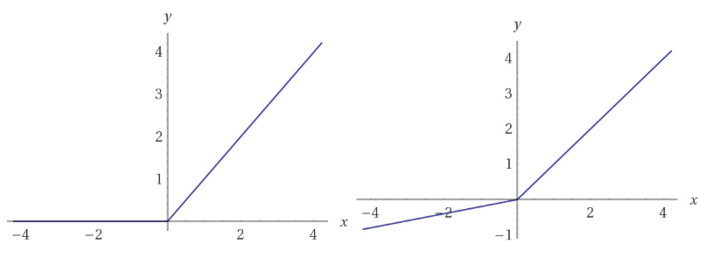
ReLU函数(左),Leaky ReLU(右),与ReLU不同,Leaky ReLU函数对于x轴左侧的负值导数不为零。
DCGAN这样的网络结构目前仍被广泛应用,但大部分的工作都集中在如何使GAN训练更加稳定。
1.基于自注意力的生成对抗网络
自注意力生成对抗网络(Self-Attention for Generative Adversarial Networks,SAGAN)是这种类型的网络之一。近来,基于注意力的方法已经被成功用于机器翻译等问题上。 自注意力GANs具有特殊的网络结构,使得生成器G能够建模长程依赖关系,核心思想是使生成器G能够生成具有全局细节信息的样本。
如果我们看一下DCGAN模型会发现常规的GANs模型主要基于卷积,使用局部感受野(卷积核)来学习表征。 卷积具有很多非常好的属性,比如参数共享和平移不变性。
典型的深度卷积网络(Deep ConvNets)通过层级递进的方式来学习表征。 用于图像分类的常规ConvNets前几层中只会学到边缘和角点等简单的特征。然而ConvNets却能够使用这些简单的表征来学习到更为复杂的表征。 简而言之,ConvNets的表征学习是基于简单的特征表示,很难学习到长程依赖关系。
实际上,它可能只适用于低分辨率特征向量。问题在于,在这种粒度下,信号的损失量难以对长程细节进行建模。下面我们看一些样本图像:
使用DCNNs进行无监督表示学习的生成样本示意图
这些图像是使用DCGAN模型基于ImageNet数据集训练而生成得到的。正如自注意力GANs文章中所指出的,对于含有较少结构约束的类别,比如海洋、天空等,得到结果较好;而对于含有较多几何或结构约束的类别则容易失败,比如合成图像中狗(四足动物)的毛看起来很真实但手脚很难辨认。这是因为复杂的几何轮廓需要长程细节,卷积本身不具备这种能力,这也是注意力能发挥很好作用的地方。
所以解决这一问题的核心想法在于不局限于卷积核,要为生成器提供来自更广泛的特征空间中的信息,这样生成器G就可以生成具有可靠细节的样本。
实现
给定卷积层L一个特征输入,首先用三种不同的表示来对L进行变换。这里使用了1x1卷积对L进行卷积以获得三个特征空间:f,g和h。这一方法使用矩阵乘法来线性组合f和g计算得到注意力,并将其送入softmax层。
自注意力GANS网络示意图
最后得到的张量o是与h的线性组合,由尺度因子gamma控制缩放。 要注意,gamma从0开始,因此在训练刚开始时,gamma为零相当于把注意力层去掉了,此时网络仅依赖于常规卷积层的局部表示。然而,随着gamma接收梯度下降的更新,网络逐渐允许来自非局部域的信号通过。此外要注意的是特征向量f和g具有与h不同的维度。事实上f和g使用的卷积滤波器大小要比h小8倍。
2.谱范数(L2范数)归一化
此前,Miyato等人提出了一种称为谱范数归一化(spectral normalization ,简称SN)的方法。 简而言之,SN可约束卷积滤波器的Lipschitz常数,作者使用它来稳定判别器D网络训练。实践证明的确很有效。
然而,在训练归一化判别器D的时候存在一个基本问题。先前的工作表明,正则化判别器D会使得GAN的训练变慢。一些已有变通方法往往通过调整生成器G和判别器D之间的更新速率,使得在更新生成器G之前多更新判别器D几次。这样在更新生成器G之前,正则化判别器D可能需要五次或更多次更新。
有一种简单而有效的方法可以解决学习缓慢和更新率不平衡的问题。我们知道在GAN框架中,生成器G和判别器D是一起训练的。 基于这点,Heusel等人在GAN训练中引入了两个时间尺度的更新规则(two-timescale update rule,简称TTUR),对生成器G和判别器D使用不同的学习率。在这里,设置判别器D训练的学习率是生成器G 的四倍,分别为0.004和0.001。 较大的学习率意味着判别器D将吸收梯度信号的较大部分。较高的学习速度可以减轻正则化判别器D学习速度慢的问题。此外,这种方法也可以使得生成器G和判别器D能以相同的速率更新。事实上,我们在生成器G和判别器D之间使用的是1:1的更新间隔。
此外,文章还表明,生成器状态的好坏与GAN性能有着因果关系。鉴于此,自注意力GAN使用SN来稳定生成器网络的训练必然有助于提高GAN网络的整体性能。对于生成器G而言,谱范数归一化既可防止参数变得非常大,也可以避免多余的梯度。
实现
值得注意的是,Miyato等人引入的SN算法是迭代近似。 它定义了对于每个层W,用W的最大奇异值来对每个卷积层W正则化。但是,在每一步都用奇异值分解那就计算量太大了。所以Miyato等人使用一种被称作power iteration的方法来获得近似的最大奇异值的解。

要注意的是在训练期间,在power iteration中计算得到的ũ值会在下一次迭代中被用作u的初始值。这种策略允许算法仅经过一轮power iteration就获得非常好的估计。此外,为了归一化核权重,将它们除以当前的SN估计。
训练细节
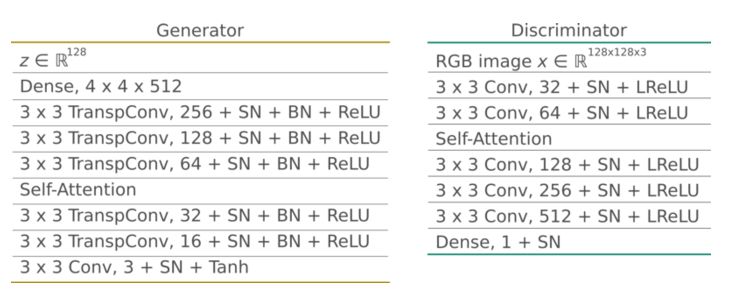
在实验中生成器G输入随机向量z并生成128x128大小的RGB图像。所有层(包括全连接层)都使用了SN。生成器G使用Batchnorm和ReLU激活函数,在中层到高层的特征图中使用了自注意力模型。与原作者实现方法一样,我们将注意力层放置在32x32大小的特征图上。
判别器D还使用谱范数归一化(所有层)。它将大小为128x128的RGB图像样本作为输入,并输出无标度的概率。它使用leaky ReLU激活函数,alpha参数设置为0.02。与生成器G一样,它在32x32大小的特征图上上也有一个自注意力层。
最终的结果如下图所示:
通过自注意力和谱归一化的方式可以实现更好的生成效果,如果你想了解更多,下面的两篇论文是不错的选择:
SAGAN: https://arxiv.org/abs/1805.08318
Spectral Normalization: https://arxiv.org/pdf/1802.05957.pdf https://openreview.net/pdf?id=B1QRgziT-
-
滤波器
+关注
关注
162文章
8469浏览量
186282 -
GaN
+关注
关注
21文章
2385浏览量
84476 -
生成器
+关注
关注
7文章
322浏览量
22803
原文标题:GAN提高生成器G样本质量新玩法:自注意力和谱范数
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
利用雷达目标生成器测试整个雷达系统的方法介绍
python生成器
基于生成器的图像分类对抗样本生成模型


python生成器是什么
TSMaster报文发送的信号生成器操作说明




评论